雜湊表
雜湊,x。這個詞沒有定義—沒有人知道雜湊是什麼。
安布羅斯·比爾斯,《未刪節的魔鬼辭典》
在我們能將變數加入我們快速發展的虛擬機器之前,我們需要一些方法來根據變數的名稱查詢值。稍後,當我們加入類別時,我們也需要一種方法來儲存實例上的欄位。對於這些問題和其他問題來說,完美的資料結構就是雜湊表。
你可能已經知道雜湊表是什麼了,即使你不知道它的名字。如果你是 Java 程式設計師,你會稱它們為「HashMap」。C# 和 Python 使用者稱它們為「字典」。在 C++ 中,它是「unordered map」。JavaScript 中的「物件」和 Lua 中的「表格」在底層都是雜湊表,這賦予了它們彈性。
雜湊表,無論你的語言怎麼稱呼它,都會將一組鍵與一組值關聯起來。每個鍵/值對都是表中的一個條目。給定一個鍵,你可以查詢其對應的值。你可以新增新的鍵/值對,並依鍵移除條目。如果你為現有的鍵新增一個新值,它會取代先前的條目。
雜湊表出現在這麼多語言中,是因為它們功能非常強大。這種力量大部分來自於一個指標:給定一個鍵,雜湊表會在常數時間內傳回對應的值,無論雜湊表中有多少個鍵。
當你想到這一點時,這非常了不起。想像一下,你有一大疊名片,我請你找到某個人。堆疊越大,需要花費的時間就越長。即使堆疊整理得很好,而且你有足夠的手動靈巧度來進行手動二元搜尋,你仍然在說O(log n)。但是使用雜湊表,當堆疊有十張卡片時,與當堆疊有一百萬張卡片時,找到那張名片所需的時間相同。
20 . 1桶的陣列
一個完整、快速的雜湊表有幾個活動部件。我將透過處理幾個玩具問題及其解決方案來一次介紹一個。最終,我們將建立一個資料結構,可以將任何一組名稱與其值關聯起來。
現在,假設 Lox 在變數名稱方面非常受限。如果變數的名稱只能是單個小寫字母呢?我們如何非常有效地表示一組變數名稱及其值?
只有 26 個可能的變數(如果你認為底線是「字母」,我想是 27 個),答案很簡單。宣告一個具有 26 個元素的固定大小陣列。我們將遵循傳統,並將每個元素稱為桶。每個元素都代表一個變數,其中 a 從索引零開始。如果陣列中某個字母的索引處有一個值,則該鍵會與該值一起存在。否則,桶是空的,並且該鍵/值對不在資料結構中。
記憶體使用量非常棒—只是一個單一、合理大小的陣列。空的桶會浪費一些空間,但並不大。沒有節點指標、填補或其他你在連結串列或樹之類的東西中會獲得的東西的額外負擔。
效能甚至更好。給定一個變數名稱—它的字元—你可以減去 a 的 ASCII 值,並使用結果直接索引到陣列中。然後,你可以查詢現有的值,或將新值直接儲存到該槽中。沒有比這快得多的了。
這有點像我們柏拉圖式的理想資料結構。快如閃電、非常簡單,且記憶體緊湊。當我們新增對更複雜鍵的支援時,我們必須做出一些讓步,但這是我們的目標。即使你加入雜湊函數、動態調整大小和碰撞處理,這仍然是每個雜湊表的核心—一個你可以直接索引的連續桶陣列。
20 . 1 . 1負載因子與環繞鍵
將 Lox 限制為單字母變數會使我們作為實作者的工作更加輕鬆,但使用一種只給你 26 個儲存位置的語言進行程式設計可能沒有樂趣。如果我們稍微放寬限制並允許變數長度最多為八個字元呢?
這夠小,我們可以將所有八個字元封裝到 64 位元整數中,並輕鬆地將字串轉換為數字。然後我們可以將其用作陣列索引。或者,至少,如果我們能夠以某種方式配置一個 295,148 PB 的陣列,我們就可以這麼做。記憶體隨著時間的推移變得越來越便宜,但還沒有那麼便宜。即使我們能夠建立一個這麼大的陣列,也會非常浪費。除非使用者開始編寫比我們預期的更大的 Lox 程式,否則幾乎每個桶都會是空的。
即使我們的變數鍵涵蓋了完整的 64 位元數字範圍,我們顯然也不需要這麼大的陣列。相反,我們配置一個容量足以容納我們需要的條目,但又不會大到不合理的陣列。我們透過取值除以陣列大小的餘數,將完整的 64 位元鍵對應到較小的範圍。這樣做本質上是將較大的數字範圍折疊到自身,直到它符合較小的陣列元素範圍。
例如,假設我們要儲存「bagel」。我們配置一個具有八個元素的陣列,足夠儲存它和之後更多的元素。我們將鍵字串視為 64 位元整數。在像 Intel 這樣的小端機器上,將這些字元封裝到 64 位元字中會將第一個字母「b」(ASCII 值 98)放在最低有效位元組中。我們取該整數除以陣列大小的餘數(8)以使其符合邊界,並獲得桶索引 2。然後我們像往常一樣將值儲存在那裡。
使用陣列大小作為模數可讓我們將鍵的數字範圍對應下來,以符合任何大小的陣列。因此,我們可以獨立於鍵範圍來控制桶的數量。這解決了我們的浪費問題,但引入了一個新的問題。當兩個變數的鍵數字除以陣列大小時具有相同的餘數,它們將會落在同一個桶中。鍵可能會碰撞。例如,如果我們嘗試新增「jam」,它也會落在桶 2 中。
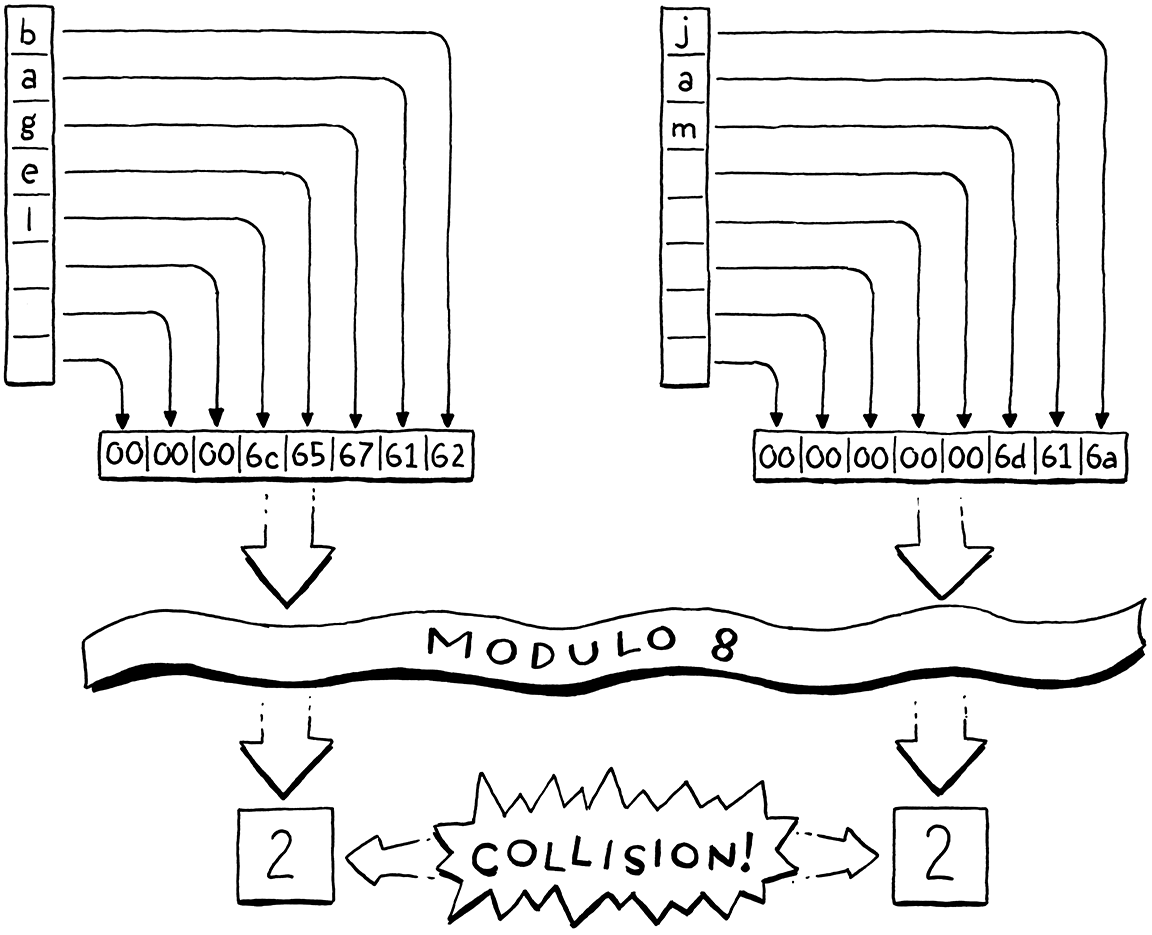
我們可以透過調整陣列大小來控制這一點。陣列越大,對應到同一個桶的索引就越少,而且可能發生的碰撞就越少。雜湊表實作者會透過測量表格的負載因子來追蹤這種碰撞可能性。它定義為條目的數量除以桶的數量。因此,具有五個條目和 16 個元素陣列的雜湊表,其負載因子為 0.3125。負載因子越高,發生碰撞的可能性就越大。
