值的類型
當你是一隻頭腦簡單的熊,而且你在思考事情時,你偶爾會發現,在內心深處看起來非常像某件事的事物,當它公開並被其他人看到時,會變得截然不同。
A. A. Milne,《小熊維尼》
過去的幾章內容非常龐大,充滿了複雜的技術和大量的程式碼。在這一章中,只有一個新的概念需要學習,以及一些簡單的程式碼。你應得一個喘息的機會。
Lox 是動態型別的。單一變數可以在不同的時間點保存布林值、數字或字串。至少,這是概念。目前,在 clox 中,所有值都是數字。在本章結束時,它也將支援布林值和 nil。雖然這些不是超級有趣,但它們迫使我們找出我們的數值表示如何動態處理不同的類型。
18.1標記聯合
在 C 中工作的好處是我們可以從原始位元建立我們的資料結構。壞處是我們必須這樣做。C 在編譯時並沒有提供太多免費的東西,在執行時更是如此。就 C 而言,宇宙是一個未分化的位元組陣列。我們必須決定要使用多少位元組以及它們的含義。
為了選擇值的表示方式,我們需要回答兩個關鍵問題
-
我們如何表示值的類型? 如果你嘗試將數字乘以
true,我們需要在執行時偵測到該錯誤並回報它。為了做到這一點,我們需要能夠分辨值的類型是什麼。 -
我們如何儲存值本身? 我們不僅需要能夠分辨出三是一個數字,還需要知道它與數字四不同。我知道,這似乎很明顯,對吧?但我們正在一個需要將這些事情明確說明的層級上操作。
由於我們不僅在設計這個語言,而且還在自己建構它,因此在回答這兩個問題時,我們還必須牢記實作者永恆的追求:高效地完成它。
多年來,語言駭客們想出了各種巧妙的方法,盡可能將上述資訊打包到最少的位元中。現在,我們將從最簡單、經典的解決方案開始:標記聯合。一個值包含兩個部分:一個類型「標籤」,以及實際值的酬載。為了儲存值的類型,我們為虛擬機支援的每種值定義一個枚舉。
#include "common.h"
typedef enum { VAL_BOOL, VAL_NIL, VAL_NUMBER, } ValueType;
typedef double Value;
目前,我們只有幾個案例,但是當我們將字串、函式和類別新增到 clox 時,這個案例將會增加。除了類型之外,我們還需要儲存值的資料—數字的 double、布林值的 true 或 false。我們可以定義一個結構,其中包含每個可能類型的欄位。

但是這樣會浪費記憶體。一個值不可能同時是數字和布林值。因此,在任何時間點,只會使用其中一個欄位。C 允許你透過定義一個 聯合來最佳化這一點。聯合看起來像一個結構,只是它的所有欄位在記憶體中重疊。
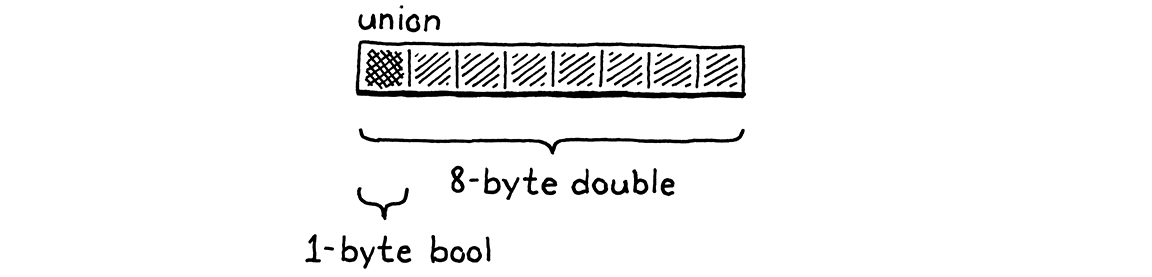
聯合的大小是其最大欄位的大小。由於欄位都重複使用相同的位元,因此你在使用它們時必須非常小心。如果你使用一個欄位儲存資料,然後使用另一個欄位存取它,你將會重新解釋基礎位元的含義。
顧名思義,「標記聯合」表示我們新的值表示將這兩個部分組合成一個結構。
} ValueType;
在枚舉 ValueType 之後新增
取代 1 行
typedef struct { ValueType type; union { bool boolean; double number; } as; } Value;
typedef struct {
有一個用於類型標籤的欄位,然後是第二個欄位,其中包含所有基礎值的聯合。在具有典型 C 編譯器的 64 位元機器上,版面配置如下所示
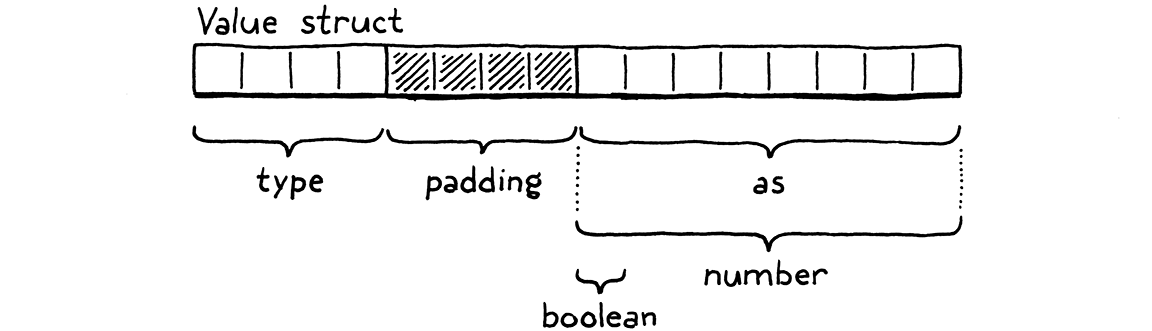
四位元組的類型標籤排在最前面,然後是聯合。大多數架構都偏好將值對齊到它們的大小。由於聯合欄位包含一個八位元組的 double,編譯器會在類型欄位後新增四個位元組的填補,以將該 double 保留在最近的八位元組邊界上。這表示我們實際上在類型標籤上花費了八個位元組,而類型標籤只需要表示零到三之間的數字。我們可以將枚舉放入較小的尺寸中,但是這樣做的唯一結果是增加填補。
