閉包
正如俗語所說,對於每一個複雜的問題,都有一個簡單的解決方案,而且它是錯誤的。
翁貝托·艾可,《傅科擺》
感謝我們在上一章的辛勤勞動,我們擁有了一個能運作函式的虛擬機器。但它缺乏閉包的功能。除了全域變數(它們是另一種東西),函式沒有辦法引用在其自身主體之外宣告的變數。
var x = "global"; fun outer() { var x = "outer"; fun inner() { print x; } inner(); } outer();
現在執行這個範例,它會印出「global」。它應該要印出「outer」。為了修正這個問題,我們需要在解析變數時,包含所有周圍函式的整個詞法範圍。
在 clox 中,這個問題比在 jlox 中更難解決,因為我們的位元組碼 VM 將區域變數儲存在堆疊上。我們使用堆疊是因為我聲稱區域變數具有堆疊語意—變數會按照它們被建立的相反順序丟棄。但對於閉包來說,這僅在大多數情況下成立。
fun makeClosure() { var local = "local"; fun closure() { print local; } return closure; } var closure = makeClosure(); closure();
外部函式 makeClosure() 宣告了一個變數 local。它也建立了一個內部函式 closure() 來捕獲該變數。然後 makeClosure() 回傳對該函式的參考。由於閉包在保留區域變數的情況下逸出,因此 local 的壽命必須比它被建立的函式呼叫還要長。
我們可以透過為所有區域變數動態分配記憶體來解決這個問題。這就是 jlox 的做法,它將所有東西放在 Java 堆積中那些到處移動的 Environment 物件中。但我們不想這樣做。使用堆疊真的非常快。大多數區域變數並沒有被閉包捕獲,並且確實具有堆疊語意。為了少數被捕獲的區域變數而讓所有這些變數都變慢,這實在太糟糕了。
這表示我們需要比在 Java 直譯器中使用的更複雜的方法。因為某些區域變數的生命週期非常不同,我們將採用兩種實作策略。對於沒有在閉包中使用的區域變數,我們將保持它們在堆疊上的原樣。當區域變數被閉包捕獲時,我們將採用另一種解決方案,將它們提升到堆積上,以便它們可以在需要時存活。
閉包自早期的 Lisp 時代就存在了,當時記憶體和 CPU 週期的位元組比綠寶石還珍貴。在過去的幾十年中,駭客設計了各種方法來將閉包編譯為最佳化的執行階段表示形式。有些效率更高,但需要比我們能輕易改裝到 clox 中更複雜的編譯過程。
我在此解釋的技術來自 Lua VM 的設計。它速度快、節省記憶體,並且以相對較少的程式碼實現。更令人印象深刻的是,它自然地融入了 clox 和 Lua 都使用的單趟編譯器中。儘管如此,它有點複雜。可能需要一段時間才能將所有部分都融入您的腦海中。我們將逐步建立它們,並且我會嘗試分階段介紹這些概念。
25.1閉包物件
我們的 VM 在執行階段使用 ObjFunction 來表示函式。這些物件是由前端在編譯期間建立的。在執行階段,VM 所做的只是從常數表中載入函式物件並將其繫結到一個名稱。沒有在執行階段「建立」函式的操作。就像字串和數字字面值一樣,它們是純粹在編譯時實例化的常數。
這是合理的,因為構成函式的所有資料都在編譯時已知:從函式主體編譯的位元組碼區塊,以及在主體中使用的常數。但是,一旦我們引入閉包,這種表示形式就不再足夠了。看看
fun makeClosure(value) { fun closure() { print value; } return closure; } var doughnut = makeClosure("doughnut"); var bagel = makeClosure("bagel"); doughnut(); bagel();
makeClosure() 函式定義並回傳一個函式。我們呼叫它兩次並獲得兩個閉包。它們是由相同的巢狀函式宣告 closure 建立的,但會關閉不同的值。當我們呼叫這兩個閉包時,每個閉包都會印出不同的字串。這意味著我們需要閉包的某些執行階段表示形式,該表示形式會在函式宣告執行時捕獲函式周圍的區域變數,而不僅僅是在編譯時。
我們將逐步學習捕獲變數,但良好的第一步是定義該物件表示形式。我們現有的 ObjFunction 類型表示函式宣告的「原始」編譯時狀態,因為從單個宣告建立的所有閉包都共享相同的程式碼和常數。在執行階段,當我們執行函式宣告時,我們會將 ObjFunction 包裝在新的 ObjClosure 結構中。後者具有對基礎裸函式的參考,以及函式關閉的變數的執行階段狀態。
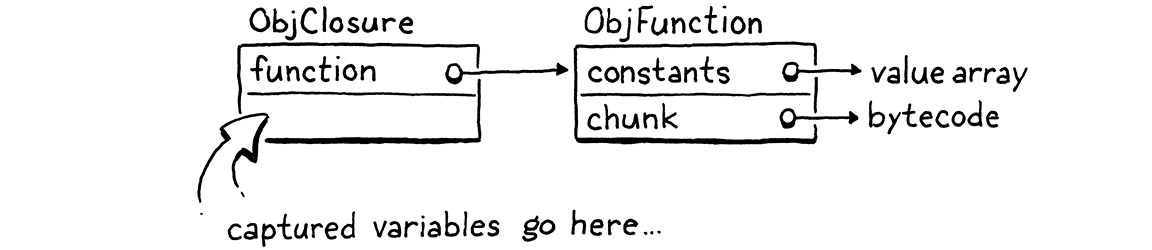