我們減輕碰撞的一種方法是調整陣列大小。就像我們之前實作的動態陣列一樣,我們會重新配置並在雜湊表的陣列填滿時使其增長。但是,與普通的動態陣列不同,我們不會等到陣列已滿。相反,我們會選擇所需的負載因子,並在超過該負載因子時增加陣列。
20 . 2碰撞處理
即使負載因子很低,仍可能發生碰撞。生日悖論告訴我們,隨著雜湊表中條目數量的增加,碰撞發生的機率會迅速增加。我們可以選擇一個大的陣列大小來減少這種情況,但這是一場必敗的遊戲。假設我們想在雜湊表中儲存一百個項目。為了使碰撞機率保持在仍然相當高的 10% 以下,我們需要一個至少有 47,015 個元素的陣列。為了使機率低於 1%,需要一個具有 492,555 個元素的陣列,每個使用的元素有超過 4,000 個空桶。
較低的負載因子可以使碰撞更罕見,但是鴿籠原理告訴我們,我們永遠無法完全消除碰撞。如果你有五隻寵物鴿子和四個鴿籠可以放牠們,那麼至少有一個鴿籠最終會有多於一隻鴿子。憑藉 18,446,744,073,709,551,616 個不同的變數名稱,任何合理大小的陣列都可能在同一個桶中有多個鍵。
因此,當發生碰撞時,我們仍然必須優雅地處理它們。使用者不喜歡他們的程式語言只能在大多數時候正確查詢變數。
20 . 2 . 1分離鏈結法
解決碰撞的技術分為兩大類。第一種是分離鏈結法。我們不讓每個桶包含單個條目,而是讓它包含它們的集合。在經典實作中,每個桶都指向一個條目連結串列。要查詢一個條目,你需要找到它的桶,然後走遍清單,直到找到具有匹配鍵的條目。
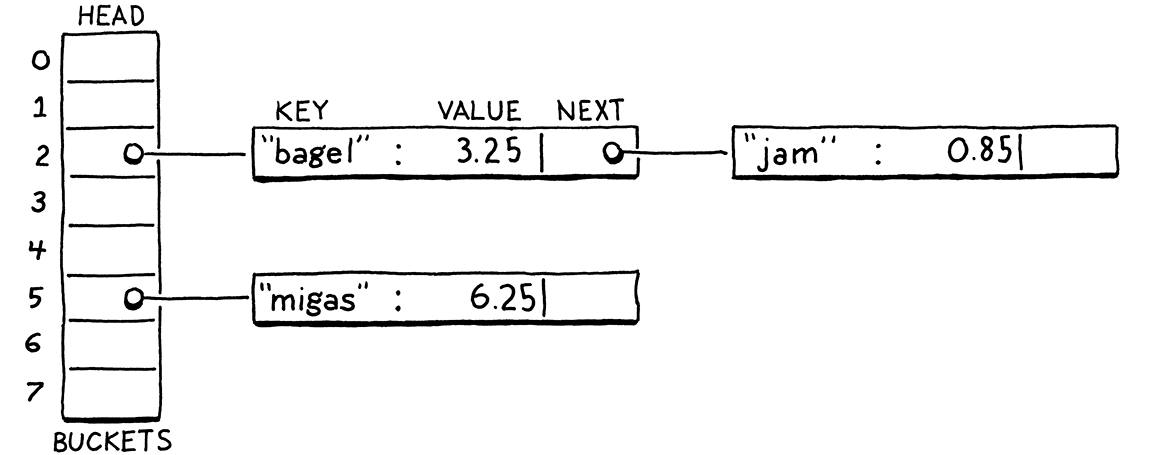
在每個條目都在同一個桶中碰撞的最壞情況下,資料結構會退化為具有 O(n) 查詢的單個未排序連結串列。在實務上,透過控制負載因子以及條目如何分散在各個桶中,很容易避免這種情況。在典型的分離鏈結雜湊表中,一個桶很少會有超過一個或兩個條目。
分離鏈結在概念上很簡單—它實際上是一個連結串列陣列。大多數操作都很容易實作,即使是刪除操作,正如我們將看到的,也可能很麻煩。但它不太適合現代 CPU。它來自指標的額外負擔很大,並且傾向於將記憶體中小的連結串列節點散佈在周圍,這不利於快取使用。
20 . 2 . 2開放定址法
另一種技術稱為開放定址法,或者(容易混淆地)稱為封閉雜湊。使用這種技術,所有條目都直接存在於儲存桶陣列中,每個儲存桶一個條目。如果兩個條目在同一個儲存桶中發生衝突,我們會尋找另一個空的儲存桶來代替。
將所有條目儲存在單個、大的、連續的陣列中,對於保持記憶體表示的簡單性和快速性非常有利。但是,它會使雜湊表上的所有操作都變得更加複雜。當插入條目時,其儲存桶可能已滿,導致我們需要查看另一個儲存桶。該儲存桶本身可能已被佔用,依此類推。這種尋找可用儲存桶的過程稱為探測,而檢查儲存桶的順序則稱為探測序列。
有許多演算法可以決定要探測哪些儲存桶以及如何決定哪個條目放入哪個儲存桶。這裡已經有很多研究,因為即使是微小的調整也可能對效能產生很大的影響。而且,在像雜湊表這樣大量使用的資料結構上,這種效能影響會觸及各種硬體能力中的大量真實世界的程式。
和本書中通常一樣,我們將選擇最簡單且能有效完成工作的演算法。那就是古老的線性探測。當尋找條目時,我們會在其鍵對應的第一個儲存桶中尋找。如果不在那裡,我們會查看陣列中的下一個元素,依此類推。如果到達結尾,我們會繞回到開頭。
線性探測的好處是它對快取友好。由於您直接以記憶體順序遍歷陣列,因此它能讓 CPU 的快取行保持滿載且運作良好。壞處是它容易產生叢集。如果您有很多具有數值相似的鍵值的條目,您可能會在彼此相鄰的地方產生許多衝突、溢出的儲存桶。
與單獨鏈結相比,開放定址法可能更難理解。我認為開放定址法與單獨鏈結類似,只是節點的「列表」是透過儲存桶陣列本身來串接的。連接不是將它們儲存在指標中,而是透過您查看儲存桶的順序隱式計算出來的。
棘手的部分是,多個這些隱式列表可能會交錯在一起。讓我們來看一個涵蓋所有有趣案例的範例。我們現在忽略值,只關心一組鍵。我們從一個空的 8 個儲存桶的陣列開始。

我們決定插入「bagel」。第一個字母「b」(ASCII 值 98)除以陣列大小 (8) 後,將其放入儲存桶 2。

接下來,我們插入「jam」。它也想進入儲存桶 2 (106 mod 8 = 2),但該儲存桶已被佔用。我們繼續探測下一個儲存桶。它是空的,所以我們把它放在那裡。
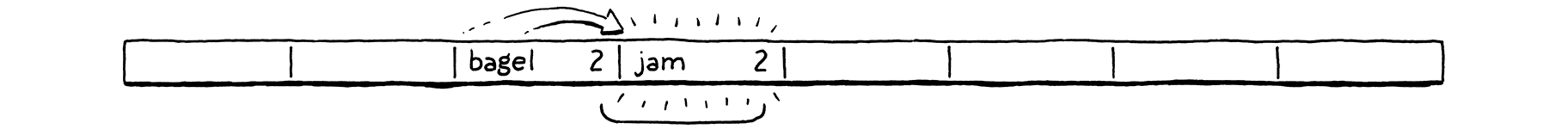
我們插入「fruit」,它順利地進入儲存桶 6。
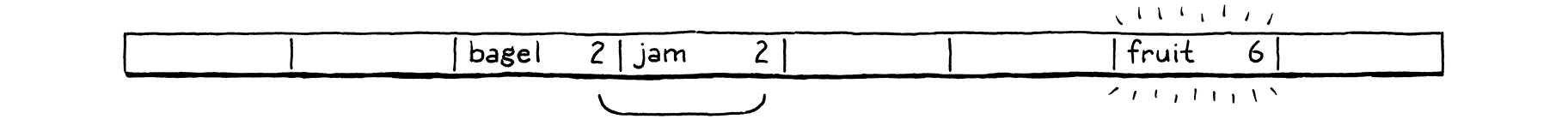
同樣,「migas」可以進入其首選的儲存桶 5。
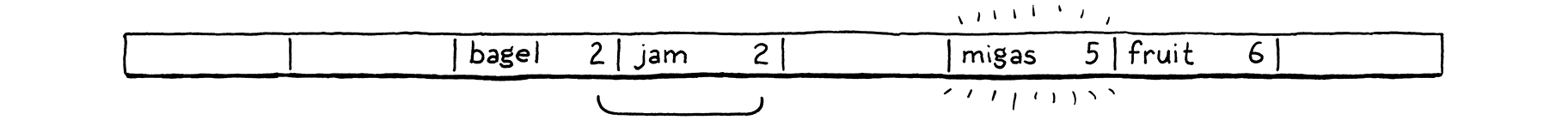
當我們嘗試插入「eggs」時,它也想進入儲存桶 5。它已滿,所以我們跳到 6。儲存桶 6 也已滿。請注意,其中的條目不屬於同一探測序列。「Fruit」位於其首選的儲存桶 6 中。因此,5 和 6 的序列發生了衝突並交錯在一起。我們跳過它,最後將「eggs」放入儲存桶 7 中。

我們在「nuts」中遇到類似的問題。它無法像它想的那樣進入 6。它也無法進入 7。所以我們繼續。但是我們已經到達陣列的末尾,所以我們繞回到 0 並將它放在那裡。