因此我們的 Values 為 16 個位元組,這似乎有點大。我們稍後會改進它。同時,它們仍然小到可以儲存在 C 堆疊上並以值傳遞。Lox 的語意允許這樣,因為到目前為止我們支援的唯一類型是不可變的。如果我們將一個包含數字三的 Value 複本傳遞給某個函式,我們無需擔心呼叫者看到對值的修改。你無法「修改」三。它永遠是三。
18.2Lox 值與 C 值
這是我們新的值表示,但是我們還沒完成。目前,clox 的其餘部分假設 Value 是 double 的別名。我們有程式碼可以從一個值直接 C 轉換到另一個值。該程式碼現在都已損壞。真可悲。
使用我們新的表示法,Value 可以包含 double,但是它與 double 不等效。從一個轉換到另一個需要一個強制轉換步驟。我們需要瀏覽程式碼並插入這些轉換,以使 clox 再次運作。
我們將這些轉換實作為幾個巨集,每個類型和操作各一個。首先,將原生 C 值提升為 clox Value
} Value;
在結構 Value 之後新增
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}}) #define NIL_VAL ((Value){VAL_NIL, {.number = 0}}) #define NUMBER_VAL(value) ((Value){VAL_NUMBER, {.number = value}})
typedef struct {
這些巨集中的每一個都會採用適當類型的 C 值,並產生一個具有正確類型標籤並包含基礎值的 Value。這會將靜態型別值提升到 clox 的動態型別宇宙中。但是,為了對 Value 執行任何操作,我們需要將其解壓縮並取出 C 值。
} Value;
在結構 Value 之後新增
#define AS_BOOL(value) ((value).as.boolean) #define AS_NUMBER(value) ((value).as.number)
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}})
這些巨集朝相反的方向移動。給定一個正確類型的 Value,它們會解開它並傳回對應的原始 C 值。「正確類型」部分很重要!這些巨集會直接存取聯合欄位。如果我們要執行類似以下的操作
Value value = BOOL_VAL(true); double number = AS_NUMBER(value);
那麼我們可能會打開一個通往陰影領域的悶燒入口。除非我們知道 Value 包含適當的類型,否則使用任何 AS_ 巨集都是不安全的。為此,我們定義了最後幾個巨集來檢查 Value 的類型。
} Value;
在結構 Value 之後新增
#define IS_BOOL(value) ((value).type == VAL_BOOL) #define IS_NIL(value) ((value).type == VAL_NIL) #define IS_NUMBER(value) ((value).type == VAL_NUMBER)
#define AS_BOOL(value) ((value).as.boolean)
這些巨集在 Value 具有該類型時傳回 true。每當我們呼叫其中一個 AS_ 巨集時,我們都需要先在呼叫其中一個巨集之後保護它。有了這八個巨集,我們現在可以安全地在 Lox 的動態世界和 C 的靜態世界之間傳輸資料。
18.3動態型別數字
我們有了值的表示形式以及與其相互轉換的工具。讓 clox 再次執行所需的一切就是瀏覽程式碼並修復資料跨越該邊界的每個位置。這是本書中並非完全令人興奮的部分之一,但是我承諾會向你展示每一行程式碼,所以我們來到了這裡。
我們建立的第一個值是在編譯數字文字時產生的常數。在我們將詞位轉換為 C double 之後,我們只需將其包裝在 Value 中,然後再將其儲存在常數表中。
double value = strtod(parser.previous.start, NULL);
在 number() 中
取代 1 行
emitConstant(NUMBER_VAL(value));
}
在執行階段,我們有一個函式可以列印值。
void printValue(Value value) {
