垃圾回收
我想要,我想要,
我想要,我想要,
我想要變成垃圾。The Whip, “Trash”
我們說 Lox 是一種「高階」語言,因為它讓程式設計師不必擔心與他們正在解決的問題無關的細節。使用者變成執行長,給機器抽象的目標,讓卑微的電腦想出如何達成目標。
動態記憶體配置是自動化的完美候選者。它是程式運作所必需的,手動執行很繁瑣,而且容易出錯。不可避免的錯誤可能會造成災難性的後果,導致崩潰、記憶體損壞或安全漏洞。這是一種機器比人類更擅長的、有風險但又枯燥的工作。
這就是為什麼 Lox 是一種受管理語言,這表示語言實作會代表使用者管理記憶體的配置和釋放。當使用者執行需要一些動態記憶體的操作時,虛擬機器會自動配置它。程式設計師永遠不用擔心釋放任何東西。機器會確保程式正在使用的任何記憶體在需要時都會保留下來。
Lox 提供了一種電腦擁有無限記憶體的錯覺。使用者可以配置、配置再配置,而從不考慮這些位元組來自哪裡。當然,電腦還沒有擁有無限的記憶體。因此,受管理語言維持這種錯覺的方式是在程式設計師背後回收程式不再需要的記憶體。執行此操作的元件稱為垃圾收集器。
26.1可達性
這提出了一個非常困難的問題:虛擬機器如何判斷哪些記憶體是不需要的?只有在未來會讀取記憶體時才需要記憶體,但如果沒有時光機,實作如何判斷程式將執行哪些程式碼以及它將使用哪些資料?劇透:虛擬機器無法穿越到未來。相反地,語言會做出一個保守的近似:如果一塊記憶體有可能在未來被讀取,則會認為它仍在使用中。
這聽起來太保守了。難道任何位元的記憶體都可能被讀取嗎?實際上,不,至少在像 Lox 這樣的記憶體安全語言中不是這樣。這是一個範例
var a = "first value"; a = "updated"; // GC here. print a;
假設我們在第二行中的賦值完成後執行垃圾收集器。「first value」字串仍然位於記憶體中,但使用者的程式永遠無法存取它。一旦 a 被重新賦值,程式就失去了對該字串的任何參照。我們可以安全地釋放它。如果使用者程式可以透過某種方式參照一個值,則該值是可達的。否則,就像這裡的「first value」字串一樣,它是無法達到的。
許多值可以由虛擬機器直接存取。看看
var global = "string"; { var local = "another"; print global + local; }
在兩個字串串聯之後但在 print 語句執行之前暫停程式。虛擬機器可以透過查看全域變數表並找到 global 的條目來存取 "string"。它可以通过走訪數值堆疊並命中區域變數 local 的槽位來找到 "another"。它甚至可以找到串聯的字串 "stringanother",因為當我們暫停程式時,該暫時值也位於虛擬機器的堆疊上。
所有這些值都稱為根。根是虛擬機器可以直接存取而無需透過其他物件中的參照的任何物件。大多數根是全域變數或在堆疊上,但我們將看到,虛擬機器還將參照儲存在其他幾個它可以找到的物件的位置。
其他值可以透過另一個值內的參照找到。類別實例上的欄位是最明顯的例子,但我們還沒有這些。即使沒有這些,我們的虛擬機器仍然有間接的參照。考慮
fun makeClosure() { var a = "data"; fun f() { print a; } return f; } { var closure = makeClosure(); // GC here. closure(); }
假設我們在標記的行上暫停程式並執行垃圾收集器。當收集器完成並且程式繼續執行時,它將呼叫閉包,這將依次列印 "data"。因此,收集器需要不釋放該字串。但這是我們暫停程式時堆疊的樣子

"data" 字串不在其中。它已經從堆疊中提取出來並移到閉包使用的封閉向上值中。閉包本身在堆疊上。但是要取得字串,我們需要追蹤閉包及其向上值陣列。由於使用者的程式可以這樣做,因此所有這些間接可存取的物件也被認為是可達的。
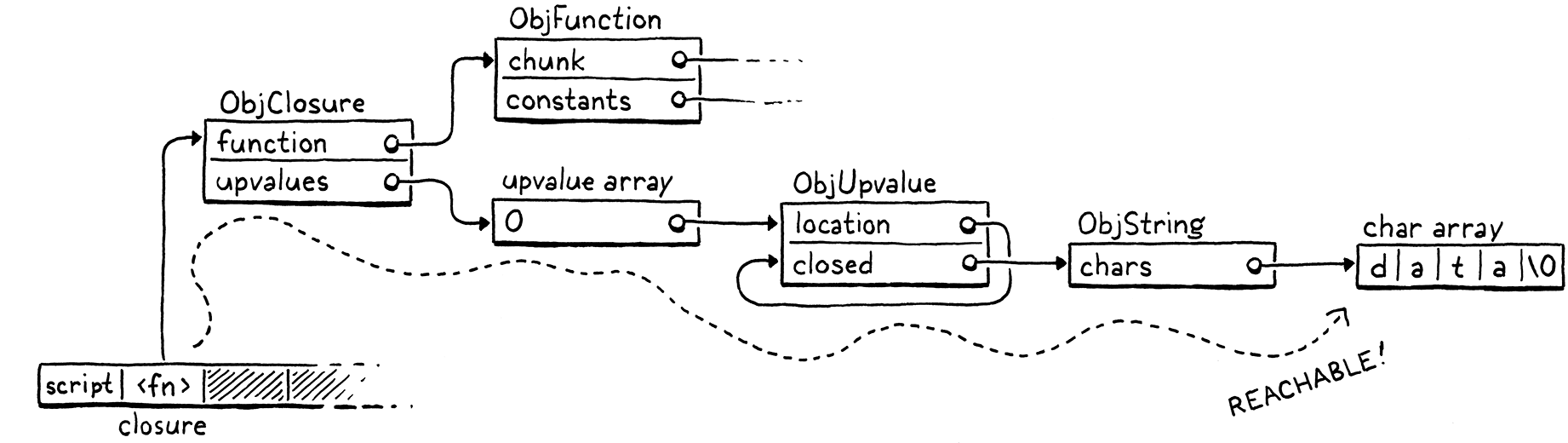
這給了我們一個可達性的歸納定義
-
所有根都是可達的。
-
從可達物件參照的任何物件本身都是可達的。
這些是仍然「活動」且需要保留在記憶體中的值。任何不符合此定義的值都可以被收集器收割。那對遞迴規則暗示我們可以使用的遞迴演算法來釋放不必要的記憶體