在實踐中,交錯情況並不是什麼大問題。即使在單獨鏈結中,我們也需要遍歷列表來檢查每個條目的鍵,因為多個鍵可以減少到同一個儲存桶。使用開放定址法,我們需要進行相同的檢查,這也涵蓋了您正在跳過「屬於」不同原始儲存桶的條目的情況。
20 . 3雜湊函數
我們現在可以為自己建立一個相當有效率的表格,用於儲存最多八個字元的變數名稱,但這種限制仍然很煩人。為了放寬最後的限制,我們需要一種方法將任何長度的字串轉換為固定大小的整數。
最後,我們來到了「雜湊表」中的「雜湊」部分。雜湊函數會取得一些較大的資料區塊,並將其「雜湊」以產生固定大小的整數雜湊碼,其值取決於原始資料的所有位元。一個好的雜湊函數有三個主要目標
-
它必須是確定性的。相同的輸入必須始終雜湊為相同的數字。如果相同的變數在不同的時間點最終出現在不同的儲存桶中,那麼要找到它就會變得非常困難。
-
它必須是均勻的。給定一組典型的輸入,它應該產生範圍廣泛且均勻分佈的輸出數字,並儘可能減少群集或模式。我們希望它將值分散在整個數字範圍內,以最大程度地減少衝突和叢集。
-
它必須快速。雜湊表上的每個操作都需要我們首先雜湊鍵。如果雜湊很慢,它可能會抵消底層陣列儲存的速度。
那裡有大量的雜湊函數。有些是舊的,並針對不再有人使用的架構進行了最佳化。有些被設計為快速的,另一些則被設計為加密安全的。有些利用特定晶片的向量指令和快取大小,另一些則旨在最大程度地提高可攜性。
有些人將設計和評估雜湊函數視為他們的專長。我很佩服他們,但我的數學能力不足以成為其中之一。因此,對於 clox,我選擇了一個簡單、廣為使用的雜湊函數,稱為 FNV-1a,多年來它一直很好用。考慮在您的程式碼中嘗試不同的函數,看看它們是否會產生任何影響。
好的,這是一個快速介紹儲存桶、載荷因子、開放定址、衝突解決和雜湊函數的內容。這是一大堆文字,而不是很多真正的程式碼。如果它仍然看起來模糊不清,請不要擔心。一旦我們完成編碼,一切都會到位。
20 . 4建立雜湊表
與其他經典技術(例如平衡搜尋樹)相比,雜湊表的最大好處是實際的資料結構非常簡單。我們的將進入一個新的模組。
建立新檔案
#ifndef clox_table_h #define clox_table_h #include "common.h" #include "value.h" typedef struct { int count; int capacity; Entry* entries; } Table; #endif
雜湊表是一個條目陣列。如同我們之前的動態陣列一樣,我們會追蹤陣列的配置大小 (capacity) 以及目前儲存在其中的鍵/值對的數量 (count)。計數與容量的比率正好是雜湊表的載荷因子。
每個條目都是這些之一
#include "value.h"
typedef struct { ObjString* key; Value value; } Entry;
typedef struct {
它是一個簡單的鍵/值對。由於鍵始終是一個字串,因此我們直接儲存 ObjString 指標,而不是將其包裝在 Value 中。這樣做速度更快、體積更小。
為了建立一個新的、空的雜湊表,我們宣告一個類似建構函式的函式。
} Table;
在 struct Table 之後新增
void initTable(Table* table);
#endif
我們需要一個新的實作檔案來定義它。在我們這麼做的同時,讓我們把所有煩人的 include 都解決掉。
建立新檔案
#include <stdlib.h> #include <string.h> #include "memory.h" #include "object.h" #include "table.h" #include "value.h" void initTable(Table* table) { table->count = 0; table->capacity = 0; table->entries = NULL; }
如同我們的動態值陣列類型,雜湊表最初從零容量和 NULL 陣列開始。在需要之前,我們不會配置任何內容。假設我們最終配置了某些內容,我們也需要能夠釋放它。
void initTable(Table* table);
在 initTable() 之後新增
void freeTable(Table* table);
#endif
及其光榮的實作
在 initTable() 之後新增
void freeTable(Table* table) { FREE_ARRAY(Entry, table->entries, table->capacity); initTable(table); }
同樣,它看起來就像一個動態陣列。事實上,您可以將雜湊表基本上視為一個動態陣列,其插入項目的策略非常奇怪。我們不需要在此處檢查 NULL,因為 FREE_ARRAY() 已經可以優雅地處理它了。
20 . 4 . 1雜湊字串
在我們開始將條目放入表格之前,我們需要先雜湊它們。為了確保條目均勻分佈在整個陣列中,我們需要一個好的雜湊函數來檢查鍵字串的所有位元。如果它只檢查前幾個字元,那麼一系列具有相同前綴的字串最終會衝突在同一個儲存桶中。
另一方面,遍歷整個字串來計算雜湊有點慢。如果我們每次在表格中尋找鍵時都必須遍歷字串,那麼我們將會失去雜湊表的部分效能優勢。所以我們會做顯而易見的事情:快取它。
