字串
「啊?對勞力雜務有點反感?」醫生挑起眉毛。「可以理解,但這想法不對。人應該珍惜那些讓身體忙碌,但讓心靈和思想自由的瑣事。」
泰德·威廉斯,《龍骨王座》
我們的小型虛擬機器現在可以表示三種值類型:數字、布林值和 nil。這些類型有兩個重要的共通點:它們都是不可變的,而且它們都很小。數字是最大的,但它們仍然可以塞進兩個 64 位元的字組。這是一個很小的代價,我們可以為所有值付出這個代價,即使是布林值和 nil 這些不需要那麼多空間的值。
不幸的是,字串並不是那麼小巧。字串的長度沒有上限。即使我們人為地將其限制在某個不自然的上限,例如 255 個字元,對於每個值來說,仍然佔用太多記憶體。
我們需要一種方法來支援大小可變的值,有時變化會很大。這正是堆積上動態分配的設計目的。我們可以分配所需的位元組數。我們會取得一個指標,用來追蹤值在虛擬機器中的流動。
19.1值與物件
使用堆積來處理較大、大小可變的值,並使用堆疊來處理較小、原子值,這會導致兩層表示。您可以在變數中儲存或從表達式傳回的每個 Lox 值都會是一個 Value。對於較小、大小固定的類型(例如數字),有效負載會直接儲存在 Value 結構本身內部。
如果物件較大,則其資料會存在於堆積中。然後,Value 的有效負載會是一個指向該記憶體區塊的指標。我們最終會在 clox 中擁有一些堆積配置的類型:字串、實例、函式,您知道的。每種類型都有其獨特的資料,但它們也共享一些狀態,我們未來的垃圾收集器將使用這些狀態來管理它們的記憶體。
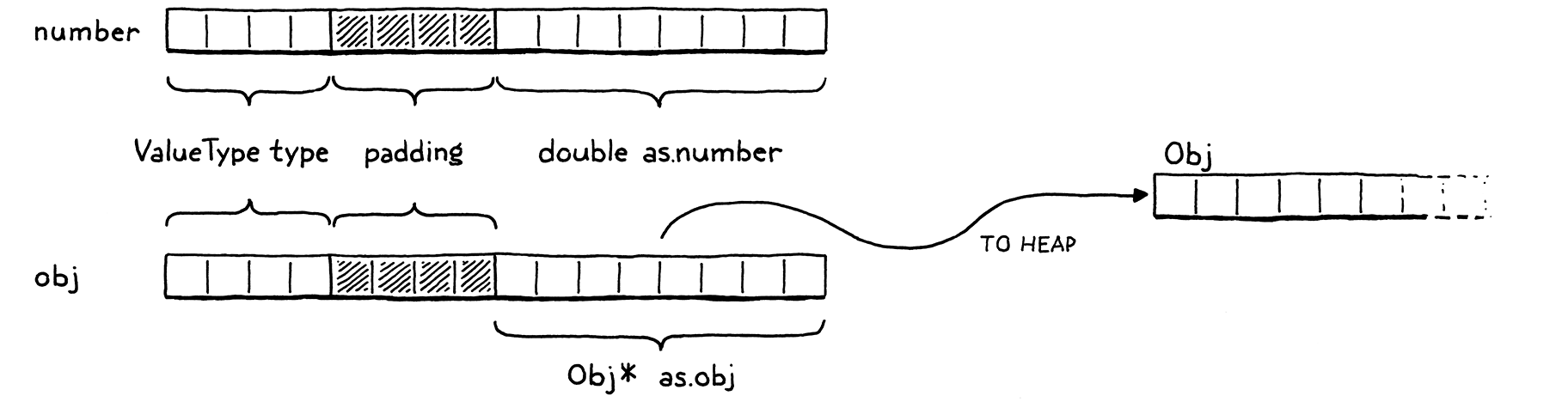
我們將把這種通用表示稱為 「Obj」。每個狀態存在於堆積上的 Lox 值都是一個 Obj。因此,我們可以只使用一個新的 ValueType case 來引用所有堆積配置的類型。
VAL_NUMBER,
在 enum ValueType 中
VAL_OBJ
} ValueType;
當 Value 的類型為 VAL_OBJ 時,有效負載是一個指向堆積記憶體的指標,因此我們在 union 中新增另一個 case。
double number;
在 struct Value 中
Obj* obj;
} as;
就像我們處理其他值類型一樣,我們建立一些有用的巨集來處理 Obj 值。
#define IS_NUMBER(value) ((value).type == VAL_NUMBER)
在 struct Value 之後新增
#define IS_OBJ(value) ((value).type == VAL_OBJ)
#define AS_BOOL(value) ((value).as.boolean)
如果給定的 Value 是 Obj,則此程式碼會評估為 true。如果是,我們可以這樣使用
#define IS_OBJ(value) ((value).type == VAL_OBJ)
#define AS_OBJ(value) ((value).as.obj)
#define AS_BOOL(value) ((value).as.boolean)
它會從值中提取 Obj 指標。我們也可以反向操作。
#define NUMBER_VAL(value) ((Value){VAL_NUMBER, {.number = value}})
#define OBJ_VAL(object) ((Value){VAL_OBJ, {.obj = (Obj*)object}})
typedef struct {
這會取得一個裸 Obj 指標,並將其包裝在完整的 Value 中。
19.2結構繼承
每個堆積配置的值都是一個 Obj,但 Objs 並非都相同。對於字串,我們需要字元陣列。當我們處理實例時,它們會需要它們的資料欄位。函式物件會需要其位元組碼區塊。我們要如何處理不同的有效負載和大小?我們不能像處理 Value 一樣使用另一個 union,因為它們的大小各不相同。
相反地,我們將使用另一種技術。它已經存在很長一段時間了,以至於 C 規格為它提供了特定的支援,但我不知道它是否有標準名稱。這是 類型雙關 的一個範例,但這個術語太過廣泛。在沒有任何更好的想法的情況下,我會將其稱為結構繼承,因為它依賴結構,並且大致遵循狀態在物件導向語言中單一繼承的方式。
就像標記的 union 一樣,每個 Obj 都以一個標籤欄位開始,該欄位會識別它是哪種類型的物件—字串、實例等等。接著是有效負載欄位。每個類型都不是使用針對每個類型的 case 的 union,而是擁有其各自的獨立結構。棘手的部分在於如何一致地處理這些結構,因為 C 沒有繼承或多型的概念。我很快就會解釋這一點,但首先讓我們處理一些初步的東西。