我們將把每個函式都包裝在 ObjClosure 中,即使該函式實際上沒有關閉和捕獲任何周圍的區域變數。這有點浪費,但它簡化了 VM,因為我們可以始終假設我們正在呼叫的函式是一個 ObjClosure。新的結構體從這裡開始
在 struct ObjString 之後新增
typedef struct { Obj obj; ObjFunction* function; } ObjClosure;
現在,它只是指向一個 ObjFunction 並新增必要的物件標頭內容。經過將新物件類型新增到 clox 的通常儀式後,我們宣告一個 C 函式來建立新的閉包。
} ObjClosure;
在 struct ObjClosure 之後新增
ObjClosure* newClosure(ObjFunction* function);
ObjFunction* newFunction();
然後我們在此實作它
在 allocateObject() 之後新增
ObjClosure* newClosure(ObjFunction* function) { ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE); closure->function = function; return closure; }
它接受一個指向它包裝的 ObjFunction 的指標。它也將 type 欄位初始化為新類型。
typedef enum {
在 enum ObjType 中
OBJ_CLOSURE,
OBJ_FUNCTION,
當我們使用完閉包時,我們會釋放它的記憶體。
switch (object->type) {
在 freeObject() 中
case OBJ_CLOSURE: { FREE(ObjClosure, object); break; }
case OBJ_FUNCTION: {
我們只釋放 ObjClosure 本身,而不是 ObjFunction。這是因為閉包不擁有該函式。可能有多個閉包都參考同一個函式,而且它們都不會對其主張任何特殊權限。在所有參考它的物件(包括甚至包含它的常數表的周圍函式)都消失之前,我們無法釋放 ObjFunction—。追蹤聽起來很棘手,而且確實如此!這就是為什麼我們很快會編寫一個垃圾收集器來為我們管理它。
我們還有用於檢查值的類型的常規巨集。
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_CLOSURE(value) isObjType(value, OBJ_CLOSURE)
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
以及轉換值的巨集
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_CLOSURE(value) ((ObjClosure*)AS_OBJ(value))
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
閉包是一等物件,因此您可以列印它們。
switch (OBJ_TYPE(value)) {
在 printObject() 中
case OBJ_CLOSURE: printFunction(AS_CLOSURE(value)->function); break;
case OBJ_FUNCTION:
它們的顯示方式與 ObjFunction 完全相同。從使用者的角度來看,ObjFunction 和 ObjClosure 之間的差異純粹是一個隱藏的實作細節。這樣一來,我們就擁有了一個可運作但為空的閉包表示形式。
25.1.1編譯為閉包物件
我們有閉包物件,但我們的 VM 從未建立它們。下一步是讓編譯器發出指令,告訴執行階段何時建立新的 ObjClosure 來包裝給定的 ObjFunction。這發生在函式宣告的結尾。
ObjFunction* function = endCompiler();
在 function() 中
取代 1 行
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
}
之前,函式宣告的最終位元組碼是單個 OP_CONSTANT 指令,用於從周圍函式的常數表載入已編譯的函式並將其推入堆疊。現在我們有了一個新的指令。
OP_CALL,
在 enum OpCode 中
OP_CLOSURE,
OP_RETURN,
和 OP_CONSTANT 一樣,它採用一個單一運算元,代表函式的常數表索引。但是當我們轉到執行階段實作時,我們會做一些更有趣的事情。
首先,讓我們成為勤奮的 VM 駭客,並為該指令加入反組譯器支援。