在 ObjString 的「物件」模組中,我們新增
char* chars;
在 struct ObjString 中
uint32_t hash;
};
每個 ObjString 都儲存其字串的雜湊碼。由於字串在 Lox 中是不可變的,因此我們可以預先計算一次雜湊碼,並確定它永遠不會失效。預先快取它是有道理的:配置字串並複製其字元已經是一個 O(n) 操作,因此這也是執行字串雜湊的 O(n) 計算的好時機。
每當我們呼叫內部函式來配置字串時,我們都會傳入其雜湊碼。
函式 allocateString()
取代 1 行
static ObjString* allocateString(char* chars, int length, uint32_t hash) {
ObjString* string = ALLOCATE_OBJ(ObjString, OBJ_STRING);
該函式只是將雜湊儲存在結構中。
string->chars = chars;
在 allocateString() 中
string->hash = hash;
return string; }
有趣的部份發生在呼叫端。allocateString() 從兩個地方被呼叫:一個是複製字串的函式,另一個是取得現有動態配置字串所有權的函式。我們先從第一個開始。
ObjString* copyString(const char* chars, int length) {
在 copyString() 中
uint32_t hash = hashString(chars, length);
char* heapChars = ALLOCATE(char, length + 1);
這裡沒有什麼魔法。我們計算雜湊碼,然後將它傳遞出去。
memcpy(heapChars, chars, length); heapChars[length] = '\0';
在 copyString() 中
取代 1 行
return allocateString(heapChars, length, hash);
}
另一個字串函式也很類似。
ObjString* takeString(char* chars, int length) {
在 takeString() 中
取代 1 行
uint32_t hash = hashString(chars, length); return allocateString(chars, length, hash);
}
有趣的程式碼在這裡
在 allocateString() 之後新增
static uint32_t hashString(const char* key, int length) { uint32_t hash = 2166136261u; for (int i = 0; i < length; i++) { hash ^= (uint8_t)key[i]; hash *= 16777619; } return hash; }
這是在 clox 中真正名符其實的「雜湊函式」。這個演算法稱為「FNV-1a」,是我所知最短且不錯的雜湊函式。簡潔當然是一本旨在向您展示每一行程式碼的書的優點。
基本概念很簡單,許多雜湊函式都遵循相同的模式。您從某個初始雜湊值開始,通常是一個具有某些精心選擇的數學屬性的常數。然後您遍歷要雜湊的資料。對於每個位元組(或有時是字),您會以某種方式將位元混合到雜湊值中,然後將產生的位元組打亂。
「混合」和「打亂」的意義可能會變得相當複雜。但最終,基本目標是均勻性—我們希望產生的雜湊值盡可能分散在數值範圍內,以避免碰撞和群聚。
20.4.2插入條目
現在字串物件知道它們的雜湊碼,我們可以開始將它們放入雜湊表。
void freeTable(Table* table);
在 freeTable() 之後新增
bool tableSet(Table* table, ObjString* key, Value value);
#endif
此函式將給定的鍵/值對新增到給定的雜湊表。如果該鍵的條目已存在,則新值會覆蓋舊值。如果新增了新的條目,則函式會傳回 true。以下是實作:
在 freeTable() 之後新增
bool tableSet(Table* table, ObjString* key, Value value) { Entry* entry = findEntry(table->entries, table->capacity, key); bool isNewKey = entry->key == NULL; if (isNewKey) table->count++; entry->key = key; entry->value = value; return isNewKey; }
大部分有趣的邏輯都在 findEntry() 中,我們稍後會介紹。該函式的工作是取得一個鍵,並計算出它應該放入陣列中的哪個儲存桶。它傳回指向該儲存桶的指標—陣列中 Entry 的位址。
一旦我們有了儲存桶,插入就很簡單。我們更新雜湊表的大小,注意不要在覆蓋已存在的鍵的值時增加計數。然後,我們將鍵和值複製到 Entry 中相應的欄位。