名稱「Obj」本身是指一個包含所有物件類型共用狀態的結構。它有點像是物件的「基底類別」。由於值和物件之間存在一些循環相依性,我們會在「value」模組中預先宣告它。
#include "common.h"
typedef struct Obj Obj;
typedef enum {
而實際的定義在一個新的模組中。
建立新檔案
#ifndef clox_object_h #define clox_object_h #include "common.h" #include "value.h" struct Obj { ObjType type; }; #endif
目前,它只包含類型標籤。不久之後,我們會新增一些用於記憶體管理的其他簿記資訊。類型 enum 是這個
#include "value.h"
typedef enum { OBJ_STRING, } ObjType;
struct Obj {
顯然,在我們新增更多堆積配置的類型之後,這會在後續的章節中更有用。由於我們會頻繁地存取這些標籤類型,因此值得建立一個小的巨集,從給定的 Value 中提取物件類型標籤。
#include "value.h"
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
typedef enum {
這就是我們的基礎。
現在,讓我們在其上建置字串。字串的有效負載是在一個獨立的結構中定義的。同樣地,我們需要預先宣告它。
typedef struct Obj Obj;
typedef struct ObjString ObjString;
typedef enum {
該定義與 Obj 並列。
};
在 struct Obj 之後新增
struct ObjString { Obj obj; int length; char* chars; };
#endif
字串物件包含一個字元陣列。這些字元儲存在一個獨立的堆積配置陣列中,以便我們只為每個字串保留所需的空間。我們也會儲存陣列中的位元組數。這並非絕對必要,但可以讓我們在不必走訪字元陣列來尋找空終止符的情況下,得知為字串配置了多少記憶體。
由於 ObjString 是一個 Obj,因此它也需要所有 Objs 共用的狀態。它藉由使其第一個欄位為一個 Obj 來完成此操作。C 規定結構欄位在記憶體中的排列順序與它們的宣告順序相同。此外,當您巢狀結構時,內層結構的欄位會直接展開。因此,Obj 和 ObjString 的記憶體配置如下所示
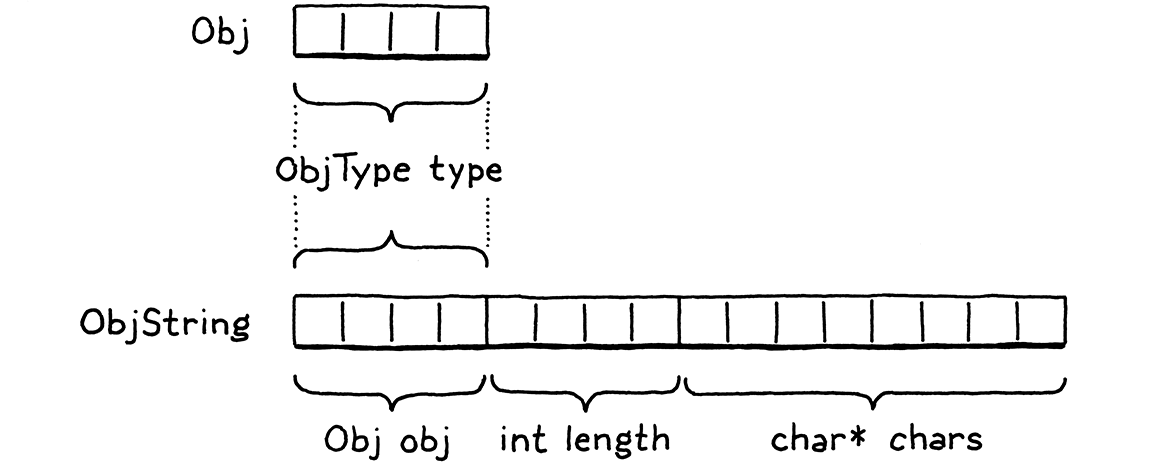
請注意 ObjString 的前幾個位元組如何與 Obj 完全對齊。這不是巧合—C 規定它必須如此。這是為了啟用一個巧妙的模式而設計的:您可以取得一個指向結構的指標,並安全地將其轉換為指向其第一個欄位的指標,然後再轉換回去。
給定一個 ObjString*,您可以安全地將其轉換為 Obj*,然後從中存取 type 欄位。在 OOP 的「是」的意義上,每個 ObjString「是」一個 Obj。當我們稍後新增其他物件類型時,每個結構的第一個欄位都會是一個 Obj。任何想要使用所有物件的程式碼都可以將它們視為基底 Obj*,並忽略任何可能剛好接在其後的其他欄位。
您也可以反向操作。給定一個 Obj*,您可以將其「向下轉型」為 ObjString*。當然,您需要確保您擁有的 Obj* 指標確實是指向實際 ObjString 的 obj 欄位。否則,您將不安全地重新解譯隨機的記憶體位元。為了偵測這種轉換是否安全,我們新增另一個巨集。
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_STRING(value) isObjType(value, OBJ_STRING)
typedef enum {
它會取得一個 Value,而不是原始 Obj*,因為虛擬機器中的大多數程式碼都是使用 Value。它依賴這個內嵌函式
};
在 struct ObjString 之後新增
static inline bool isObjType(Value value, ObjType type) { return IS_OBJ(value) && AS_OBJ(value)->type == type; }
#endif