case OP_CALL:
return byteInstruction("OP_CALL", chunk, offset);
在 disassembleInstruction() 中
case OP_CLOSURE: { offset++; uint8_t constant = chunk->code[offset++]; printf("%-16s %4d ", "OP_CLOSURE", constant); printValue(chunk->constants.values[constant]); printf("\n"); return offset; }
case OP_RETURN:
這裡發生的事情比我們通常在反組譯器中看到的還要多。在本章結束時,您會發現 OP_CLOSURE 是一個非常不尋常的指令。它現在很簡單—只有一個單一位元組運算元—但我們會繼續新增它。此處的程式碼預見了未來。
25.1.2直譯函式宣告
我們需要做的大部分工作都在執行階段中。我們必須自然地處理新的指令。但是我們還需要觸及 VM 中使用 ObjFunction 的每一段程式碼,並將其變更為改用 ObjClosure—函式呼叫、呼叫框架等等。我們先從指令開始。
}
在 run() 中
case OP_CLOSURE: { ObjFunction* function = AS_FUNCTION(READ_CONSTANT()); ObjClosure* closure = newClosure(function); push(OBJ_VAL(closure)); break; }
case OP_RETURN: {
如同我們之前使用的 OP_CONSTANT 指令,首先我們從常數表載入編譯好的函式。現在的不同之處在於,我們將該函式包裝在一個新的 ObjClosure 中,並將結果推送到堆疊上。
一旦你有了閉包,你最終會想要呼叫它。
switch (OBJ_TYPE(callee)) {
在 callValue() 中
替換 2 行
case OBJ_CLOSURE: return call(AS_CLOSURE(callee), argCount);
case OBJ_NATIVE: {
我們移除呼叫類型為 OBJ_FUNCTION 的物件的程式碼。由於我們將所有函式都包裝在 ObjClosure 中,執行時期將不再嘗試呼叫裸露的 ObjFunction。那些物件只存在於常數表中,並且在其他任何東西看到它們之前,會立即被包裝在閉包中。
我們用非常相似的程式碼來替換舊的程式碼,以便呼叫閉包。唯一的區別是我們傳遞給 call() 的物件類型。真正的改變在那函式中。首先,我們更新其簽名。
函式 call()
取代 1 行
static bool call(ObjClosure* closure, int argCount) {
if (argCount != function->arity) {
然後,在主體中,我們需要修正所有引用函式的程式碼,以處理我們引入了一層間接性的事實。我們從檢查參數數量開始。
static bool call(ObjClosure* closure, int argCount) {
在 call() 中
替換 3 行
if (argCount != closure->function->arity) { runtimeError("Expected %d arguments but got %d.", closure->function->arity, argCount);
return false;
唯一的改變是我們解開閉包以取得底層函式。接下來 call() 會做的是建立一個新的 CallFrame。我們更改該程式碼以將閉包儲存在 CallFrame 中,並從閉包的函式中取得位元組碼指標。
CallFrame* frame = &vm.frames[vm.frameCount++];
在 call() 中
替換 2 行
frame->closure = closure; frame->ip = closure->function->chunk.code;
frame->slots = vm.stackTop - argCount - 1;
這也需要更改 CallFrame 的宣告。
typedef struct {
在 struct CallFrame 中
取代 1 行
ObjClosure* closure;
uint8_t* ip;
這個變更觸發了一些其他連鎖變更。VM 中每個存取 CallFrame 函式的地方都需要改為使用閉包。首先,用於從目前函式的常數表讀取常數的巨集。
(uint16_t)((frame->ip[-2] << 8) | frame->ip[-1]))