在 printValue() 中
取代 1 行
printf("%g", AS_NUMBER(value));
}
在我們將 Value 傳送到 printf() 之前,我們會將其解開並提取 double 值。我們稍後將會重新檢視此函式以新增其他類型,但我們先讓現有的程式碼運作。
18.3.1一元否定運算與執行期錯誤
下一個最簡單的運算是「一元否定」。它會從堆疊中彈出一個值,將其否定,然後將結果推回堆疊。既然我們現在有其他類型的值,我們就不能再假設運算元是數字了。使用者很可能寫出像這樣的程式碼:
print -false; // Uh...
我們需要優雅地處理這種情況,這表示現在該處理執行期錯誤了。在執行需要特定類型的運算之前,我們需要確認值確實是該類型。
對於一元否定運算,檢查看起來像這樣:
case OP_DIVIDE: BINARY_OP(/); break;
在 run() 函式中
取代 1 行
case OP_NEGATE: if (!IS_NUMBER(peek(0))) { runtimeError("Operand must be a number."); return INTERPRET_RUNTIME_ERROR; } push(NUMBER_VAL(-AS_NUMBER(pop()))); break;
case OP_RETURN: {
首先,我們檢查堆疊頂端的值是否為數字。如果不是,我們會回報執行期錯誤並停止直譯器。否則,我們繼續執行。只有在完成此驗證之後,我們才會解包運算元、否定它、包裝結果並將其推入堆疊。
為了存取 Value,我們使用一個新的小函式。
在 pop() 函式之後新增
static Value peek(int distance) { return vm.stackTop[-1 - distance]; }
它會從堆疊中傳回一個 Value,但不會彈出它。distance 參數表示要從堆疊頂端往下看多遠:零表示頂端,一表示往下一個位置,依此類推。
我們使用一個新的函式來回報執行期錯誤,我們會在本書的剩餘部分大量使用它。
在 resetStack() 函式之後新增
static void runtimeError(const char* format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fputs("\n", stderr); size_t instruction = vm.ip - vm.chunk->code - 1; int line = vm.chunk->lines[instruction]; fprintf(stderr, "[line %d] in script\n", line); resetStack(); }
你一定在 C 語言中呼叫過可變參數函式—也就是接受可變數量引數的函式—:printf() 就是一個例子。但你可能沒有定義過自己的可變參數函式。本書不是 C 語言的教學,所以這裡我會簡單帶過,但基本上 ... 和 va_list 等東西讓我們可以傳遞任意數量的引數給 runtimeError()。它會將這些引數轉發到 vfprintf(),這是 printf() 的一種變體,它接受明確的 va_list。
呼叫者可以傳遞格式字串給 runtimeError(),後面接著一些引數,就像他們直接呼叫 printf() 時一樣。然後 runtimeError() 會格式化並印出這些引數。我們在本章不會利用這一點,但後面的章節會產生包含其他格式化資料的執行期錯誤訊息。
在我們顯示希望有幫助的錯誤訊息後,我們會告訴使用者在發生錯誤時正在執行的程式碼行數。由於我們在編譯器中保留了語彙單元,我們會查詢編譯到程式碼區塊中的除錯資訊的行數。如果我們的編譯器運作正確,這會對應到產生位元組碼的原始碼行。
我們使用目前的位元組碼指令索引減一來查詢程式碼區塊的除錯行陣列。這是因為直譯器會在執行每個指令之前先跳過它。因此,在我們呼叫 runtimeError() 的時候,失敗的指令是前一個指令。