快問快答:為什麼不直接將這個函式的主體放入巨集中?它與其他的函式有何不同?沒錯,那是因為主體使用了 value 兩次。巨集是透過插入參數表達式到主體中每次出現參數名稱的地方來展開的。如果巨集多次使用參數,則該表達式會被多次評估。
如果表達式有副作用,這就不妙了。如果我們將 isObjType() 的主體放入巨集定義中,然後您執行(例如)
IS_STRING(POP())
那麼它會從堆疊中彈出兩個值!使用函式可以修正這個問題。
只要我們確保每次建立某個類型的 Obj 時都會正確設定類型標籤,這個巨集就會告訴我們將值轉換為特定物件類型何時是安全的。我們可以使用這些執行此操作
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_STRING(value) ((ObjString*)AS_OBJ(value)) #define AS_CSTRING(value) (((ObjString*)AS_OBJ(value))->chars)
typedef enum {
這兩個巨集會取得一個 Value,該 Value 預期包含一個指向堆積上有效 ObjString 的指標。第一個會傳回 ObjString* 指標。第二個會逐步執行該指標,以傳回字元陣列本身,因為這通常是我們最終需要的。
19.3字串
好的,我們的虛擬機器現在可以表示字串值。現在是時候將字串新增到語言本身了。與往常一樣,我們從前端開始。詞法分析器已經將字串常值符號化,因此輪到剖析器了。
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
取代 1 行
[TOKEN_STRING] = {string, NULL, PREC_NONE},
[TOKEN_NUMBER] = {number, NULL, PREC_NONE},
當剖析器遇到字串符號時,它會呼叫這個剖析函式
在 number() 之後新增
static void string() { emitConstant(OBJ_VAL(copyString(parser.previous.start + 1, parser.previous.length - 2))); }
這會直接從詞素中取得字串的字元。+ 1 和 - 2 的部分會去除開頭和結尾的引號。然後它會建立一個字串物件,將其包裝在 Value 中,並將其放入常數表。
為了建立字串,我們使用 copyString(),它在 object.h 中宣告。
};
在 struct ObjString 之後新增
ObjString* copyString(const char* chars, int length);
static inline bool isObjType(Value value, ObjType type) {
編譯器模組需要包含它。
#define clox_compiler_h
#include "object.h"
#include "vm.h"
我們的「物件」模組取得一個實作檔案,我們在其中定義新函數。
建立新檔案
#include <stdio.h> #include <string.h> #include "memory.h" #include "object.h" #include "value.h" #include "vm.h" ObjString* copyString(const char* chars, int length) { char* heapChars = ALLOCATE(char, length + 1); memcpy(heapChars, chars, length); heapChars[length] = '\0'; return allocateString(heapChars, length); }
首先,我們在堆積上分配一個新的陣列,其大小剛好足以容納字串的字元和結尾的終止符,使用這個底層巨集來分配具有給定元素類型和計數的陣列
#include "common.h"
#define ALLOCATE(type, count) \ (type*)reallocate(NULL, 0, sizeof(type) * (count))
#define GROW_CAPACITY(capacity) \
一旦我們有了陣列,我們就會從詞素中複製字元並終止它。
你可能會想知道為什麼 ObjString 不能直接指回來源字串中的原始字元。有些 ObjString 會在執行期間動態建立,作為字串運算(例如串連)的結果。這些字串顯然需要動態分配記憶體給字元,這表示當不再需要該記憶體時,字串需要釋放該記憶體。