-
從根開始,遍歷物件參照以找到完整的可達物件集合。
-
釋放不在該集合中的所有物件。
現今使用許多不同的垃圾回收演算法,但它們大致都遵循相同的結構。有些可能會交錯步驟或混合步驟,但兩種基本操作都存在。它們的主要區別在於它們如何執行每個步驟。
26.2標記-清除垃圾回收
第一種受管理語言是 Lisp,它是繼 Fortran 之後發明的第二種「高階」語言。John McCarthy 考慮使用手動記憶體管理或參照計數,但最終決定使用(並創造了)垃圾回收—一旦程式記憶體不足,它就會回去尋找可以回收的未使用的儲存空間。
他設計了第一個、最簡單的垃圾回收演算法,稱為標記-清除或簡稱為標記-清除。它在最初關於 Lisp 的論文中的描述僅有三個簡短的段落。儘管它歷史悠久且簡單,但許多現代記憶體管理器的基本演算法都相同。電腦科學的某些角落似乎是永恆的。
顧名思義,標記-清除分兩個階段執行
-
標記:我們從根開始,並遍歷或追蹤這些根參照的所有物件。這是所有可達物件的經典圖形遍歷。每次我們訪問一個物件時,我們都會以某種方式標記它。(實作在如何記錄標記方面有所不同。)
-
清除:一旦標記階段完成,堆積中的每個可達物件都已標記。這表示任何未標記的物件都是無法達到的,並且可以回收。我們走訪所有未標記的物件並釋放每一個物件。
它看起來像這樣
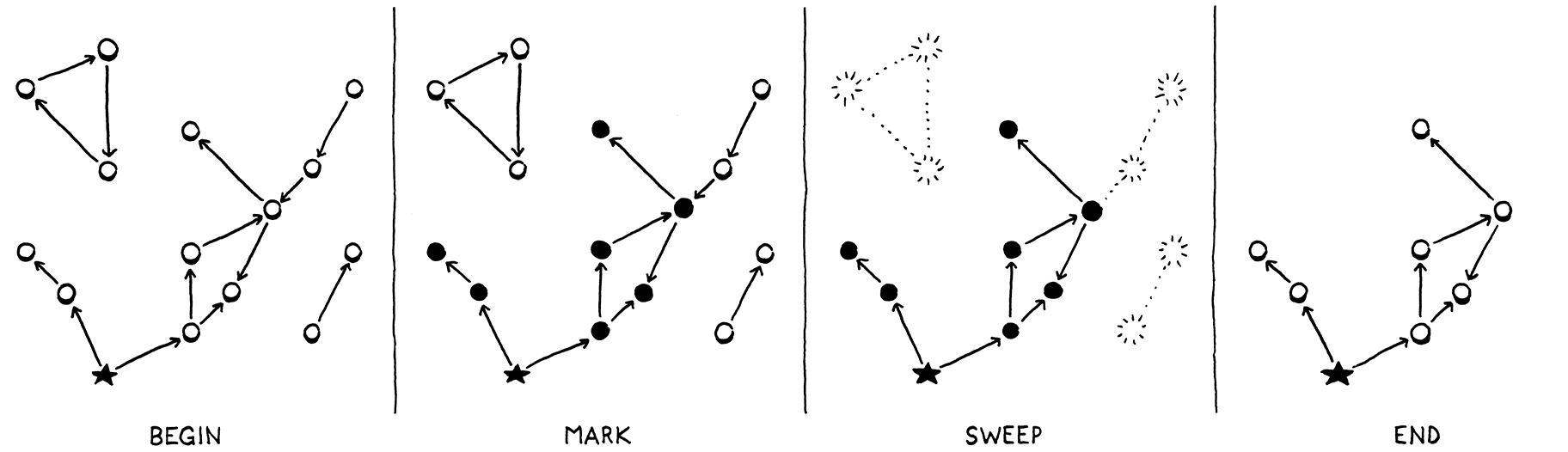
這就是我們要實作的。每當我們決定要回收一些位元組時,我們都會追蹤所有內容並標記所有可達物件,釋放未標記的物件,然後繼續使用者的程式。
26.2.1收集垃圾
本章的全部內容都是關於實作這個函式
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
在 reallocate() 之後新增
void collectGarbage();
void freeObjects();
我們將從這個空的殼開始,逐步完成完整的實作
在 freeObject() 之後加入
void collectGarbage() { }
你可能會問的第一個問題是,這個函式何時被呼叫?事實證明,這是一個微妙的問題,我們將在本章稍後花一些時間探討。現在,我們先避開這個問題,並在這個過程中建立一個方便的診斷工具。
#define DEBUG_TRACE_EXECUTION
#define DEBUG_STRESS_GC
#define UINT8_COUNT (UINT8_MAX + 1)
我們將為垃圾收集器加入一個可選的「壓力測試」模式。當定義這個標誌時,GC 會盡可能頻繁地執行。顯然,這對效能來說是可怕的。但它對於找出僅在 GC 在正確的時間點被觸發時才會發生的記憶體管理錯誤非常有用。如果每個時刻都觸發 GC,你很可能會發現這些錯誤。
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
在 reallocate() 中
if (newSize > oldSize) { #ifdef DEBUG_STRESS_GC collectGarbage(); #endif }
if (newSize == 0) {
每當我們呼叫 reallocate() 來取得更多記憶體時,我們都會強制執行一次垃圾收集。if 檢查是因為 reallocate() 也會被呼叫來釋放或縮減分配。我們不希望為此觸發 GC—特別是因為 GC 本身會呼叫 reallocate() 來釋放記憶體。
在分配之前立即收集是將 GC 連接到 VM 的經典方法。你已經在呼叫記憶體管理器,所以這是一個很容易掛鉤程式碼的地方。此外,分配是唯一真正需要一些釋放記憶體以便可以重複使用的時候。如果你沒有使用分配來觸發 GC,你必須確保程式碼中每個可以循環並分配記憶體的地方也都有一種觸發收集器的方法。否則,VM 可能會進入一種匱乏狀態,它需要更多記憶體但從未收集任何記憶體。
26 . 2 . 2除錯日誌
既然我們正在討論診斷,讓我們加入更多診斷功能。我發現垃圾收集器的一個真正的挑戰是它們是不透明的。到目前為止,我們一直在沒有任何 GC 的情況下正常執行許多 Lox 程式。一旦我們加入一個,我們如何判斷它是否有做任何有用的事情?我們是否只有在編寫耗用大量記憶體的程式時才能判斷出來?我們如何除錯它?