不過,我們這裡少了一點東西。我們還沒有真正配置 Entry 陣列。糟糕!在我們可以插入任何東西之前,我們需要確保我們有一個陣列,並且它夠大。
bool tableSet(Table* table, ObjString* key, Value value) {
在 tableSet() 中
if (table->count + 1 > table->capacity * TABLE_MAX_LOAD) { int capacity = GROW_CAPACITY(table->capacity); adjustCapacity(table, capacity); }
Entry* entry = findEntry(table->entries, table->capacity, key);
這與我們之前編寫的用於擴展動態陣列的程式碼類似。如果我們沒有足夠的容量來插入項目,我們會重新配置並擴展陣列。GROW_CAPACITY() 巨集會取得現有的容量,並將其乘以一個倍數以確保我們在一系列插入操作中獲得攤銷的常數效能。
這裡有趣的不同之處在於 TABLE_MAX_LOAD 常數。
#include "value.h"
#define TABLE_MAX_LOAD 0.75
void initTable(Table* table) {
這就是我們管理表格的載入係數的方式。我們不會在容量完全滿時擴展。相反,我們會在那之前擴展陣列,當陣列至少達到 75% 滿時。
我們稍後將介紹 adjustCapacity() 的實作。首先,讓我們看看您一直在想的 findEntry() 函式。
在 freeTable() 之後新增
static Entry* findEntry(Entry* entries, int capacity, ObjString* key) { uint32_t index = key->hash % capacity; for (;;) { Entry* entry = &entries[index]; if (entry->key == key || entry->key == NULL) { return entry; } index = (index + 1) % capacity; } }
這個函式是雜湊表的真正核心。它負責取得一個鍵和一個儲存桶陣列,並計算出條目屬於哪個儲存桶。此函式也是線性探測和碰撞處理發揮作用的地方。我們將使用 findEntry() 來尋找雜湊表中現有的條目,並決定在哪裡插入新的條目。
儘管如此,它也沒有什麼特別的。首先,我們使用模數運算將鍵的雜湊碼對應到陣列範圍內的索引。這給了我們一個儲存桶索引,理想情況下,我們可以在那裡找到或放置條目。
有幾個情況需要檢查
-
如果該陣列索引處的 Entry 的鍵為
NULL,則該儲存桶為空。如果我們使用findEntry()在雜湊表中尋找內容,則表示它不存在。如果我們使用它來插入,則表示我們找到了一個新增新條目的位置。 -
如果儲存桶中的鍵等於我們要尋找的鍵,則該鍵已存在於表格中。如果我們正在進行查詢,那就太好了—我們已經找到了我們要尋找的鍵。如果我們正在進行插入,則表示我們將替換該鍵的值,而不是新增新的條目。
- 否則,儲存桶中有一個條目,但鍵不同。這是一個碰撞。在這種情況下,我們開始探測。這就是
for迴圈的作用。我們從條目理想情況下應去的儲存桶開始。如果該儲存桶為空或具有相同的鍵,則我們就完成了。否則,我們前進到下一個元素—這是「線性探測」中的線性部分—並在那裡檢查。如果我們超過了陣列的末尾,則第二個模數運算符會將我們包裝回開頭。
當我們找到一個空的儲存桶或與我們正在尋找的鍵具有相同鍵的儲存桶時,我們就會退出迴圈。您可能想知道一個無限迴圈。如果我們與每個儲存桶發生碰撞怎麼辦?幸運的是,由於我們的載入係數,這種情況不會發生。因為我們在陣列即將滿時會擴展陣列,所以我們知道總是會有空的儲存桶。
我們直接從迴圈中傳回,傳回一個指向找到的 Entry 的指標,以便呼叫端可以將某些東西插入其中或從中讀取。回到 tableSet(),也就是最初啟動它的函式,我們將新條目儲存在傳回的儲存桶中,然後就完成了。
20.4.3配置和調整大小
在我們可以將條目放入雜湊表之前,我們確實需要一個實際儲存它們的地方。我們需要配置一個儲存桶陣列。這發生在這個函式中
在 findEntry() 之後新增
static void adjustCapacity(Table* table, int capacity) { Entry* entries = ALLOCATE(Entry, capacity); for (int i = 0; i < capacity; i++) { entries[i].key = NULL; entries[i].value = NIL_VAL; } table->entries = entries; table->capacity = capacity; }
我們使用 capacity 條目建立一個儲存桶陣列。配置陣列後,我們將每個元素初始化為空儲存桶,然後將陣列(及其容量)儲存在雜湊表的主要結構中。當我們將第一個條目插入表格時,此程式碼沒問題,並且我們需要第一次配置陣列。但是,當我們已經有一個並且需要擴展它時會怎樣?