如果我們有一個字串常值的 ObjString,並試圖釋放其指向原始原始碼字串的字元陣列,就會發生不好的事情。因此,對於常值,我們會預先將字元複製到堆積中。這樣一來,每個 ObjString 都能可靠地擁有自己的字元陣列,並能釋放它。
建立字串物件的實際工作發生在這個函式中
#include "vm.h"
static ObjString* allocateString(char* chars, int length) { ObjString* string = ALLOCATE_OBJ(ObjString, OBJ_STRING); string->length = length; string->chars = chars; return string; }
它在堆積上建立一個新的 ObjString,然後初始化其欄位。它有點像 OOP 語言中的建構函式。因此,它首先呼叫「基礎類別」建構函式來初始化 Obj 狀態,使用新的巨集。
#include "vm.h"
#define ALLOCATE_OBJ(type, objectType) \ (type*)allocateObject(sizeof(type), objectType)
static ObjString* allocateString(char* chars, int length) {
就像先前的巨集一樣,這主要目的是為了避免需要重複將 void* 轉換回所需的類型。實際的功能在這裡
#define ALLOCATE_OBJ(type, objectType) \
(type*)allocateObject(sizeof(type), objectType)
static Obj* allocateObject(size_t size, ObjType type) { Obj* object = (Obj*)reallocate(NULL, 0, size); object->type = type; return object; }
static ObjString* allocateString(char* chars, int length) {
它在堆積上分配給定大小的物件。請注意,大小不只是 Obj 本身的大小。呼叫者傳遞位元組數,以便有空間容納所建立之特定物件類型所需的額外酬載欄位。
然後它會初始化 Obj 狀態—目前,這只是類型標籤。此函式會返回到 allocateString(),它會完成 ObjString 欄位的初始化。瞧,我們可以編譯並執行字串常值。
19 . 4字串上的運算
我們精美的字串已經存在,但它們還沒有什麼用處。一個好的第一步是讓現有的列印程式碼不會在新值類型上出錯。
case VAL_NUMBER: printf("%g", AS_NUMBER(value)); break;
在 printValue() 中
case VAL_OBJ: printObject(value); break;
}
如果值是堆積分配的物件,它會轉到「物件」模組中的輔助函式。
ObjString* copyString(const char* chars, int length);
在 copyString() 之後加入
void printObject(Value value);
static inline bool isObjType(Value value, ObjType type) {
實作看起來像這樣
在 copyString() 之後加入
void printObject(Value value) { switch (OBJ_TYPE(value)) { case OBJ_STRING: printf("%s", AS_CSTRING(value)); break; } }
我們現在只有一種物件類型,但此函式將在後續章節中長出額外的 switch case。對於字串物件,它只會將字元陣列列印為 C 字串。
等式運算子也需要優雅地處理字串。考慮
"string" == "string"
這是兩個獨立的字串常值。編譯器會對 copyString() 進行兩次獨立的呼叫,建立兩個不同的 ObjString 物件,並將它們儲存為區塊中的兩個常數。它們是堆積中不同的物件。但我們的使用者(因此我們)期望字串具有值相等性。上面的運算式應該評估為 true。這需要一些特殊支援。
case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b);
在 valuesEqual() 中