一種照亮 GC 內部運作的簡單方法是使用一些日誌記錄。
#define DEBUG_STRESS_GC
#define DEBUG_LOG_GC
#define UINT8_COUNT (UINT8_MAX + 1)
啟用後,clox 會在它對動態記憶體執行某些操作時將資訊列印到主控台。
我們需要一些包含檔。
#include "vm.h"
#ifdef DEBUG_LOG_GC #include <stdio.h> #include "debug.h" #endif
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
我們還沒有收集器,但我們現在可以開始加入一些日誌記錄。我們會想知道何時開始執行收集。
void collectGarbage() {
在 collectGarbage() 中
#ifdef DEBUG_LOG_GC printf("-- gc begin\n"); #endif
}
最終我們會在收集期間記錄其他一些操作,因此我們也會想知道何時結束。
printf("-- gc begin\n");
#endif
在 collectGarbage() 中
#ifdef DEBUG_LOG_GC printf("-- gc end\n"); #endif
}
我們還沒有收集器的任何程式碼,但我們有分配和釋放的函式,所以我們現在可以對它們進行檢測。
vm.objects = object;
在 allocateObject() 中
#ifdef DEBUG_LOG_GC printf("%p allocate %zu for %d\n", (void*)object, size, type); #endif
return object;
以及在物件生命週期的結尾
static void freeObject(Obj* object) {
在 freeObject() 中
#ifdef DEBUG_LOG_GC printf("%p free type %d\n", (void*)object, object->type); #endif
switch (object->type) {
有了這兩個標誌,我們應該能夠看到,當我們完成本章的其餘部分時,我們正在取得進展。
26 . 3標記根
物件分散在堆積中,就像漆黑夜空中的星星一樣。從一個物件到另一個物件的引用形成連接,這些星群是標記階段遍歷的圖形。標記從根開始。
#ifdef DEBUG_LOG_GC
printf("-- gc begin\n");
#endif
在 collectGarbage() 中
markRoots();
#ifdef DEBUG_LOG_GC
大多數根是直接位於 VM 堆疊中的局部變數或暫時變數,所以我們先遍歷它。
在 freeObject() 之後加入
static void markRoots() { for (Value* slot = vm.stack; slot < vm.stackTop; slot++) { markValue(*slot); } }
為了標記 Lox 值,我們使用這個新函式
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
在 reallocate() 之後新增
void markValue(Value value);
void collectGarbage();
它的實作在這裡
在 reallocate() 之後新增
void markValue(Value value) { if (IS_OBJ(value)) markObject(AS_OBJ(value)); }
一些 Lox 值—數字、布林值和 nil—直接內嵌儲存在 Value 中,不需要堆積分配。垃圾收集器完全不需要擔心它們,所以我們做的第一件事是確保該值是一個實際的堆積物件。如果是這樣,真正的工作發生在這個函式中
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
在 reallocate() 之後新增
void markObject(Obj* object);
void markValue(Value value);
它在這裡定義
在 reallocate() 之後新增
void markObject(Obj* object) { if (object == NULL) return; object->isMarked = true; }
當從 markValue() 呼叫時,NULL 檢查是不必要的。屬於某種 Obj 類型的 Lox Value 將始終具有有效的指標。但稍後我們將直接從其他程式碼呼叫此函式,並且在其中一些位置,所指向的物件是可選的。
假設我們有一個有效的物件,我們透過設定標誌來標記它。那個新欄位存在於所有物件共用的 Obj 標頭結構中。
ObjType type;
在結構 Obj 中
bool isMarked;
struct Obj* next;
每個新物件的生命都以未標記狀態開始,因為我們尚未確定它是可到達還是不可到達。
object->type = type;
在 allocateObject() 中
object->isMarked = false;
object->next = vm.objects;
在我們進一步深入之前,讓我們在 markObject() 中加入一些日誌記錄。
void markObject(Obj* object) {
if (object == NULL) return;
在 markObject() 中
#ifdef DEBUG_LOG_GC printf("%p mark ", (void*)object); printValue(OBJ_VAL(object)); printf("\n"); #endif
object->isMarked = true;
這樣我們就可以看到標記階段正在做什麼。標記堆疊負責局部變數和暫時變數。另一個主要的根來源是全域變數。
markValue(*slot); }
在 markRoots() 中
markTable(&vm.globals);
}
它們存在於 VM 擁有的雜湊表中,因此我們將宣告另一個輔助函式來標記表中的所有物件。
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash);
在 tableFindString() 之後加入
void markTable(Table* table);
#endif
我們在「table」模組中實作它
在 tableFindString() 之後加入
void markTable(Table* table) { for (int i = 0; i < table->capacity; i++) { Entry* entry = &table->entries[i]; markObject((Obj*)entry->key); markValue(entry->value); } }
非常簡單。我們遍歷條目陣列。對於每個條目,我們標記它的值。我們還會標記每個條目的鍵字串,因為 GC 也會管理這些字串。
26 . 3 . 1較不明顯的根
這些涵蓋了我們通常想到的根—明顯可到達的值,因為它們儲存在使用者程式可以看到的變數中。但是 VM 有一些自己的隱藏處,它會在其中儲存它直接存取的值的引用。
大多數函式呼叫狀態存在於值堆疊中,但 VM 維護一個單獨的 CallFrame 堆疊。每個 CallFrame 都包含一個指向被呼叫閉包的指標。VM 使用這些指標來存取常數和向上值,所以這些閉包也需要保留下來。
}