在 run() 中
替換 2 行
#define READ_CONSTANT() \ (frame->closure->function->chunk.constants.values[READ_BYTE()])
#define READ_STRING() AS_STRING(READ_CONSTANT())
當啟用 DEBUG_TRACE_EXECUTION 時,它需要從閉包取得 chunk。
printf("\n");
在 run() 中
替換 2 行
disassembleInstruction(&frame->closure->function->chunk, (int)(frame->ip - frame->closure->function->chunk.code));
#endif
同樣,在報告執行時期錯誤時
CallFrame* frame = &vm.frames[i];
在 runtimeError() 中
取代 1 行
ObjFunction* function = frame->closure->function;
size_t instruction = frame->ip - function->chunk.code - 1;
快完成了。最後一部分是設定第一個 CallFrame 以開始執行 Lox 腳本最上層程式碼的程式碼區塊。
push(OBJ_VAL(function));
在 interpret() 中
取代 1 行
ObjClosure* closure = newClosure(function); pop(); push(OBJ_VAL(closure)); call(closure, 0);
return run();
編譯器在編譯腳本時仍然回傳原始的 ObjFunction。這沒關係,但這表示我們需要在這裡將其包裝在 ObjClosure 中,VM 才能執行它。
我們回到了可以運作的直譯器。使用者無法分辨任何差異,但編譯器現在產生程式碼,告訴 VM 為每個函式宣告建立閉包。每當 VM 執行函式宣告時,它會將 ObjFunction 包裝在新的 ObjClosure 中。VM 的其餘部分現在處理那些四處漂浮的 ObjClosure。這就是無聊的部分。現在我們準備讓這些閉包實際做點事情。
25. 2Upvalue
我們現有的讀取和寫入區域變數的指令僅限於單一函式的堆疊視窗。來自周圍函式的區域變數位於內部函式視窗之外。我們需要一些新的指令。
最簡單的方法可能是使用一個指令,該指令採用一個相對堆疊槽偏移量,該偏移量可以到達目前函式視窗之前。如果封閉變數始終在堆疊上,這將會奏效。但正如我們稍早看到的,這些變數有時會比宣告它們的函式活得更久。這表示它們不會始終在堆疊上。
那麼,下一個最簡單的方法是採用任何被封閉的區域變數,並使其始終存在於堆積上。當執行周圍函式中的區域變數宣告時,VM 將動態分配記憶體給它。這樣它就可以在需要時存活。
如果 clox 沒有單通行編譯器,這將是一個好方法。但我們實作中選擇的限制使得事情變得更加困難。看看這個例子
fun outer() { var x = 1; // (1) x = 2; // (2) fun inner() { // (3) print x; } inner(); }
在這裡,編譯器在 (1) 編譯 x 的宣告,並在 (2) 發出賦值的程式碼。它在 (3) 觸及 inner() 的宣告並發現 x 實際上被封閉之前執行此操作。我們沒有簡單的方法可以返回並修正已經發出的程式碼,以特別處理 x。相反地,我們想要一個解決方案,該解決方案允許封閉變數像正常的區域變數一樣在堆疊上存在,直到它被封閉為止。
幸運的是,感謝 Lua 開發團隊,我們有了解決方案。我們使用他們稱之為 **upvalue** 的間接層。upvalue 指的是封閉函式中的區域變數。每個閉包都維護一個 upvalue 陣列,每個 upvalue 對應閉包使用的每個周圍的區域變數。
upvalue 指回堆疊,指向它捕獲的變數所在的位置。當閉包需要存取封閉的變數時,它會通過相應的 upvalue 來取得它。當首次執行函式宣告並為其建立閉包時,VM 會建立 upvalue 陣列,並將它們連接起來以「捕獲」閉包需要的周圍區域變數。
例如,如果我們將此程式傳遞給 clox,
{
var a = 3;
fun f() {
print a;
}
}
編譯器和執行時期將會共同在記憶體中建構一組如下所示的物件
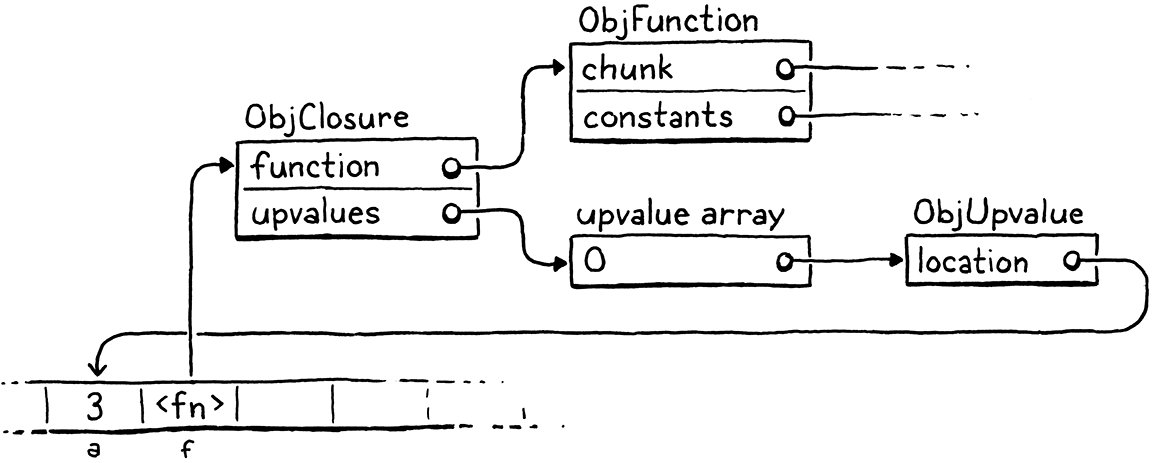
這看起來可能令人難以承受,但別害怕。我們會逐步處理它。重要的部分是,即使捕獲的區域變數從堆疊中移出,upvalue 也會充當繼續尋找它的間接層。但在我們了解所有這些之前,讓我們專注於編譯捕獲的變數。