case VAL_OBJ: { ObjString* aString = AS_STRING(a); ObjString* bString = AS_STRING(b); return aString->length == bString->length && memcmp(aString->chars, bString->chars, aString->length) == 0; }
default: return false; // Unreachable.
如果兩個值都是字串,則如果它們的字元陣列包含相同的字元,則它們相等,無論它們是兩個獨立的物件還是完全相同的物件。這確實意味著字串相等性比其他類型上的相等性慢,因為它必須遍歷整個字串。我們將在稍後修改它,但這現在給了我們正確的語意。
最後,為了使用 memcmp() 和「物件」模組中的新內容,我們需要一些 include。在這裡
#include <stdio.h>
#include <string.h>
#include "memory.h"
在這裡
#include <string.h>
#include "object.h"
#include "memory.h"
19 . 4 . 1串連
成熟的語言提供了許多用於處理字串的運算—存取個別字元、字串長度、更改大小寫、分割、聯結、搜尋等等。當你實作自己的語言時,你可能需要所有這些。但對於本書,我們保持非常少的項目。
我們在字串上支援的唯一有趣的運算是 +。如果你在兩個字串物件上使用該運算子,它會產生一個新的字串,它是兩個運算元的串連。由於 Lox 是動態型別的,我們無法在編譯時判斷需要哪種行為,因為我們在執行階段之前不知道運算元的類型。因此,OP_ADD 指令會動態檢查運算元並選擇正確的運算。
case OP_LESS: BINARY_OP(BOOL_VAL, <); break;
在 run() 中
取代 1 行
case OP_ADD: { if (IS_STRING(peek(0)) && IS_STRING(peek(1))) { concatenate(); } else if (IS_NUMBER(peek(0)) && IS_NUMBER(peek(1))) { double b = AS_NUMBER(pop()); double a = AS_NUMBER(pop()); push(NUMBER_VAL(a + b)); } else { runtimeError( "Operands must be two numbers or two strings."); return INTERPRET_RUNTIME_ERROR; } break; }
case OP_SUBTRACT: BINARY_OP(NUMBER_VAL, -); break;
如果兩個運算元都是字串,則它會串連。如果它們都是數字,則它會將它們相加。任何其他運算元類型的組合都是執行階段錯誤。
為了串連字串,我們定義了一個新函式。
在 isFalsey() 之後加入
static void concatenate() { ObjString* b = AS_STRING(pop()); ObjString* a = AS_STRING(pop()); int length = a->length + b->length; char* chars = ALLOCATE(char, length + 1); memcpy(chars, a->chars, a->length); memcpy(chars + a->length, b->chars, b->length); chars[length] = '\0'; ObjString* result = takeString(chars, length); push(OBJ_VAL(result)); }
它非常冗長,因為使用字串的 C 程式碼往往是這樣。首先,我們根據運算元的長度計算結果字串的長度。我們為結果分配一個字元陣列,然後將兩個半部分複製進去。一如既往,我們仔細確保字串已終止。
為了呼叫 memcpy(),VM 需要一個 include。
#include <stdio.h>
#include <string.h>
#include "common.h"
最後,我們產生一個 ObjString 來包含這些字元。這次我們使用一個新函式 takeString()。
};
在 struct ObjString 之後新增
ObjString* takeString(char* chars, int length);