在 markRoots() 中
for (int i = 0; i < vm.frameCount; i++) { markObject((Obj*)vm.frames[i].closure); }
markTable(&vm.globals);
說到向上值,開啟的向上值列表是 VM 可以直接到達的另一組值。
for (int i = 0; i < vm.frameCount; i++) {
markObject((Obj*)vm.frames[i].closure);
}
在 markRoots() 中
for (ObjUpvalue* upvalue = vm.openUpvalues; upvalue != NULL; upvalue = upvalue->next) { markObject((Obj*)upvalue); }
markTable(&vm.globals);
還要記住,收集可以在任何分配期間開始。這些分配不僅在使用者程式執行時發生。編譯器本身會定期從堆積中取得記憶體來用於文字和常數表。如果 GC 在我們正在編譯的過程中執行,那麼編譯器直接存取的任何值也需要被視為根。
為了保持編譯器模組與 VM 的其餘部分乾淨地分離,我們將在單獨的函式中執行此操作。
markTable(&vm.globals);
在 markRoots() 中
markCompilerRoots();
}
它在這裡宣告
ObjFunction* compile(const char* source);
在 compile() 之後加入
void markCompilerRoots();
#endif
這表示「memory」模組需要一個包含檔。
#include <stdlib.h>
#include "compiler.h"
#include "memory.h"
定義在「compiler」模組中。
在 compile() 之後加入
void markCompilerRoots() { Compiler* compiler = current; while (compiler != NULL) { markObject((Obj*)compiler->function); compiler = compiler->enclosing; } }
幸運的是,編譯器沒有太多它掛起的值。它使用的唯一物件是它正在編譯成的 ObjFunction。由於函式宣告可以巢狀,編譯器有一個這些的連結列表,我們遍歷整個列表。
由於「compiler」模組正在呼叫 markObject(),因此它也需要一個包含檔。
#include "compiler.h"
#include "memory.h"
#include "scanner.h"
這些是所有的根。執行此操作後,VM—執行階段和編譯器—可以在不經過其他物件的情況下到達的每個物件都會設定其標記位元。
26 . 4追蹤物件引用
標記過程的下一步是追蹤物件之間的引用圖形,以找出間接可到達的值。我們還沒有帶有欄位的實例,所以沒有太多包含引用的物件,但我們確實有一些。特別是,ObjClosure 具有它關閉的 ObjUpvalue 列表,以及它包裹的原始 ObjFunction 的引用。ObjFunction 反過來又有一個常數表,其中包含對函式主體中建立的所有文字的引用。這足以建立一個相當複雜的物件網,供我們的收集器遍歷。
現在是時候實作該遍歷了。我們可以進行廣度優先、深度優先或其他順序。由於我們只需要找到所有可到達物件的集合,因此我們拜訪它們的順序大多數情況下並不重要。
26 . 4 . 1三色抽象
當收集器在物件圖形中遊走時,我們需要確保它不會迷失方向或陷入循環。對於進階的實作(例如將標記與執行使用者程式片段交錯進行的增量 GC)來說,這尤其令人擔憂。收集器需要能夠暫停,然後稍後從它停止的地方繼續。
為了幫助我們這些腦袋簡單的人理解這個複雜的過程,VM 駭客們提出了一個稱為三色抽象的比喻。每個物件都有一個概念上的「顏色」,用於追蹤物件的狀態以及剩餘要完成的工作。
-
 白色:在垃圾收集開始時,每個物件都是白色的。此顏色表示我們根本沒有到達或處理物件。
白色:在垃圾收集開始時,每個物件都是白色的。此顏色表示我們根本沒有到達或處理物件。 -
 灰色:在標記期間,當我們第一次到達一個物件時,我們將其變暗為灰色。此顏色表示我們知道物件本身是可到達的,不應被收集。但是我們尚未追蹤它來查看它引用了哪些其他物件。在圖形演算法術語中,這是工作列表—我們知道但尚未處理的物件集合。
灰色:在標記期間,當我們第一次到達一個物件時,我們將其變暗為灰色。此顏色表示我們知道物件本身是可到達的,不應被收集。但是我們尚未追蹤它來查看它引用了哪些其他物件。在圖形演算法術語中,這是工作列表—我們知道但尚未處理的物件集合。 -
 黑色:當我們取得一個灰色物件並標記它引用的所有物件時,我們然後將灰色物件變為黑色。此顏色表示標記階段已完成處理該物件。
黑色:當我們取得一個灰色物件並標記它引用的所有物件時,我們然後將灰色物件變為黑色。此顏色表示標記階段已完成處理該物件。
就該抽象而言,標記過程現在看起來像這樣
-
從所有白色物件開始。
-
找出所有根並將它們標記為灰色。
-
只要還有灰色物件,就重複執行
-
選擇一個灰色物件。將該物件提到的任何白色物件都變為灰色。
-
將原始的灰色物件標記為黑色。
-
我發現這有助於視覺化。你有一個物件網路,物件之間有引用。最初,它們都是白色小點。旁邊有一些來自 VM 的傳入邊,指向根。這些根變為灰色。然後,每個灰色物件的同層物件變為灰色,而物件本身變為黑色。完整的效果是,一個灰色波陣面穿過圖形,在其後留下一片可到達的黑色物件。無法到達的物件不會被波陣面觸及,並保持白色。

在最後,你會看到一片已觸及的黑色物件,其中散佈著可以被清除並釋放的白色物件島嶼。一旦無法觸及的物件被釋放後,剩下的物件—全部都是黑色—會被重置為白色,以便進行下一次的垃圾回收週期。
26 . 4 . 2用於灰色物件的工作清單
在我們的實作中,我們已經標記了根物件。它們都是灰色的。下一步是開始選取它們並遍歷它們的參考。但是我們沒有任何簡單的方法可以找到它們。我們在物件上設定了一個欄位,就這樣而已。我們不希望必須遍歷整個物件列表來尋找設定了該欄位的物件。
取而代之的是,我們將建立一個獨立的工作清單,以追蹤所有灰色物件。當物件變成灰色時,除了設定標記欄位外,我們也會將其新增至工作清單中。
object->isMarked = true;
在 markObject() 中
if (vm.grayCapacity < vm.grayCount + 1) { vm.grayCapacity = GROW_CAPACITY(vm.grayCapacity); vm.grayStack = (Obj**)realloc(vm.grayStack, sizeof(Obj*) * vm.grayCapacity); } vm.grayStack[vm.grayCount++] = object;
}
我們可以利用任何可以輕鬆放入和取出項目的資料結構。我選擇了堆疊,因為它是用 C 中的動態陣列實作最簡單的。它運作方式與我們在 Lox 中建立的其他動態陣列大致相同,除了,請注意它呼叫的是系統的 realloc() 函式,而不是我們自己的 reallocate() 包裝函式。灰色堆疊本身的記憶體並不是由垃圾回收器管理的。我們不希望在 GC 期間擴展灰色堆疊導致 GC 遞迴地啟動新的 GC。這可能會在時空連續體中撕裂一個洞。
我們將自行明確地管理其記憶體。虛擬機器 (VM) 擁有灰色堆疊。
Obj* objects;
在 VM 結構中
int grayCount; int grayCapacity; Obj** grayStack;