25. 2. 1編譯 Upvalue
像往常一樣,我們希望在編譯期間盡可能多地完成工作,以保持執行簡單快速。由於區域變數在 Lox 中具有詞法作用域,因此我們在編譯時有足夠的知識來解析函式存取哪些周圍的區域變數,以及宣告這些區域變數的位置。反過來說,這表示我們知道閉包需要多少 upvalue、它們捕獲哪些變數,以及在宣告函式的堆疊視窗中哪些堆疊槽包含這些變數。
目前,當編譯器解析識別符號時,它會從最內部到最外部走過目前函式的作用域區塊。如果我們沒有在該函式中找到變數,我們會假設該變數必定是全域變數。我們不考慮封閉函式的區域作用域—它們會被直接跳過。因此,第一個變更是插入這些外部區域作用域的解析步驟。
if (arg != -1) {
getOp = OP_GET_LOCAL;
setOp = OP_SET_LOCAL;
在 namedVariable() 中
} else if ((arg = resolveUpvalue(current, &name)) != -1) { getOp = OP_GET_UPVALUE; setOp = OP_SET_UPVALUE;
} else {
這個新的 resolveUpvalue() 函式會尋找在任何周圍函式中宣告的區域變數。如果找到,它會回傳該變數的「upvalue 索引」。 (我們稍後會深入探討這意味著什麼。)否則,它會回傳 -1 表示未找到該變數。如果找到它,我們會使用這兩個新指令,通過其 upvalue 讀取或寫入變數
OP_SET_GLOBAL,
在 enum OpCode 中
OP_GET_UPVALUE, OP_SET_UPVALUE,
OP_EQUAL,
我們正在實作這種由上而下的方式,所以我很快就會告訴你這些指令如何在執行時期運作。現在要關注的部分是編譯器如何實際解析識別符號。
在 resolveLocal() 之後新增
static int resolveUpvalue(Compiler* compiler, Token* name) { if (compiler->enclosing == NULL) return -1; int local = resolveLocal(compiler->enclosing, name); if (local != -1) { return addUpvalue(compiler, (uint8_t)local, true); } return -1; }
我們在無法解析目前函式作用域中的區域變數後呼叫它,因此我們知道該變數不在目前的編譯器中。回想一下,編譯器儲存指向封閉函式編譯器的指標,並且這些指標形成一個鏈接鏈,一直到最上層程式碼的根編譯器。因此,如果封閉編譯器是 NULL,我們就知道我們已經到達最外層的函式,而沒有找到區域變數。該變數必定是全域變數,因此我們回傳 -1。
否則,我們會嘗試將識別符號解析為封閉編譯器中的區域變數。換句話說,我們會直接在目前函式之外尋找它。例如
fun outer() { var x = 1; fun inner() { print x; // (1) } inner(); }
在編譯 (1) 的識別符號運算式時,resolveUpvalue() 會在 outer() 中尋找宣告的區域變數 x。如果找到—就像此範例一樣—那麼我們就已成功解析該變數。我們會建立一個 upvalue,以便內部函式可以通過它存取該變數。upvalue 在此處建立
在 resolveLocal() 之後新增
static int addUpvalue(Compiler* compiler, uint8_t index, bool isLocal) { int upvalueCount = compiler->function->upvalueCount; compiler->upvalues[upvalueCount].isLocal = isLocal; compiler->upvalues[upvalueCount].index = index; return compiler->function->upvalueCount++; }
編譯器會保留一個 upvalue 結構陣列,以追蹤它在每個函式主體中解析的封閉識別符號。還記得編譯器的 Local 陣列如何反映執行時期區域變數所在的堆疊槽索引嗎?這個新的 upvalue 陣列以相同的方式運作。編譯器陣列中的索引會與執行時期 ObjClosure 中 upvalue 所在位置的索引相符。
此函式會將新的 upvalue 新增至該陣列。它也會追蹤函式使用的 upvalue 數量。它會將該計數直接儲存在 ObjFunction 本身中,因為我們也需要該數字以在執行時期使用。