當我們執行動態陣列時,我們可以只使用 realloc(),並讓 C 標準函式庫將所有內容複製過去。這對雜湊表不起作用。請記住,要為每個條目選擇儲存桶,我們將其雜湊鍵對陣列大小取模。這表示當陣列大小變更時,條目可能會最終進入不同的儲存桶。
這些新的儲存桶可能有我們需要處理的新碰撞。因此,讓每個條目都到達其應有位置的最簡單方法是透過將每個條目重新插入新的空陣列中來從頭重建表格。
entries[i].value = NIL_VAL; }
在 adjustCapacity() 中
for (int i = 0; i < table->capacity; i++) { Entry* entry = &table->entries[i]; if (entry->key == NULL) continue; Entry* dest = findEntry(entries, capacity, entry->key); dest->key = entry->key; dest->value = entry->value; }
table->entries = entries;
我們從前到後遍歷舊陣列。每當我們找到非空的儲存桶時,我們就會將該條目插入到新陣列中。我們使用 findEntry(),傳入新陣列,而不是目前儲存在 Table 中的陣列。(這就是為什麼 findEntry() 直接取得指向 Entry 陣列的指標,而不是整個 Table 結構。這樣,我們就可以在將它們儲存在結構中之前傳遞新陣列和容量。)
完成之後,我們可以釋放舊陣列的記憶體。
dest->value = entry->value; }
在 adjustCapacity() 中
FREE_ARRAY(Entry, table->entries, table->capacity);
table->entries = entries;
有了這個,我們就有了一個可以塞入任意多條目的雜湊表。它可以處理覆蓋現有鍵,並根據需要自行擴展以維持所需的載入容量。
在我們做到這一點的同時,我們也來定義一個輔助函式,用於將一個雜湊表的所有條目複製到另一個雜湊表。
bool tableSet(Table* table, ObjString* key, Value value);
在 tableSet() 之後新增
void tableAddAll(Table* from, Table* to);
#endif
在我們支援方法繼承之前,我們都不需要它,但我們不妨現在就實作它,因為我們對所有雜湊表的東西都還記憶猶新。
在 tableSet() 之後新增
void tableAddAll(Table* from, Table* to) { for (int i = 0; i < from->capacity; i++) { Entry* entry = &from->entries[i]; if (entry->key != NULL) { tableSet(to, entry->key, entry->value); } } }
對此沒有太多可說的。它會遍歷來源雜湊表的儲存桶陣列。每當它找到非空的儲存桶時,它就會使用我們最近定義的 tableSet() 函式將條目新增到目的地雜湊表。
20.4.4擷取值
現在我們的雜湊表包含一些內容,讓我們開始將內容取回。給定一個鍵,我們可以透過此函式查詢對應的值(如果有的話)
void freeTable(Table* table);
在 freeTable() 之後新增
bool tableGet(Table* table, ObjString* key, Value* value);
bool tableSet(Table* table, ObjString* key, Value value);
您傳入表格和鍵。如果找到具有該鍵的條目,則傳回 true,否則傳回 false。如果條目存在,則 value 輸出參數會指向產生的值。
由於 findEntry() 已經完成了艱鉅的工作,因此實作並不差。
在 findEntry() 之後新增
bool tableGet(Table* table, ObjString* key, Value* value) { if (table->count == 0) return false; Entry* entry = findEntry(table->entries, table->capacity, key); if (entry->key == NULL) return false; *value = entry->value; return true; }
如果表格完全為空,我們絕對找不到條目,因此我們先檢查一下。這不僅是一種最佳化—它也確保我們不會在陣列為 NULL 時嘗試存取儲存桶陣列。否則,我們讓 findEntry() 發揮其魔力。它會傳回指向儲存桶的指標。如果儲存桶為空,我們透過查看鍵是否為 NULL 來偵測到,則表示我們沒有找到具有我們鍵的 Entry。如果 findEntry() 確實傳回非空的 Entry,則表示它與我們的鍵相符。我們取得 Entry 的值並將其複製到輸出參數,以便呼叫端可以取得它。小菜一碟。
20.4.5刪除條目
一個功能齊全的雜湊表需要支援的另一個基本操作是:移除條目。這似乎很明顯,如果您可以新增東西,您應該可以取消新增它們,對吧?但您會驚訝於有多少關於雜湊表的教學省略了這一點。
我本來也可以採取那條路。事實上,我們在 clox 中只在虛擬機的一個極小的邊緣情況下使用刪除。但是如果你想真正了解如何完整實作雜湊表,這感覺很重要。我能理解他們想要忽略它的想法。正如我們將看到的,從使用開放尋址的雜湊表中刪除是很棘手的。
至少宣告很簡單。
bool tableSet(Table* table, ObjString* key, Value value);
在 tableSet() 之後新增
bool tableDelete(Table* table, ObjString* key);
void tableAddAll(Table* from, Table* to);
顯而易見的方法是仿照插入。使用 findEntry() 查找條目的儲存桶。然後清除該儲存桶。完成!
在沒有發生碰撞的情況下,這方法運作良好。但是如果發生了碰撞,則該條目所在的儲存桶可能是一個或多個隱式探測序列的一部分。例如,這裡有一個雜湊表,其中包含三個鍵,它們都具有相同的首選儲存桶,2
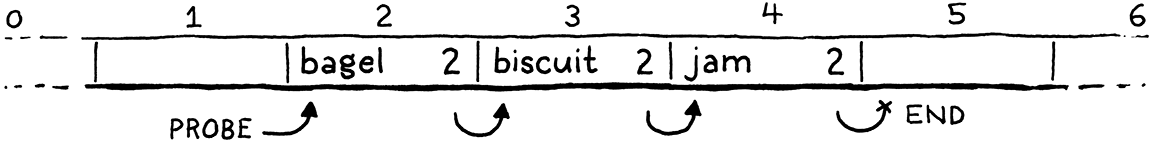
請記住,當我們走訪探測序列以查找條目時,當我們遇到一個空的儲存桶時,我們就知道已經到達序列的末尾,並且該條目不存在。這就像探測序列是一個條目列表,而一個空的條目終止了該列表。
如果我們僅僅通過清除 Entry 來刪除「biscuit」,那麼我們就會在中間破壞該探測序列,使尾隨的條目成為孤兒並且無法訪問。有點像從鏈結串列中移除一個節點,而沒有將指針從前一個節點重新鏈結到下一個節點。
如果我們稍後嘗試查找「jam」,我們將從「bagel」開始,在下一個空的 Entry 處停止,並且永遠找不到它。

為了解決這個問題,大多數實作都使用一個稱為墓碑的技巧。我們不是在刪除時清除條目,而是用一個特殊的哨兵條目(稱為「墓碑」)替換它。當我們在查找期間追蹤探測序列時,如果遇到墓碑,我們不會將其視為空槽並停止迭代。相反,我們會繼續,這樣刪除條目就不會破壞任何隱式的碰撞鏈,而且我們仍然可以找到它之後的條目。

程式碼看起來像這樣
在 tableSet() 之後新增
bool tableDelete(Table* table, ObjString* key) { if (table->count == 0) return false; // Find the entry. Entry* entry = findEntry(table->entries, table->capacity, key); if (entry->key == NULL) return false; // Place a tombstone in the entry. entry->key = NULL; entry->value = BOOL_VAL(true); return true; }
首先,我們找到包含要刪除條目的儲存桶。(如果我們找不到它,則沒有任何內容需要刪除,因此我們退出。)我們用墓碑替換該條目。在 clox 中,我們使用 NULL 鍵和 true 值來表示它,但是任何不會與空儲存桶或有效條目混淆的表示形式都可以。
這就是我們刪除條目所需要做的全部工作。簡單又快速。但是所有其他操作也需要正確處理墓碑。墓碑是一種「半」條目。它具有一些現有條目的特性,以及一些空條目的特性。
當我們在查找期間追蹤探測序列時,如果遇到墓碑,我們會記錄它並繼續。
for (;;) {
Entry* entry = &entries[index];
在 findEntry() 中
替換 3 行
if (entry->key == NULL) { if (IS_NIL(entry->value)) { // Empty entry. return tombstone != NULL ? tombstone : entry; } else { // We found a tombstone. if (tombstone == NULL) tombstone = entry; } } else if (entry->key == key) { // We found the key. return entry; }
index = (index + 1) % capacity;
我們第一次經過墓碑時,會將其儲存在這個區域變數中
uint32_t index = key->hash % capacity;
在 findEntry() 中
Entry* tombstone = NULL;
for (;;) {
如果我們到達一個真正的空條目,則該鍵不存在。在這種情況下,如果我們已經經過墓碑,我們會返回其儲存桶,而不是後來的空儲存桶。如果我們為了插入節點而呼叫 findEntry(),這可以讓我們將墓碑儲存桶視為空的,並將其重複使用於新條目。
像這樣自動重複使用墓碑插槽有助於減少墓碑在儲存桶陣列中浪費空間的數量。在有混合插入和刪除的典型使用案例中,墓碑的數量會增長一段時間,然後趨於穩定。
即便如此,也無法保證大量的刪除不會導致陣列中充滿墓碑。在最壞的情況下,我們可能會最終沒有空的儲存桶。這會很糟糕,因為請記住,唯一可以防止 findEntry() 中無限循環的事情是假設我們最終會遇到一個空的儲存桶。
因此,我們需要仔細考慮墓碑如何與表的負載因子和調整大小互動。關鍵問題是,在計算負載因子時,我們應該將墓碑視為滿儲存桶還是空儲存桶?