為了使用 va_list 和用於處理它的巨集,我們需要引入一個標準標頭檔。
在檔案頂端新增
#include <stdarg.h>
#include <stdio.h>
有了這些,我們的 VM 不僅可以在我們否定數字時執行正確的操作(就像我們在破壞它之前一樣),而且還可以優雅地處理嘗試否定其他類型(我們還沒有的其他類型,但仍然)的錯誤嘗試。
18.3.2二元算術運算子
我們現在有了執行期錯誤機制,所以修復二元運算子更容易了,即使它們更複雜。我們今天支援四個二元運算子:+、-、* 和 /。它們之間的唯一區別是它們使用的底層 C 運算子。為了盡量減少四個運算子之間的冗餘程式碼,我們將共同的部分包裝在一個大型前置處理器巨集中,該巨集將運算子語彙單元作為參數。
這個巨集在幾個章節之前看起來像是過度設計,但我們今天從中受益。它讓我們可以在一個地方新增必要的類型檢查和轉換。
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
在 run() 函式中
替換 6 行
#define BINARY_OP(valueType, op) \ do { \ if (!IS_NUMBER(peek(0)) || !IS_NUMBER(peek(1))) { \ runtimeError("Operands must be numbers."); \ return INTERPRET_RUNTIME_ERROR; \ } \ double b = AS_NUMBER(pop()); \ double a = AS_NUMBER(pop()); \ push(valueType(a op b)); \ } while (false)
for (;;) {
是的,我意識到這是一個巨獸般的巨集。這不是我通常認為的良好 C 語言實作,但讓我們接受它。這些變更與我們對一元否定所做的類似。首先,我們檢查兩個運算元是否都是數字。如果任何一個不是,我們會回報執行期錯誤並拉下彈射座椅拉桿。
如果運算元沒問題,我們會將它們都彈出並解包它們。然後我們套用給定的運算子、包裝結果,並將其推回堆疊。請注意,我們不會直接使用 NUMBER_VAL() 來包裝結果。相反,要使用的包裝器會作為巨集參數傳遞。對於我們現有的算術運算子,結果是一個數字,所以我們傳遞 NUMBER_VAL 巨集。
}
在 run() 函式中
替換 4 行
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break; case OP_SUBTRACT: BINARY_OP(NUMBER_VAL, -); break; case OP_MULTIPLY: BINARY_OP(NUMBER_VAL, *); break; case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
case OP_NEGATE:
很快,我會告訴你為什麼我們將包裝巨集作為引數。
18.4兩種新類型
我們所有現有的 clox 程式碼都恢復正常運作。最後,是時候新增一些新類型了。我們有一個正在執行的數字計算器,它現在執行許多無意義的偏執執行期類型檢查。我們可以在內部表示其他類型,但使用者的程式永遠無法建立這些類型之一的 Value。
直到現在,才是。我們將從新增對三個新文字值的編譯器支援開始:true、false 和 nil。它們都很簡單,所以我們將一次完成全部三個。
對於數字文字值,我們必須處理數十億個可能的數值這一事實。我們透過將文字值儲存在程式碼區塊的常數表中,並發出一個簡單載入該常數的位元組碼指令來解決這個問題。我們可以對新類型做同樣的事情。我們會將 true 儲存在常數表中,並使用 OP_CONSTANT 來讀取它。
但是,鑑於我們只需要擔心這些新類型中的三個(雙關語)可能值,對它們浪費兩個位元組的指令和一個常數表條目是多餘的—而且慢!—。相反地,我們將定義三個專用指令來將每個文字值推入堆疊。
OP_CONSTANT,
在 enum OpCode 中
OP_NIL, OP_TRUE, OP_FALSE,
OP_ADD,