ObjString* copyString(const char* chars, int length);
實作看起來像這樣
在 allocateString() 之後加入
ObjString* takeString(char* chars, int length) { return allocateString(chars, length); }
先前的 copyString() 函式假設它無法取得你傳遞的字元的擁有權。相反,它保守地在堆積上建立字元的副本,ObjString 可以擁有該副本。對於字串常值,傳遞的字元位於來源字串的中間,這是正確的做法。
但是,對於串連,我們已經在堆積上動態分配了一個字元陣列。建立該陣列的另一個副本將是多餘的(並且意味著 concatenate() 必須記得釋放其副本)。相反,此函式會聲明你給它的字串的所有權。
和往常一樣,將此功能拼湊在一起需要一些 include。
#include "debug.h"
#include "object.h" #include "memory.h"
#include "vm.h"
19 . 5釋放物件
看看這個看似無害的運算式
"st" + "ri" + "ng"
當編譯器處理此運算式時,它會為這三個字串常值中的每一個分配一個 ObjString,並將它們儲存在區塊的常數表中,並產生此位元碼
0000 OP_CONSTANT 0 "st" 0002 OP_CONSTANT 1 "ri" 0004 OP_ADD 0005 OP_CONSTANT 2 "ng" 0007 OP_ADD 0008 OP_RETURN
前兩個指令將 "st" 和 "ri" 推入堆疊。然後,OP_ADD 會彈出這些指令並串連它們。這會在堆積上動態分配一個新的 "stri" 字串。VM 會推入該字串,然後推入 "ng" 常數。最後一個 OP_ADD 會彈出 "stri" 和 "ng",串連它們,並推入結果:"string"。太棒了,這就是我們所期望的。
但是,等等。"stri" 字串發生了什麼事?我們動態分配了它,然後 VM 在將其與 "ng" 串連後丟棄了它。我們將其從堆疊中彈出,不再有對它的參照,但我們從未釋放它的記憶體。我們自己造成了典型的記憶體洩漏。
當然,Lox 程式完全可以忘記中間字串,而不必擔心釋放它們。Lox 會自動代表使用者管理記憶體。管理記憶體的責任不會消失。相反,它落在我們作為 VM 實作人員的肩上。
完整的解決方案是一個垃圾收集器,它會在程式執行時回收未使用的記憶體。在我們準備好處理該專案之前,我們還有其他事情要做。在那之前,我們是在借來的時間裡生存。我們等待添加收集器的時間越長,就越難做到。
今天,我們至少應該做到最低限度:避免記憶體洩漏,方法是確保虛擬機(VM)仍然可以找到每個已配置的物件,即使 Lox 程式本身不再參照它們。進階的記憶體管理器使用許多複雜的技術來配置和追蹤物件的記憶體。我們將採用最簡單實用的方法。
我們會建立一個鏈結串列,儲存每個 Obj。虛擬機可以走訪該串列,找到堆積上配置的每個物件,無論使用者的程式或虛擬機的堆疊是否仍然參照它。
我們可以定義一個獨立的鏈結串列節點結構,但這樣我們也必須配置這些節點。相反地,我們將使用一個侵入式串列—Obj 結構本身會是鏈結串列的節點。每個 Obj 都會有一個指標指向鏈中的下一個 Obj。
struct Obj {
ObjType type;
在 Obj 結構中
struct Obj* next;
};
虛擬機儲存一個指標,指向串列的頭部。
Value* stackTop;
在 VM 結構中
Obj* objects;
} VM;
當我們首次初始化虛擬機時,沒有任何已配置的物件。
resetStack();
在 initVM() 中
vm.objects = NULL;
}
每次我們配置一個 Obj 時,我們都會將它插入串列中。
object->type = type;
在 allocateObject() 中
object->next = vm.objects; vm.objects = object;
return object;
由於這是一個單向鏈結串列,最容易插入的地方是頭部。這樣一來,我們也不需要儲存一個指向尾部的指標,並保持它的更新。
「object」模組直接使用了「vm」模組的全域 vm 變數,因此我們需要將它對外公開。
} InterpretResult;
在 enum InterpretResult 之後新增
extern VM vm;
void initVM();