20.4.6計算墓碑
如果我們將墓碑視為滿儲存桶,那麼我們最終可能會得到一個比我們可能需要的更大的陣列,因為它會人為地誇大負載因子。有一些墓碑我們可以重複使用,但是它們不會被視為未使用,因此我們最終會過早地擴大陣列。
但是,如果我們將墓碑視為空儲存桶,並且不將它們包含在負載因子中,那麼我們就有可能最終沒有實際的空儲存桶來終止查找。無限循環比一些額外的陣列插槽要嚴重得多,因此對於負載因子,我們將墓碑視為滿儲存桶。
這就是為什麼我們在先前的程式碼中刪除條目時不減少計數的原因。該計數不再是雜湊表中的條目數,而是條目數加上墓碑數。這意味著只有當新條目進入完全空的儲存桶時,我們才會在插入期間增加計數。
bool isNewKey = entry->key == NULL;
在 tableSet() 中
取代 1 行
if (isNewKey && IS_NIL(entry->value)) table->count++;
entry->key = key;
如果我們用新條目替換墓碑,則該儲存桶已被考慮在內,並且計數不會改變。
當我們調整陣列大小時,我們會配置一個新陣列,並將所有現有的條目重新插入其中。在此過程中,我們不會複製墓碑。它們不會增加任何價值,因為無論如何我們都在重建探測序列,並且只會減慢查找速度。這意味著我們需要重新計算計數,因為它可能會在調整大小期間發生變化。因此,我們清除它
}
在 adjustCapacity() 中
table->count = 0;
for (int i = 0; i < table->capacity; i++) {
然後,每次找到非墓碑條目時,我們都會增加它。
dest->value = entry->value;
在 adjustCapacity() 中
table->count++;
}
這意味著當我們增加容量時,我們可能會在生成的較大陣列中最終得到較少的條目,因為所有墓碑都會被丟棄。這有點浪費,但不是一個巨大的實際問題。
我發現有趣的是,支援刪除條目的大部分工作都在 findEntry() 和 adjustCapacity() 中。實際的刪除邏輯非常簡單且快速。實際上,刪除往往很少見,因此您會期望雜湊表在刪除函數中盡可能多地完成工作,而讓其他函數保持不變以使其更快。使用我們的墓碑方法,刪除速度很快,但查找會受到懲罰。
我做了一些基準測試,以在一些不同的刪除情境中測試這一點。我驚訝地發現,與在刪除期間執行所有工作以重新插入受影響的條目相比,墓碑最終總體上更快。
但是,如果您仔細考慮一下,就會發現墓碑方法並不是將完全刪除條目的工作推遲到其他操作,而是使其刪除變得延遲。首先,它會執行最少的工作,將條目轉換為墓碑。這可能會在稍後的查找必須跳過它時導致懲罰。但是,它也允許稍後的插入重複使用該墓碑儲存桶。這種重複使用是一種非常有效的方式,可以避免重新排列所有受影響的後續條目的成本。您基本上可以回收探測條目鏈中的一個節點。這是一個巧妙的技巧。
20.5字串內部化
我們已經得到了一個大部分可以運作的雜湊表,儘管它的中心有一個嚴重的缺陷。而且,我們還沒有將其用於任何用途。現在是時候解決這兩個問題了,並在此過程中學習解釋器使用的一種經典技術。
雜湊表無法完全運作的原因是,當 findEntry() 檢查現有鍵是否與正在查找的鍵匹配時,它使用 == 來比較兩個字串是否相等。只有當兩個鍵在記憶體中是完全相同的字串時,這才會返回 true。兩個具有相同字元的單獨字串應該被視為相等,但事實並非如此。
請記住,在上一章中新增字串時,我們新增了明確的支援來逐字元比較字串,以便獲得 true 的值相等性。我們可以在 findEntry() 中執行此操作,但這很慢。
相反,我們將使用一種稱為字串內部化的技術。核心問題是,記憶體中可能存在具有相同字元的不同字串。即使它們是不同的物件,它們也需要表現得像等效值。它們本質上是重複的,我們必須比較它們的所有位元組才能檢測到這一點。
字串內部化是一個去重複的過程。我們建立一個「內部化」字串的集合。該集合中的任何字串都保證在文字上與所有其他字串不同。當您內部化字串時,您會在集合中查找匹配的字串。如果找到,則使用原始字串。否則,您擁有的字串是唯一的,因此您將其新增到集合中。
透過這種方式,您知道每個字元序列在記憶體中僅由一個字串表示。這使得值相等性變得微不足道。如果兩個字串指向記憶體中的相同位址,則它們顯然是相同的字串,並且必須相等。而且,由於我們知道字串是唯一的,因此如果兩個字串指向不同的位址,則它們必須是不同的字串。
因此,指標相等性與值相等性完全一致。這反過來表示我們在 findEntry() 中現有的 == 做的是正確的事情。或者至少,一旦我們對所有字串進行了內部化(intern),它就會是正確的。為了可靠地消除所有字串的重複,虛擬機器需要能夠找到每個被建立的字串。我們透過給它一個雜湊表來儲存所有字串來做到這一點。
Value* stackTop;
在 struct VM 中
Table strings;
Obj* objects;
照常,我們需要一個 include。
#include "chunk.h"
#include "table.h"
#include "value.h"
當我們啟動一個新的虛擬機器時,字串表是空的。
vm.objects = NULL;
在 initVM() 中
initTable(&vm.strings);
}
當我們關閉虛擬機器時,我們會清理該表使用的任何資源。
void freeVM() {
在 freeVM() 中
freeTable(&vm.strings);
freeObjects();
有些語言具有單獨的類型或明確的步驟來內部化字串。對於 clox,我們會自動內部化每個字串。這表示當我們建立一個新的唯一字串時,我們會將它添加到表中。
string->hash = hash;
在 allocateString() 中
tableSet(&vm.strings, string, NIL_VAL);
return string;
我們使用該表更像是一個雜湊集合而不是雜湊表。鍵是字串,而這是我們關心的所有內容,因此我們僅對值使用 nil。
這會將字串放入表中,假設它是唯一的,但是我們實際上需要在到達這裡之前檢查重複項。我們在呼叫 allocateString() 的兩個較高層級的函式中執行此操作。這是一個
uint32_t hash = hashString(chars, length);
在 copyString() 中