我們的掃描器已經將 true、false 和 nil 視為關鍵字,因此我們可以跳到剖析器。使用我們的基於表格的 Pratt 剖析器,我們只需要將剖析器函式放入與這些關鍵字語彙單元類型相關的列中即可。我們將在所有三個插槽中使用相同的函式。在這裡
[TOKEN_ELSE] = {NULL, NULL, PREC_NONE},
取代 1 行
[TOKEN_FALSE] = {literal, NULL, PREC_NONE},
[TOKEN_FOR] = {NULL, NULL, PREC_NONE},
在這裡
[TOKEN_THIS] = {NULL, NULL, PREC_NONE},
取代 1 行
[TOKEN_TRUE] = {literal, NULL, PREC_NONE},
[TOKEN_VAR] = {NULL, NULL, PREC_NONE},
在這裡
[TOKEN_IF] = {NULL, NULL, PREC_NONE},
取代 1 行
[TOKEN_NIL] = {literal, NULL, PREC_NONE},
[TOKEN_OR] = {NULL, NULL, PREC_NONE},
當剖析器遇到前置位置的 false、nil 或 true 時,它會呼叫這個新的剖析器函式:
在 binary() 函式之後新增
static void literal() { switch (parser.previous.type) { case TOKEN_FALSE: emitByte(OP_FALSE); break; case TOKEN_NIL: emitByte(OP_NIL); break; case TOKEN_TRUE: emitByte(OP_TRUE); break; default: return; // Unreachable. } }
由於 parsePrecedence() 已經消耗了關鍵字語彙單元,我們只需要輸出正確的指令即可。我們根據剖析的語彙單元類型來判斷。我們的前端現在可以將布林值和 nil 文字值編譯成位元組碼。向下移動執行管道,我們到達直譯器。
case OP_CONSTANT: {
Value constant = READ_CONSTANT();
push(constant);
break;
}
在 run() 函式中
case OP_NIL: push(NIL_VAL); break; case OP_TRUE: push(BOOL_VAL(true)); break; case OP_FALSE: push(BOOL_VAL(false)); break;
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
這很簡單明瞭。每個指令都會呼叫適當的值並將其推入堆疊。我們也不應該忘記我們的反組譯器。
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
在 disassembleInstruction() 函式中
case OP_NIL: return simpleInstruction("OP_NIL", offset); case OP_TRUE: return simpleInstruction("OP_TRUE", offset); case OP_FALSE: return simpleInstruction("OP_FALSE", offset);
case OP_ADD:
有了這些,我們可以執行這個驚天動地的程式:
true
除了直譯器嘗試印出結果時會崩潰。我們需要擴展 printValue() 來處理新的類型:
void printValue(Value value) {
在 printValue() 中
取代 1 行
switch (value.type) { case VAL_BOOL: printf(AS_BOOL(value) ? "true" : "false"); break; case VAL_NIL: printf("nil"); break; case VAL_NUMBER: printf("%g", AS_NUMBER(value)); break; }