} VM;
它一開始是空的。
vm.objects = NULL;
在 initVM() 中
vm.grayCount = 0; vm.grayCapacity = 0; vm.grayStack = NULL;
initTable(&vm.globals);
當 VM 關閉時,我們需要釋放它。
object = next; }
在 freeObjects() 中
free(vm.grayStack);
}
我們對這個陣列負完全責任。這包括配置失敗。如果我們無法建立或擴展灰色堆疊,那麼我們就無法完成垃圾回收。這對 VM 來說是壞消息,但幸運的是這種情況很少發生,因為灰色堆疊往往很小。如果能做一些更優雅的事情會更好,但為了讓本書中的程式碼保持簡單,我們就直接中止。
vm.grayStack = (Obj**)realloc(vm.grayStack,
sizeof(Obj*) * vm.grayCapacity);
在 markObject() 中
if (vm.grayStack == NULL) exit(1);
}
26 . 4 . 3處理灰色物件
好的,現在當我們完成標記根物件時,我們既設定了一堆欄位,又用要處理的物件填滿了我們的工作清單。現在是進入下一階段的時候了。
markRoots();
在 collectGarbage() 中
traceReferences();
#ifdef DEBUG_LOG_GC
這是實作
在 markRoots() 之後新增
static void traceReferences() { while (vm.grayCount > 0) { Obj* object = vm.grayStack[--vm.grayCount]; blackenObject(object); } }
它盡可能接近文字演算法。在堆疊清空之前,我們會不斷取出灰色物件、遍歷它們的參考,然後將它們標記為黑色。遍歷物件的參考可能會找出新的白色物件,這些物件會被標記為灰色並新增至堆疊。因此,這個函式會在將白色物件變成灰色和將灰色物件變成黑色之間來回切換,逐步推進整個波前向前移動。
這是我們遍歷單一物件參考的地方
在 markValue() 之後新增
static void blackenObject(Obj* object) { switch (object->type) { case OBJ_NATIVE: case OBJ_STRING: break; } }
每個物件種類都有不同的欄位可能會參考其他物件,因此我們需要針對每個類型使用特定的程式碼區塊。我們先從簡單的開始—字串和原生函式物件不包含任何輸出參考,因此無需遍歷。
請注意,我們沒有在遍歷的物件本身中設定任何狀態。物件的狀態中沒有直接編碼「黑色」。黑色物件是指 isMarked 欄位被設定且不再灰色堆疊中的任何物件。
現在讓我們開始新增其他物件類型。最簡單的是向上值 (upvalue)。
static void blackenObject(Obj* object) {
switch (object->type) {
在 blackenObject() 中
case OBJ_UPVALUE: markValue(((ObjUpvalue*)object)->closed); break;
case OBJ_NATIVE:
當向上值關閉時,它會包含對關閉的值的參考。由於該值不再堆疊上,因此我們需要確保從向上值追蹤到它的參考。
接下來是函式。
switch (object->type) {
在 blackenObject() 中
case OBJ_FUNCTION: { ObjFunction* function = (ObjFunction*)object; markObject((Obj*)function->name); markArray(&function->chunk.constants); break; }
case OBJ_UPVALUE:
每個函式都有一個對包含函式名稱的 ObjString 的參考。更重要的是,函式有一個常數表格,其中塞滿了對其他物件的參考。我們使用這個輔助函式追蹤所有這些參考
在 markValue() 之後新增
static void markArray(ValueArray* array) { for (int i = 0; i < array->count; i++) { markValue(array->values[i]); } }
我們現在擁有的最後一個物件類型—我們將在後續章節中新增更多—是閉包。
switch (object->type) {
在 blackenObject() 中
case OBJ_CLOSURE: { ObjClosure* closure = (ObjClosure*)object; markObject((Obj*)closure->function); for (int i = 0; i < closure->upvalueCount; i++) { markObject((Obj*)closure->upvalues[i]); } break; }
case OBJ_FUNCTION: {
每個閉包都有一個對它所包裝的原始函式的參考,以及一個指向它所捕獲的向上值的指標陣列。我們追蹤所有這些。
這是處理灰色物件的基本機制,但還有兩個未完成的地方需要處理。首先是一些記錄。
static void blackenObject(Obj* object) {
在 blackenObject() 中
#ifdef DEBUG_LOG_GC printf("%p blacken ", (void*)object); printValue(OBJ_VAL(object)); printf("\n"); #endif
switch (object->type) {
這樣一來,我們可以觀察追蹤如何滲透到物件圖中。說到這裡,請注意我說的是圖。物件之間的參考是有方向性的,但這並不表示它們是非循環的!物件完全有可能形成循環。當這種情況發生時,我們需要確保我們的收集器不會卡在無限迴圈中,因為它會不斷將相同的物件序列重新新增至灰色堆疊。
解決方法很簡單。
if (object == NULL) return;
在 markObject() 中
if (object->isMarked) return;
#ifdef DEBUG_LOG_GC
如果物件已經被標記,我們就不會再次標記它,因此不會將它新增至灰色堆疊。這可確保已經是灰色的物件不會被多餘地新增,而黑色物件不會被不小心變回灰色。換句話說,它可以讓波前僅在白色物件中向前移動。
26 . 5清除未使用的物件
當 traceReferences() 中的迴圈結束時,我們已經處理了所有我們可以取得的物件。灰色堆疊是空的,而且堆積中的每個物件不是黑色就是白色。黑色物件是可觸及的,我們希望保留它們。任何仍然是白色的物件從未被追蹤觸及,因此是垃圾。剩下的就是回收它們。
traceReferences();
在 collectGarbage() 中
sweep();
#ifdef DEBUG_LOG_GC
所有的邏輯都存在於一個函式中。
在 traceReferences() 之後新增
static void sweep() { Obj* previous = NULL; Obj* object = vm.objects; while (object != NULL) { if (object->isMarked) { previous = object; object = object->next; } else { Obj* unreached = object; object = object->next; if (previous != NULL) { previous->next = object; } else { vm.objects = object; } freeObject(unreached); } } }