最終,垃圾回收器會在虛擬機仍在執行時釋放記憶體。但是,即使如此,當使用者的程式完成時,通常仍然會有未使用的物件殘留在記憶體中。虛擬機也應該釋放這些物件。
沒有複雜的邏輯來處理這個問題。一旦程式完成,我們可以釋放每個物件。我們現在可以而且應該實作這個功能。
void freeVM() {
在 freeVM() 中
freeObjects();
}
我們在很久以前定義的空函式終於有作用了!它呼叫這個
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
在 reallocate() 之後新增
void freeObjects();
#endif
這是我們釋放物件的方式
在 reallocate() 之後新增
void freeObjects() { Obj* object = vm.objects; while (object != NULL) { Obj* next = object->next; freeObject(object); object = next; } }
這是計算機科學 101 教科書中走訪鏈結串列並釋放其節點的實作。對於每個節點,我們呼叫
在 reallocate() 之後新增
static void freeObject(Obj* object) { switch (object->type) { case OBJ_STRING: { ObjString* string = (ObjString*)object; FREE_ARRAY(char, string->chars, string->length + 1); FREE(ObjString, object); break; } } }
我們不僅僅釋放 Obj 本身。由於某些物件類型也會配置它們擁有的其他記憶體,我們還需要一些特定於類型的程式碼來處理每個物件類型的特殊需求。在這裡,這意味著我們要釋放字元陣列,然後釋放 ObjString。這些都會使用最後一個記憶體管理巨集。
(type*)reallocate(NULL, 0, sizeof(type) * (count))
#define FREE(type, pointer) reallocate(pointer, sizeof(type), 0)
#define GROW_CAPACITY(capacity) \
它是 reallocate() 的一個小型包裝函式,將配置的大小「調整」為零位元組。
像往常一樣,我們需要一個 include 來將所有內容連結在一起。
#include "common.h"
#include "object.h"
#define ALLOCATE(type, count) \
然後在實作檔案中
#include "memory.h"
#include "vm.h"
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
有了這個,我們的虛擬機不再洩漏記憶體。像一個好的 C 程式一樣,它會在退出前清理它的混亂。但是它不會在虛擬機執行時釋放任何物件。稍後,當可以編寫執行時間更長的 Lox 程式時,虛擬機將會逐漸消耗越來越多的記憶體,直到整個程式完成才會釋放單一位元組。
在我們加入真正的垃圾回收器之前,我們不會處理這個問題,但這是一個很大的進步。我們現在有了支援各種不同類型的動態配置物件的基礎結構。我們已經使用它來將字串加入 clox 中,字串是大多數程式語言中最常用的類型之一。字串反過來使我們能夠建構另一種基本資料類型,尤其是在動態語言中:歷史悠久的雜湊表。但那是下一章的內容 . . .
挑戰
-
每個字串都需要兩個獨立的動態配置—一個用於 ObjString,另一個用於字元陣列。從值存取字元需要兩次指標間接存取,這可能會對效能產生負面影響。更有效率的解決方案依賴於一種稱為彈性陣列成員的技術。使用它將 ObjString 及其字元陣列儲存在單一連續配置中。
-
當我們為每個字串文字建立 ObjString 時,我們會將字元複製到堆積上。這樣一來,當字串稍後被釋放時,我們就知道釋放這些字元是安全的。
這是一種較簡單的方法,但會浪費一些記憶體,這在非常受限的裝置上可能會是一個問題。相反地,我們可以追蹤哪些 ObjString 擁有它們的字元陣列,以及哪些是「常數字串」,它們只會指向原始來源字串或某些其他不可釋放的位置。新增對此的支援。
-
如果 Lox 是你的語言,當使用者嘗試使用
+,其中一個運算元是字串,而另一個運算元是其他類型時,你會讓它做什麼?說明你選擇的原因。其他語言會怎麼做?