}
這樣就好了!現在我們有一些新類型。它們還不是很實用。除了文字值之外,你真的不能對它們做任何事情。nil 發揮作用還需要一段時間,但我們可以開始在邏輯運算子中使用布林值了。
18.4.1邏輯非和虛假性
最簡單的邏輯運算子是我們熟悉的一元非運算子。
print !true; // "false"
這個新的運算獲得了一個新的指令。
OP_DIVIDE,
在 enum OpCode 中
OP_NOT,
OP_NEGATE,
我們可以重複使用我們為一元否定寫的 unary() 剖析器函式來編譯非運算式。我們只需要將它放入剖析表格中即可。
[TOKEN_STAR] = {NULL, binary, PREC_FACTOR},
取代 1 行
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
[TOKEN_BANG_EQUAL] = {NULL, NULL, PREC_NONE},
因為我知道我們要這樣做,所以 unary() 函式已經有一個基於語彙單元類型的 switch 來判斷要輸出哪個位元組碼指令。我們只需新增另一種情況即可。
switch (operatorType) {
在 unary() 函式中
case TOKEN_BANG: emitByte(OP_NOT); break;
case TOKEN_MINUS: emitByte(OP_NEGATE); break;
default: return; // Unreachable.
}
這就是前端的全部內容。讓我們前往 VM 並將此指令付諸實現。
case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
在 run() 函式中
case OP_NOT: push(BOOL_VAL(isFalsey(pop()))); break;
case OP_NEGATE:
像我們之前的單元運算子一樣,它會彈出一個運算元、執行運算並將結果推入堆疊。而且,就像我們在那裡所做的一樣,我們必須擔心動態類型。對 true 取邏輯非很容易,但是沒有任何東西可以阻止不守規矩的程式設計師寫出類似這樣的程式碼:
print !nil;
對於一元負號,我們將否定任何不是數字的東西視為錯誤。但是 Lox 像大多數腳本語言一樣,在預期布林值的 ! 和其他情況下更加寬容。關於如何處理其他類型的規則稱為「虛假性」,我們在這裡實作它:
在 peek() 之後加入
static bool isFalsey(Value value) { return IS_NIL(value) || (IS_BOOL(value) && !AS_BOOL(value)); }
Lox 遵循 Ruby 的規則,nil 和 false 為假值,而其他所有值都表現得像 true。我們有一個新的指令可以產生,所以我們也需要在反組譯器中能夠取消產生它。
case OP_DIVIDE:
return simpleInstruction("OP_DIVIDE", offset);
在 disassembleInstruction() 函式中
case OP_NOT: return simpleInstruction("OP_NOT", offset);
case OP_NEGATE:
18 . 4 . 2相等和比較運算子
還不算太糟。讓我們保持勢頭,把相等和比較運算子也解決掉:==、!=、<、>、<= 和 >=。這涵蓋了所有回傳布林結果的運算子,除了邏輯運算子 and 和 or 之外。因為那些需要短路(基本上是做一些控制流程),所以我們還沒準備好處理它們。
以下是這些運算子的新指令
OP_FALSE,
在 enum OpCode 中
OP_EQUAL, OP_GREATER, OP_LESS,
OP_ADD,
等等,只有三個?那 !=、<= 和 >= 呢?我們也可以為這些建立指令。老實說,如果我們這樣做,虛擬機器會執行得更快,所以如果目標是效能,我們應該這樣做。