我知道這有點多程式碼和指標操作,但一旦你理解它,就沒什麼難的了。外部 while 迴圈會走訪堆積中每個物件的連結清單,並檢查它們的標記位元。如果物件已標記(黑色),我們會保持它不變並繼續略過它。如果物件未標記(白色),我們會將它從清單中取消連結,並使用我們已經撰寫的 freeObject() 函式來釋放它。
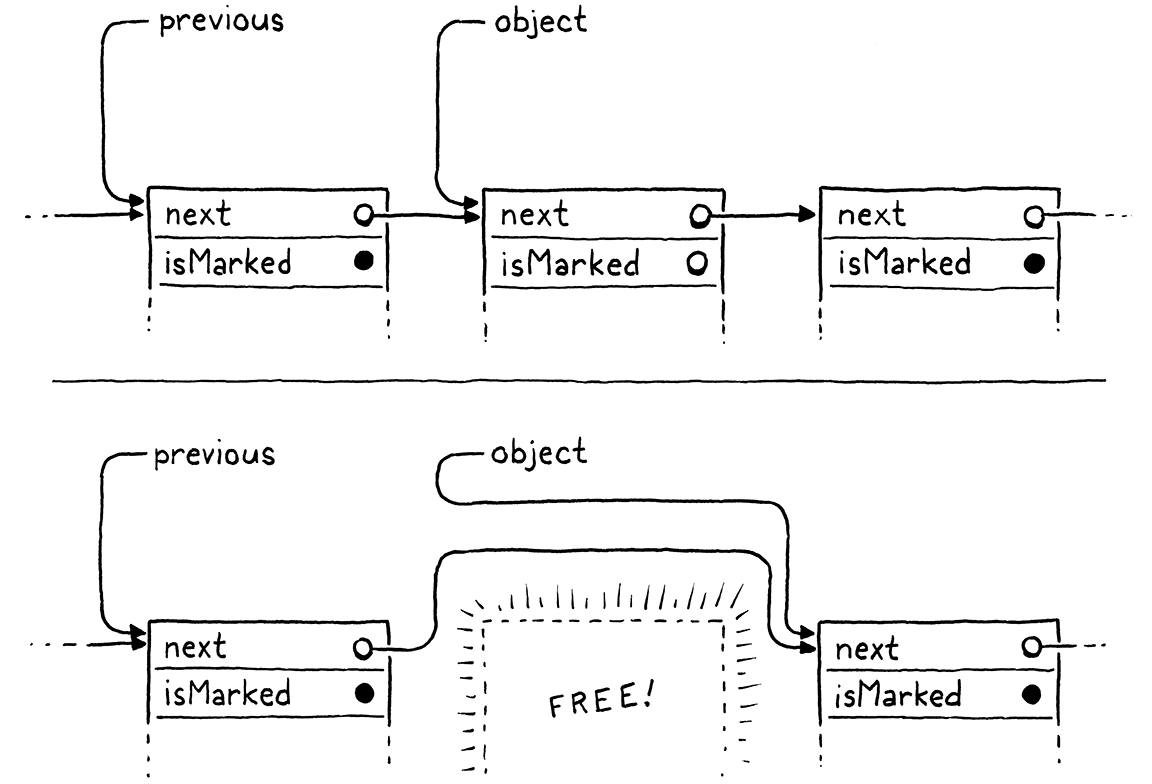
這裡的大部分其他程式碼都在處理從單向連結清單中移除節點很麻煩的事實。我們必須持續記住前一個節點,才能取消連結其下一個指標,而且我們必須處理釋放第一個節點的邊緣情況。但除此之外,它非常簡單—刪除連結清單中所有沒有設定位元的節點。
還有一個小小的新增
if (object->isMarked) {
在 sweep() 中
object->isMarked = false;
previous = object;
在 sweep() 完成後,剩下的物件都是已設定標記位元的有效黑色物件。這是正確的,但當下一個收集週期開始時,我們需要每個物件都是白色。因此,每當我們觸及黑色物件時,我們都會立即清除位元,以準備進行下一次執行。
26 . 5 . 1弱參考和字串池
我們快要完成收集了。VM 中還有一個角落在記憶體周圍有一些不尋常的需求。回想一下,當我們將字串新增至 clox 時,我們讓 VM 將它們全部內部化。這表示 VM 有一個雜湊表,其中包含指向堆積中每個字串的指標。VM 使用它來消除重複的字串。
在標記階段,我們刻意沒有將 VM 的字串表視為根物件的來源。如果我們這樣做,就永遠不會收集任何字串。字串表將會不斷增長,而永遠不會將任何位元組的記憶體釋放回作業系統。這樣會很糟糕。
同時,如果我們真的讓 GC 釋放字串,那麼 VM 的字串表將會留下指向已釋放記憶體的懸空指標。這會更糟。
字串表很特殊,我們需要針對它提供特殊的支援。尤其是,它需要一種特殊的參考。該表格應該能夠參考字串,但在判斷可觸及性時,該連結不應被視為根物件。這表示可以釋放所參考的物件。當這種情況發生時,也必須修復懸空參考,就像一個神奇的、會自動清除的指標一樣。這種特殊的一組語意經常出現,因此它有一個名稱:弱參考。
我們已經隱式地實作了字串表一半的獨特行為,因為我們在標記期間不會遍歷它。這表示它不會強迫字串是可觸及的。剩下的部分是清除已釋放字串的所有懸空指標。
為了移除對無法觸及字串的參考,我們需要知道哪些字串是無法觸及的。直到標記階段完成後,我們才會知道。但我們不能等到清除階段完成後,因為到那時,物件—及其標記位元—就不再存在可以檢查了。因此,正確的時間正好是在標記和清除階段之間。
traceReferences();
在 collectGarbage() 中
tableRemoveWhite(&vm.strings);
sweep();
用於移除即將被刪除字串的邏輯存在於「表格」模組中的新函式中。
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash);
在 tableFindString() 之後加入
void tableRemoveWhite(Table* table);
void markTable(Table* table);
實作在這裡
在 tableFindString() 之後加入
void tableRemoveWhite(Table* table) { for (int i = 0; i < table->capacity; i++) { Entry* entry = &table->entries[i]; if (entry->key != NULL && !entry->key->obj.isMarked) { tableDelete(table, entry->key); } } }
我們走訪表格中的每一個條目。字串內部表格只使用每個條目的鍵—它基本上是一個雜湊集合,而不是雜湊映射。如果鍵字串物件的標記位元未設定,那麼它就是一個即將被清除的白色物件。我們會先將它從雜湊表格中刪除,以確保我們不會看到任何懸空的指標。
26 . 6何時進行回收
我們現在有一個功能完整的標記-清除垃圾收集器。當壓力測試標誌啟用時,它會一直被呼叫,並且啟用日誌記錄時,我們可以觀察它執行並看到它確實正在回收記憶體。但是,當壓力測試標誌關閉時,它根本不會執行。現在是決定在正常程式執行期間何時應調用收集器的時機了。
就我所知,文獻對這個問題的解答並不充分。當垃圾收集器剛被發明時,電腦的記憶體容量很小且固定。許多早期的 GC 論文假設你撥出幾千個字的記憶體—換句話說,大部分的記憶體—並在記憶體用盡時調用收集器。很簡單。
現代機器擁有數 GB 的實體 RAM,隱藏在作業系統更大的虛擬記憶體抽象之下,這些記憶體在許多其他程式之間共享,這些程式都在爭奪它們的記憶體區塊。作業系統會讓你的程式請求它想要多少就多少,然後在實體記憶體滿時從磁碟分頁進出。你永遠不會真正「用完」記憶體,你只會越來越慢。
26 . 6 . 1延遲和吞吐量
等待到你「不得不」運行 GC 已經沒有意義了,所以我們需要一個更精細的時機策略。為了更精確地推理這個問題,現在是時候介紹兩個在衡量記憶體管理器效能時使用的基本數字:吞吐量和延遲。
與顯式、使用者撰寫的釋放相比,每種受管理的語言都會付出效能代價。實際釋放記憶體所花費的時間是相同的,但是 GC 會花費週期來找出哪些記憶體要釋放。這段時間沒有花在執行使用者的程式和執行有用的工作上。在我們的實作中,那就是標記階段的全部。一個複雜的垃圾收集器的目標是將這種開銷降到最低。
我們可以使用兩個關鍵指標來更好地理解這個成本
-
吞吐量是執行使用者程式所花費的時間與執行垃圾收集工作所花費的時間的總比例。假設你執行一個 clox 程式十秒鐘,其中一秒鐘花在
collectGarbage()內。這表示吞吐量是 90%—它將 90% 的時間花在執行程式上,而 10% 花在 GC 開銷上。吞吐量是最基本的衡量標準,因為它可以追蹤收集開銷的總成本。在所有其他條件相同的情況下,你希望最大化吞吐量。直到本章為止,clox 完全沒有 GC,因此吞吐量為 100%。這很難被擊敗。當然,它帶來了一點潛在的風險,如果使用者的程式執行時間夠長,可能會用完記憶體並崩潰。你可以將 GC 的目標視為修復這個「小故障」,同時盡可能減少吞吐量的犧牲。
-
延遲是使用者程式在垃圾收集期間完全暫停的最長連續時間段。它是衡量收集器「塊狀」程度的指標。延遲與吞吐量是完全不同的指標。
考慮兩個 clox 程式的執行,它們都花費十秒鐘。在第一次執行中,GC 啟動一次,並在一次大規模的收集中花費整整一秒鐘在
collectGarbage()中。在第二次執行中,GC 被調用五次,每次五分之一秒。收集所花費的總時間仍然是一秒鐘,因此在這兩種情況下,吞吐量均為 90%。但是在第二次執行中,延遲僅為五分之一秒,比第一次執行少五倍。
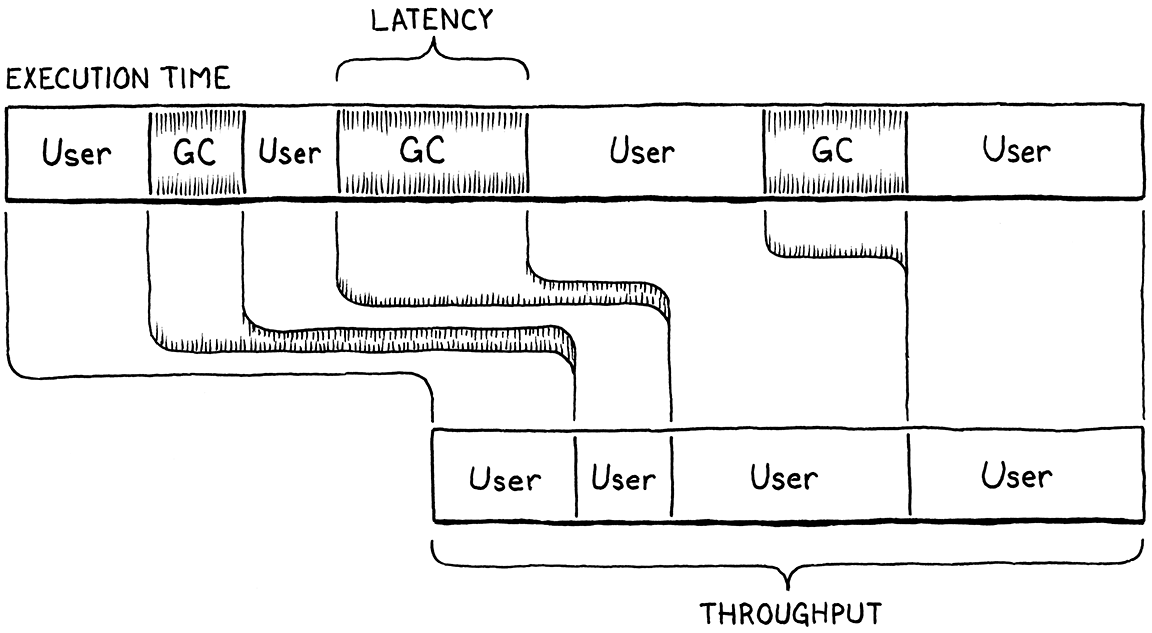
如果你喜歡類比,想像你的程式是一家向顧客銷售新鮮麵包的麵包店。吞吐量是你在一天內可以為顧客提供多少條溫熱、酥脆的長棍麵包。延遲是最倒霉的顧客在被服務之前必須排隊等待的時間。
運行垃圾收集器就像暫時關閉麵包店,整理所有的餐具,將髒的與乾淨的分開,然後清洗用過的餐具。在我們的類比中,我們沒有專門的洗碗機,因此在這種情況下,沒有人在烘烤。麵包師正在洗碗。