設計注意事項:字串編碼
在這本書中,我盡量不迴避你在實際語言實作中會遇到的棘手問題。我們可能不總是使用最複雜的解決方案—畢竟這是一本入門書—但我認為假裝這個問題根本不存在是不誠實的。然而,我確實迴避了一個非常棘手的難題:決定如何表示字串。
字串編碼有兩個方面
-
字串中的單一「字元」是什麼?有多少不同的值,它們代表什麼?第一個被廣泛採用的標準答案是 ASCII。它給你 127 個不同的字元值,並指定它們是什麼。這很棒 . . . 如果你只關心英文。雖然它有一些奇怪且幾乎被遺忘的字元,例如「記錄分隔符」和「同步閒置」,但它沒有任何一個母音變音、銳音符或重音符。它無法表示「jalapeño」、「naïve」、「Gruyère」或「Mötley Crüe」。
接著出現了 Unicode。最初,它支援 16,384 個不同的字元(碼點),它們可以完美地放入 16 位元中,並留有一些位元。後來,這個數字越來越大,現在有超過 100,000 個不同的碼點,包括諸如 💩(Unicode 字元「PILE OF POO」,
U+1F4A9)等人類溝通的重要工具。即使是這麼長的碼點列表,也不足以表示語言可能支援的每個可見字形。為了處理這個問題,Unicode 也有組合字元,它們會修改前面的碼點。例如,「a」後面跟著組合字元「¨」,就會得到「ä」。 (為了使事情更令人困惑,Unicode 也有一個看起來像「ä」的單一碼點。)
如果使用者存取「naïve」中的第四個「字元」,他們期望得到「v」還是「¨」?前者表示他們將每個碼點及其組合字元視為單一單位—Unicode 稱之為擴展字形群集—後者表示他們以個別碼點來思考。你的使用者期望哪一種?
-
單一單位如何在記憶體中表示?大多數使用 ASCII 的系統為每個字元分配一個位元組,並讓高位未使用。Unicode 有一些常見的編碼方式。UTF-16 將大多數碼點打包到 16 位元中。當每個碼點都符合該大小時,這很棒。當這個大小溢出時,它們加入了代理對,使用多個 16 位元碼元來表示單一碼點。UTF-32 是 UTF-16 的下一個演進—它為每個碼點都提供完整的 32 位元。
UTF-8 比這兩種都複雜。它使用可變數量的位元組來編碼碼點。較低值的碼點可以放入較少的位元組中。由於每個字元可能佔用不同數量的位元組,因此你無法直接索引到字串中來找到特定的碼點。如果你想要第 10 個碼點,你就不知道它在字串中是多少個位元組,除非走訪並解碼所有前面的碼點。
選擇字元表示法和編碼涉及基本的取捨。就像工程中的許多事情一樣,沒有完美的解決方案
-
ASCII 的記憶體效率很高且速度快,但它將非拉丁語言排除在外。
-
UTF-32 速度快並支援整個 Unicode 範圍,但由於大多數碼點往往位於較低的值範圍內(不需要完整的 32 位元),因此會浪費大量記憶體。
-
UTF-8 的記憶體效率很高並支援整個 Unicode 範圍,但其可變長度編碼使其難以存取任意碼點。
-
UTF-16 比它們都糟—這是 Unicode 超過其早期 16 位元範圍的可怕後果。它的記憶體效率不如 UTF-8,但由於代理對,它仍然是可變長度的編碼。如果可以,請避免使用它。唉,如果你的語言需要在瀏覽器、JVM 或 CLR 上執行或與之互操作,你可能會被困在其中,因為它們都使用 UTF-16 作為其字串,而你不想每次將字串傳遞給底層系統時都必須轉換。
一種選擇是採取最大化的方法,並做「最正確」的事情。支援所有 Unicode 碼點。在內部,根據每個字串的內容選擇編碼—如果每個碼點都符合一個位元組,則使用 ASCII;如果沒有代理對,則使用 UTF-16,等等。提供 API 讓使用者可以走訪碼點和擴展字形群集。
這涵蓋了你所有的基礎,但非常複雜。它有很多需要實作、除錯和最佳化的工作。當序列化字串或與其他系統互操作時,你必須處理所有編碼。使用者需要理解這兩個索引 API,並知道何時使用哪一個。這是較新的大型語言傾向於採用的方法—例如 Raku 和 Swift。
一個更簡單的妥協方案是始終使用 UTF-8 進行編碼,並且僅公開一個使用碼點的 API。對於想要使用字形群集的使用者,讓他們使用第三方函式庫來處理。這比 ASCII 不那麼以拉丁語為中心,但沒有複雜太多。你失去了按碼點快速直接索引的能力,但通常可以不使用它,或者可以讓它變成 O(n) 而不是 O(1)。
如果我要為撰寫大型應用程式的人們設計一種大型的工作馬語言,我可能會採用最大化的方法。但對於我這個小型的嵌入式腳本語言 Wren 來說,我選擇了 UTF-8 和碼位 (code points)。