但我的主要目標是教你關於位元組碼編譯器的知識。我希望你開始內化位元組碼指令不需要緊密遵循使用者原始碼的想法。只要虛擬機器的行為對使用者來說是正確的,它就可以完全自由地使用它想要的任何指令集和程式碼序列。
表達式 a != b 與 !(a == b) 具有相同的語義,因此編譯器可以自由地將前者編譯成好像是後者一樣。它可以使用一個 OP_EQUAL 後面跟著一個 OP_NOT,而不是一個專用的 OP_NOT_EQUAL 指令。同樣地,a <= b 與 !(a > b) 相同,而 a >= b 則是 !(a < b)。因此,我們只需要三個新的指令。
但在剖析器中,我們確實有六個新的運算子要放入剖析表。我們使用和之前相同的 binary() 剖析器函式。這是 != 的列
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
取代 1 行
[TOKEN_BANG_EQUAL] = {NULL, binary, PREC_EQUALITY},
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
剩餘的五個運算子在表格中稍微下方一點。
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
替換 5 行
[TOKEN_EQUAL_EQUAL] = {NULL, binary, PREC_EQUALITY}, [TOKEN_GREATER] = {NULL, binary, PREC_COMPARISON}, [TOKEN_GREATER_EQUAL] = {NULL, binary, PREC_COMPARISON}, [TOKEN_LESS] = {NULL, binary, PREC_COMPARISON}, [TOKEN_LESS_EQUAL] = {NULL, binary, PREC_COMPARISON},
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
在 binary() 內部,我們已經有一個 switch 來為每個符記類型產生正確的位元組碼。我們為六個新的運算子加入了 case。
switch (operatorType) {
在 binary() 中
case TOKEN_BANG_EQUAL: emitBytes(OP_EQUAL, OP_NOT); break; case TOKEN_EQUAL_EQUAL: emitByte(OP_EQUAL); break; case TOKEN_GREATER: emitByte(OP_GREATER); break; case TOKEN_GREATER_EQUAL: emitBytes(OP_LESS, OP_NOT); break; case TOKEN_LESS: emitByte(OP_LESS); break; case TOKEN_LESS_EQUAL: emitBytes(OP_GREATER, OP_NOT); break;
case TOKEN_PLUS: emitByte(OP_ADD); break;
==、< 和 > 運算子會輸出單一指令。其他的則會輸出成對的指令,一個用來計算反向運算,然後一個 OP_NOT 用來反轉結果。六個運算子只需三個指令的代價!
這表示在虛擬機器中,我們的工作更簡單了。相等是最通用的運算。
case OP_FALSE: push(BOOL_VAL(false)); break;
在 run() 函式中
case OP_EQUAL: { Value b = pop(); Value a = pop(); push(BOOL_VAL(valuesEqual(a, b))); break; }
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
你可以在任何一對物件上評估 ==,甚至是不同類型的物件。它有足夠的複雜性,因此將該邏輯轉移到一個獨立的函式是合理的。該函式總是回傳一個 C 的 bool,所以我們可以安全地將結果包裝在 BOOL_VAL 中。該函式與 Values 有關,因此它位於「value」模組中。