每天賣出更少的麵包是不好的,讓任何特定的顧客在您清洗所有餐具時坐著等待也是不好的。目標是最大化吞吐量並最小化延遲,但是即使在麵包店裡也沒有免費的午餐。垃圾收集器在他們犧牲多少吞吐量和容忍的延遲之間做出不同的權衡。
能夠做出這些權衡是有用的,因為不同的使用者程式有不同的需求。從 TB 數據中產生報表的夜間批次作業只需要盡可能快地完成盡可能多的工作。吞吐量是王道。同時,在使用者智慧型手機上運行的應用程式需要始終立即回應使用者輸入,以便在螢幕上拖曳感覺如奶油般順滑。應用程式不能在 GC 在堆積中亂搞時凍結幾秒鐘。
作為垃圾收集器的作者,你可以透過選擇收集演算法來控制吞吐量和延遲之間的一些權衡。但是即使在單一演算法中,我們也可以很好地控制收集器的執行頻率。
我們的收集器是一個停止世界 GC,這表示使用者的程式會暫停,直到整個垃圾收集過程完成。如果我們在運行收集器之前等待很長時間,則會累積大量的死物件。這會導致收集器運行時的暫停時間非常長,從而導致高延遲。因此,顯然,我們希望非常頻繁地運行收集器。
但是每次收集器執行時,它都會花一些時間走訪活動物件。這實際上沒有執行任何有用的操作(除了確保它們不會被錯誤地刪除之外)。走訪活動物件的時間是沒有釋放記憶體的時間,也是沒有執行使用者程式碼的時間。如果你非常頻繁地運行 GC,那麼使用者的程式甚至沒有足夠的時間產生新的垃圾供 VM 收集。VM 將把所有時間都花在反覆癡迷地走訪同一組活動物件上,吞吐量將會受到影響。因此,顯然,我們希望不頻繁地運行收集器。
實際上,我們想要中間的東西,而收集器的運行頻率是我們調整延遲和吞吐量之間權衡的主要旋鈕之一。
26 . 6 . 2自我調整堆積
我們希望我們的 GC 執行頻率足夠高,以最小化延遲,但又不會頻繁到足以維持良好的吞吐量。但是,當我們不知道使用者的程式需要多少記憶體以及它的分配頻率時,我們如何找到兩者之間的平衡?我們可以將問題推給使用者,並強迫他們透過公開 GC 調整參數來選擇。許多 VM 都這樣做。但是,如果我們(GC 作者)不知道如何好好調整它,那麼大多數使用者也不會。他們應該得到合理的預設行為。
我會坦白告訴你,這不是我的專業領域。我曾與許多專業的 GC 駭客交談過—這是你可以建立整個職業生涯的事情—並且閱讀了很多文獻,而我得到的所有答案都是 . . . 模糊不清的。我最終選擇的策略很常見,非常簡單,並且(我希望!)對於大多數用途來說都足夠好。
這個想法是,收集器頻率會根據堆積的活動大小自動調整。我們會追蹤 VM 已分配的受管理記憶體的總位元組數。當它超過某個閾值時,我們會觸發 GC。之後,我們記錄剩餘多少位元組的記憶體—有多少位元組沒有被釋放。然後,我們將閾值調整為大於該值的某個值。
結果是,隨著活動記憶體量的增加,我們會減少收集頻率,以避免因重複走訪不斷增長的活動物件堆疊而犧牲吞吐量。隨著活動記憶體量的減少,我們會更頻繁地收集,以便我們不會因等待太久而損失太多延遲。
該實作需要在 VM 中新增兩個簿記欄位。
ObjUpvalue* openUpvalues;
在 VM 結構中
size_t bytesAllocated; size_t nextGC;
Obj* objects;
第一個是 VM 已分配的受管理記憶體位元組數的執行總計。第二個是觸發下一次收集的閾值。我們在 VM 啟動時初始化它們。
vm.objects = NULL;
在 initVM() 中
vm.bytesAllocated = 0; vm.nextGC = 1024 * 1024;
vm.grayCount = 0;
此處的起始閾值是任意的。它類似於我們為各種動態陣列選擇的初始容量。目標是不要太快地觸發最初的幾個 GC,但也不要等待太久。如果我們有一些真實的 Lox 程式,我們可以分析這些程式來調整它。但是,由於我們擁有的只是一些玩具程式,所以我只是選擇了一個數字。
每次我們分配或釋放一些記憶體時,我們都會按該增量調整計數器。
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
在 reallocate() 中
vm.bytesAllocated += newSize - oldSize;
if (newSize > oldSize) {
當總計超過限制時,我們就會運行收集器。
collectGarbage(); #endif
在 reallocate() 中
if (vm.bytesAllocated > vm.nextGC) {
collectGarbage();
}
}
現在,最後,當使用者在沒有啟用隱藏診斷標誌的情況下運行程式時,我們的垃圾收集器實際上會執行某些操作。清除階段透過呼叫 reallocate() 來釋放物件,這會降低 bytesAllocated 的值,因此在收集完成後,我們知道剩餘多少活動位元組。我們會根據此調整下一個 GC 的閾值。
sweep();
在 collectGarbage() 中
vm.nextGC = vm.bytesAllocated * GC_HEAP_GROW_FACTOR;
#ifdef DEBUG_LOG_GC
閾值是堆積大小的倍數。這樣,隨著程式使用的記憶體量增長,閾值會進一步向外移動,以限制重新走訪較大活動集所花費的總時間。與本章中的其他數字一樣,縮放因數基本上是任意的。
#endif
#define GC_HEAP_GROW_FACTOR 2
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
您會在您的實作中調整這個設定,一旦您有一些真實的程式可以進行基準測試。現在,我們至少可以記錄一些我們有的統計數據。我們會先捕捉垃圾回收之前的堆積大小。
printf("-- gc begin\n");
在 collectGarbage() 中
size_t before = vm.bytesAllocated;
#endif
然後在最後印出結果。
printf("-- gc end\n");
在 collectGarbage() 中
printf(" collected %zu bytes (from %zu to %zu) next at %zu\n", before - vm.bytesAllocated, before, vm.bytesAllocated, vm.nextGC);
#endif
這樣我們就可以看到垃圾回收器在執行時完成了多少工作。
26 . 7垃圾回收的錯誤
理論上,我們現在都完成了。我們有一個垃圾回收器。它會定期啟動,回收它可以回收的東西,並留下剩餘的。如果這是一本典型的教科書,我們會拍拍手上的灰塵,沉浸在我們所創造的完美大理石建築的柔和光芒中。
但我旨在教您的不僅是程式語言的理論,還有時常痛苦的現實。我將翻開一根腐爛的木頭,向您展示它下面潛藏的那些令人厭惡的錯誤,而垃圾回收器的錯誤絕對是其中最噁心的無脊椎動物。
回收器的任務是釋放已死的物件並保留存活的物件。在這兩個方向上都容易犯錯。如果虛擬機未能釋放不需要的物件,它會慢慢洩漏記憶體。如果它釋放了正在使用的物件,使用者的程式將會存取到無效的記憶體。這些故障通常不會立即導致崩潰,這使得我們很難回溯時間以找到錯誤。
由於我們不知道回收器何時會執行,這使得情況變得更加困難。任何最終會分配一些記憶體的呼叫,都是虛擬機中可能發生回收的地方。這就像搶椅子遊戲。在任何時候,垃圾回收器都可能會停止音樂。我們想要保留的每一個堆積分配物件都需要快速找到一個椅子—被標記為根或以參考的形式儲存在其他物件中—在掃描階段來將它踢出遊戲之前。
虛擬機如何有可能稍後使用一個物件—連垃圾回收器本身都看不到的物件?虛擬機如何找到它?最常見的答案是透過儲存在 C 堆疊上某些局部變數中的指標。垃圾回收器會走訪虛擬機的值和 CallFrame 堆疊,但 C 堆疊對它來說是隱藏的。