ObjString* interned = tableFindString(&vm.strings, chars, length, hash); if (interned != NULL) return interned;
char* heapChars = ALLOCATE(char, length + 1);
當將字串複製到新的 LoxString 時,我們會先在字串表中查找它。如果找到它,我們不會「複製」,而是僅返回對該字串的引用。否則,我們將繼續執行,分配一個新的字串,並將它儲存在字串表中。
取得字串的所有權有點不同。
uint32_t hash = hashString(chars, length);
在 takeString() 中
ObjString* interned = tableFindString(&vm.strings, chars, length, hash); if (interned != NULL) { FREE_ARRAY(char, chars, length + 1); return interned; }
return allocateString(chars, length, hash);
同樣,我們先在字串表中查找該字串。如果找到它,在返回它之前,我們會釋放傳入的字串的記憶體。由於所有權被傳遞給此函式,而我們不再需要重複的字串,因此由我們來釋放它。
在我們開始撰寫需要的新函式之前,還有一個 include。
#include "object.h"
#include "table.h"
#include "value.h"
為了在表中查找字串,我們不能使用一般的 tableGet() 函式,因為它會呼叫 findEntry(),而 findEntry() 具有我們目前正試圖修復的重複字串的確切問題。相反地,我們使用這個新的函式
void tableAddAll(Table* from, Table* to);
在 tableAddAll() 之後新增
ObjString* tableFindString(Table* table, const char* chars, int length, uint32_t hash);
#endif
實作如下
在 tableAddAll() 之後新增
ObjString* tableFindString(Table* table, const char* chars, int length, uint32_t hash) { if (table->count == 0) return NULL; uint32_t index = hash % table->capacity; for (;;) { Entry* entry = &table->entries[index]; if (entry->key == NULL) { // Stop if we find an empty non-tombstone entry. if (IS_NIL(entry->value)) return NULL; } else if (entry->key->length == length && entry->key->hash == hash && memcmp(entry->key->chars, chars, length) == 0) { // We found it. return entry->key; } index = (index + 1) % table->capacity; } }
看起來我們已經複製貼上了 findEntry()。有很多冗餘,但也有一些關鍵的差異。首先,我們傳入我們正在查找的鍵的原始字元陣列,而不是 ObjString。在我們呼叫此程式碼時,我們尚未建立 ObjString。
其次,當檢查是否找到鍵時,我們會檢查實際的字串。我們先查看它們是否具有匹配的長度和雜湊值。這些檢查速度很快,如果它們不相等,則字串絕對不相同。
如果發生雜湊衝突,我們會進行逐字元的字串比較。這是虛擬機器中我們實際測試字串是否在文字上相等的地方。我們在此處執行此操作以消除字串的重複,然後虛擬機器的其餘部分可以認為,記憶體中不同位址的任何兩個字串都必須具有不同的內容。
實際上,既然我們已經內部化了所有字串,我們就可以在位元組碼直譯器中加以利用。當使用者對兩個恰好是字串的物件執行 == 時,我們不再需要測試字元。
case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b);
在 valuesEqual() 中
取代 7 行
case VAL_OBJ: return AS_OBJ(a) == AS_OBJ(b);
default: return false; // Unreachable.
我們在建立字串以內部化它們時增加了一些額外負荷。但是作為回報,在執行階段,字串上的相等運算符要快得多。有了這個,我們就有一個功能完善的雜湊表,可以使用它來追蹤變數、實例或任何其他可能出現的鍵值對。
我們也加速了測試字串是否相等的速度。這對於使用者對字串執行 == 時很有用。但在像 Lox 這樣的動態類型語言中,方法呼叫和實例欄位在執行階段按名稱查找時,它甚至更重要。如果測試字串是否相等的速度很慢,則表示按名稱查找方法的速度很慢。如果這在您的物件導向語言中很慢,那麼一切都會很慢。
挑戰
-
在 clox 中,我們碰巧只需要身為字串的鍵,因此我們建構的雜湊表是為該鍵類型硬編碼的。如果我們將雜湊表作為一流的集合公開給 Lox 使用者,則支援不同種類的鍵會很有用。
新增對其他基本類型(數字、布林值和
nil)的鍵的支援。稍後,clox 將支援使用者定義的類別。如果我們要支援身為這些類別實例的鍵,這會增加什麼樣的複雜性? -
雜湊表有很多旋鈕可以調整,這些旋鈕會影響其效能。您可以決定使用單獨的鍊式處理或開放定址。根據您採取的岔路,您可以調整每個節點中儲存的條目數,或您使用的探測策略。您可以控制雜湊函式、負載因數和成長率。
建立所有這些多樣性不僅僅是為了讓電腦科學博士候選人可以發表論文:它們在許多不同的領域和硬體環境中都有其用途,雜湊會在其中發揮作用。查找不同開源系統中的一些雜湊表實作、研究他們所做的選擇,並嘗試找出他們這樣做的原因。
-
對雜湊表進行基準測試是出了名的困難。雜湊表實作在某些鍵集上可能表現良好,而在其他鍵集上則表現不佳。它可能在小型尺寸下運作良好,但隨著它的成長而降低,反之亦然。它可能在刪除很常見時崩潰,但在不常見時則能快速執行。建立能準確代表您的使用者將如何使用雜湊表的基準是一項挑戰。
編寫一些不同的基準程式來驗證我們的雜湊表實作。它們之間的效能如何變化?您為什麼選擇您選擇的特定測試案例?