} ValueArray;
在 struct ValueArray 之後加入
bool valuesEqual(Value a, Value b);
void initValueArray(ValueArray* array);
這是實作
在 printValue() 之後加入
bool valuesEqual(Value a, Value b) { if (a.type != b.type) return false; switch (a.type) { case VAL_BOOL: return AS_BOOL(a) == AS_BOOL(b); case VAL_NIL: return true; case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b); default: return false; // Unreachable. } }
首先,我們檢查類型。如果 Values 有不同的類型,它們絕對不相等。否則,我們解開兩個 Values 並直接比較它們。
對於每種類型的值,我們都有一個單獨的 case 來處理比較值本身。鑑於這些 case 如此相似,你可能會想知道為什麼我們不能簡單地 memcmp() 兩個 Value 結構體就搞定。問題在於,由於填充和不同大小的 union 欄位,一個 Value 包含未使用的位元。C 不保證這些位元中是什麼,因此兩個相等的 Value 在未使用的記憶體中實際上可能不同。
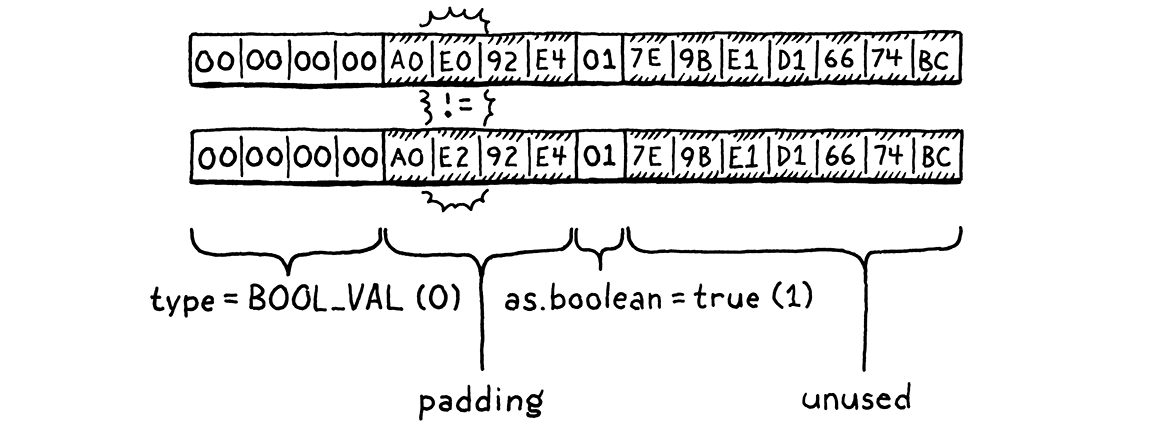
(你不會相信我在學到這個事實之前經歷了多少痛苦。)
無論如何,當我們向 clox 加入更多類型時,這個函式將會新增新的 case。目前,這三個就足夠了。其他的比較運算子比較容易,因為它們只適用於數字。
push(BOOL_VAL(valuesEqual(a, b)));
break;
}
在 run() 函式中
case OP_GREATER: BINARY_OP(BOOL_VAL, >); break; case OP_LESS: BINARY_OP(BOOL_VAL, <); break;
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
我們已經擴展了 BINARY_OP 巨集來處理回傳非數值類型的運算子。現在我們可以使用它了。我們傳入 BOOL_VAL,因為結果值的類型是布林值。否則,它與加號或減號沒有什麼不同。
一如既往,今天的詠嘆調的尾聲是反組譯新的指令。
case OP_FALSE:
return simpleInstruction("OP_FALSE", offset);
在 disassembleInstruction() 函式中
case OP_EQUAL: return simpleInstruction("OP_EQUAL", offset); case OP_GREATER: return simpleInstruction("OP_GREATER", offset); case OP_LESS: return simpleInstruction("OP_LESS", offset);
case OP_ADD:
有了這些,我們的數值計算器已經變得更接近一個通用的表達式評估器。啟動 clox 並輸入
!(5 - 4 > 3 * 2 == !nil)
好的,我承認這可能不是最有用的表達式,但我們正在取得進展。我們缺少一個具有自身字面形式的內建類型:字串。它們更複雜,因為字串的大小可能會有所不同。這個微小的差異結果產生了如此巨大的影響,以至於我們給了字串專屬的章節。
挑戰
-
我們可以比我們在這裡做的更進一步地減少我們的二元運算子。你還可以刪除哪些其他指令,以及編譯器將如何應對它們的缺失?
-
相反地,我們可以透過添加與更高階運算相對應的更具體的指令來提高位元組碼虛擬機器的速度。你會定義哪些指令來加快我們在本章中加入支援的使用者程式碼的速度?