在前幾章中,我們編寫了看似毫無意義的程式碼,將一個物件推入虛擬機的值堆疊,做一些工作,然後將其彈出。大多數時候,我說這是為了垃圾回收器的好處。現在您明白原因了。推入和彈出之間的程式碼可能會分配記憶體,因此可能會觸發垃圾回收。我們必須確保物件在值堆疊上,以便回收器的標記階段可以找到它並使其保持存活。
我在將 clox 實作拆分成章節並編寫散文之前,就已經完成了整個實作,因此我有充足的時間找到所有這些角落並清除大多數這些錯誤。我們在本章開頭放入的壓力測試程式碼和相當不錯的測試套件非常有幫助。
但我只修復了大多數的錯誤。我留下了一些,因為我想讓您體驗一下在野外遇到這些錯誤的感受。如果您啟用壓力測試標誌並執行一些玩具 Lox 程式,您可能會偶然發現一些。試一試,看看您是否可以自己修復任何錯誤。
26 . 7 . 1新增到常數表
您很可能會遇到第一個錯誤。每個區塊擁有的常數表是一個動態陣列。當編譯器將新常數新增到目前函數的表時,該陣列可能需要成長。常數本身也可能是一些堆積分配的物件,例如字串或巢狀函數。
被新增到常數表的新物件會傳遞給 addConstant()。在那一刻,只能在 C 堆疊上該函數的參數中找到該物件。該函數會將物件附加到常數表。如果該表沒有足夠的容量並且需要成長,它會呼叫 reallocate()。這反過來又會觸發垃圾回收,它會未能標記新的常數物件,因此在我們有機會將其新增到表之前就將其掃除了。崩潰。
正如您在其他地方看到的那樣,解決方法是將常數暫時推入堆疊。
int addConstant(Chunk* chunk, Value value) {
在 addConstant() 中
push(value);
writeValueArray(&chunk->constants, value);
一旦常數表包含物件,我們就會將其從堆疊中彈出。
writeValueArray(&chunk->constants, value);
在 addConstant() 中
pop();
return chunk->constants.count - 1;
當垃圾回收器標記根時,它會走訪編譯器的鏈並標記它們的每個函數,因此現在可以存取新的常數。我們確實需要一個 include 來從「區塊」模組呼叫到虛擬機。
#include "memory.h"
#include "vm.h"
void initChunk(Chunk* chunk) {
26 . 7 . 2字串的駐留
這是另一個類似的錯誤。所有字串都在 clox 中駐留,因此每當我們建立新字串時,我們也會將其新增到駐留表中。您可以看到這會往哪裡發展。由於字串是全新的,因此它在任何地方都無法存取。調整字串池的大小可能會觸發回收。同樣,我們先將字串儲存在堆疊中。
string->chars = chars; string->hash = hash;
在 allocateString() 中
push(OBJ_VAL(string));
tableSet(&vm.strings, string, NIL_VAL);
然後一旦它安全地安頓在表中,就將其彈出。
tableSet(&vm.strings, string, NIL_VAL);
在 allocateString() 中
pop();
return string; }
這確保了在調整表大小時字串是安全的。一旦它存活下來,allocateString() 就會將其傳回給某些呼叫者,然後呼叫者可以負責確保字串在下一次堆積分配發生之前仍然可以存取。
26 . 7 . 3串連字串
最後一個範例:在解譯器中,OP_ADD 指令可用於串連兩個字串。如同處理數字一樣,它會從堆疊中彈出兩個運算元,計算結果,然後將新的值推回到堆疊。對於數字來說,這是完全安全的。
但是串連兩個字串需要在堆積上分配一個新的字元陣列,這反過來又會觸發垃圾回收。由於我們在那個時間點已經彈出了運算元字串,它們可能會被標記階段遺漏並被掃除。我們不是急於將它們從堆疊中彈出,而是偷看它們。
static void concatenate() {
在 concatenate() 中
替換 2 行
ObjString* b = AS_STRING(peek(0)); ObjString* a = AS_STRING(peek(1));
int length = a->length + b->length;
這樣,當我們建立結果字串時,它們仍然保留在堆疊中。一旦完成,我們就可以安全地將它們彈出並用結果替換它們。
ObjString* result = takeString(chars, length);
在 concatenate() 中
pop(); pop();
push(OBJ_VAL(result));
這些都很簡單,特別是因為我向您展示了修復方法。實際上,找到它們才是困難的部分。您看到的只是一個應該在那裡但卻不存在的物件。這不像其他錯誤,您在尋找導致某些問題的程式碼。您在尋找未能阻止問題的程式碼的缺失,這是一個難得多的搜尋。
但是,至少現在,您可以安心休息了。據我所知,我們已經找到了 clox 中所有的回收錯誤,現在我們有一個運作正常、穩健、自我調整的標記掃描垃圾回收器。
挑戰
-
每個物件頂部的 Obj 標頭結構現在有三個欄位:
type、isMarked和next。這些欄位佔用多少記憶體(在您的機器上)?您可以提出更緊湊的方法嗎?這樣做是否會產生執行時間成本? -
當掃描階段遍歷一個存活物件時,它會清除
isMarked欄位,為下一個回收週期做準備。您可以提出更有效的方法嗎? -
標記掃描只是眾多垃圾回收演算法中的一種。透過使用另一個演算法來取代或增強目前的回收器來探索這些演算法。可以考慮的良好候選者包括參考計數、Cheney 演算法或 Lisp 2 標記壓縮演算法。
設計註解:世代回收器
如果回收器花費很長時間重新存取仍然存活的物件,它會損失吞吐量。但是,如果它避免回收並累積大量垃圾需要處理,則可能會增加延遲。如果有一種方法可以分辨哪些物件可能是長壽命的,哪些物件不是,那就太好了。然後,垃圾回收器可以避免經常重新存取長壽命的物件,並更頻繁地清除短暫的物件。
事實證明確實有一種方法。多年前,垃圾回收研究人員收集了現實世界中執行程式的物件生命週期指標。他們追蹤每個物件在分配時,以及最終在不再需要時,然後繪製出物件傾向於存活多久的圖表。
他們發現了一些被稱為世代假說或更不客氣的術語嬰兒死亡率的東西。他們的觀察是,大多數物件的壽命都很短,但一旦它們在超過一定年齡後存活下來,它們往往會持續很長時間。物件已經存活的時間越長,它繼續存活的可能性就越高。這個觀察結果非常強大,因為它讓他們能夠處理如何將物件劃分為適合頻繁回收和不適合頻繁回收的群組。
他們設計了一種稱為世代垃圾回收的技術。它的運作方式如下:每次分配新物件時,它都會進入堆積中一個特殊的、相對較小的區域,稱為「育嬰室」。由於物件往往很早就死亡,因此垃圾回收器會頻繁地在僅限於此區域的物件上呼叫。
每次對育嬰室執行垃圾回收都稱為「世代」。任何不再需要的物件都會被釋放。那些存活下來的物件現在被認為是老一輩的,垃圾回收器會追蹤每個物件的世代。如果一個物件在幾個世代中存活下來—通常只是一次回收—它就會被任用。此時,它會從育嬰室複製到一個更大的長壽命物件堆積區域。垃圾回收器也會在該區域執行,但頻率要低得多,因為大多數這些物件仍然存活的可能性很高。
世代回收器是經驗數據的完美結合—觀察到物件的生命週期不是均勻分佈的—以及利用這一事實的聰明演算法設計。它們在概念上也相當簡單。您可以將其視為兩個單獨調整的垃圾回收器,以及一個用於將物件從一個垃圾回收器移動到另一個垃圾回收器的非常簡單的策略。