index 欄位追蹤封閉區域變數的槽索引。這樣編譯器就知道需要捕獲封閉函式中的哪個變數。我們很快就會回到 isLocal 欄位的作用。最後,addUpvalue() 會回傳已建立的 upvalue 在函式 upvalue 列表中的索引。該索引成為 OP_GET_UPVALUE 和 OP_SET_UPVALUE 指令的運算元。
這就是解析 upvalue 的基本概念,但該函式並未完全完成。閉包可能會多次引用周圍函式中的相同變數。在這種情況下,我們不想浪費時間和記憶體為每個識別符號運算式建立單獨的 upvalue。為了修正這一點,在新增新的 upvalue 之前,我們會先檢查函式是否已經有封閉該變數的 upvalue。
int upvalueCount = compiler->function->upvalueCount;
在 addUpvalue() 中
for (int i = 0; i < upvalueCount; i++) { Upvalue* upvalue = &compiler->upvalues[i]; if (upvalue->index == index && upvalue->isLocal == isLocal) { return i; } }
compiler->upvalues[upvalueCount].isLocal = isLocal;
如果我們在陣列中找到槽索引與我們要新增的索引相符的 upvalue,我們只會回傳該 upvalue 索引並重複使用它。否則,我們會跳過並新增新的 upvalue。
這兩個函式會存取和修改大量新的狀態,所以讓我們定義它。首先,我們將 upvalue 計數新增至 ObjFunction。
int arity;
在 struct ObjFunction 中
int upvalueCount;
Chunk chunk;
我們是認真的 C 程式設計師,所以在首次配置 ObjFunction 時,我們會將其歸零初始化。
function->arity = 0;
在 newFunction() 中
function->upvalueCount = 0;
function->name = NULL;
在編譯器中,我們為 upvalue 陣列新增一個欄位。
int localCount;
在 struct Compiler 中
Upvalue upvalues[UINT8_COUNT];
int scopeDepth;
為了簡化,我給它一個固定的大小。OP_GET_UPVALUE 和 OP_SET_UPVALUE 指令使用單一位元組運算元來編碼 upvalue 索引,因此函數可以擁有的 upvalue 數量有限制—它可以封閉的唯一變數數量。 鑑於此,我們可以負擔得起這麼大的靜態陣列。 我們還需要確保編譯器不會溢出該限制。
if (upvalue->index == index && upvalue->isLocal == isLocal) {
return i;
}
}
在 addUpvalue() 中
if (upvalueCount == UINT8_COUNT) { error("Too many closure variables in function."); return 0; }
compiler->upvalues[upvalueCount].isLocal = isLocal;
最後是 Upvalue 結構類型本身。
在 struct Local 之後新增
typedef struct { uint8_t index; bool isLocal; } Upvalue;
index 欄位儲存 upvalue 正在捕獲的本機插槽。 isLocal 欄位值得單獨一節說明,我們將在下一節介紹。
25 . 2 . 2扁平化 upvalue
在我之前展示的範例中,閉包正在存取在直接封閉的函數中宣告的變數。 Lox 也支援存取在任何封閉範圍中宣告的本機變數,例如
fun outer() { var x = 1; fun middle() { fun inner() { print x; } } }
在這裡,我們在 inner() 中存取 x。 該變數不是在 middle() 中定義,而是在最外層的 outer() 中定義。 我們也需要處理這種情況。 您可能認為這並不太困難,因為該變數只會位於堆疊上更遠的位置。 但請考慮這個 狡猾的範例
fun outer() { var x = "value"; fun middle() { fun inner() { print x; } print "create inner closure"; return inner; } print "return from outer"; return middle; } var mid = outer(); var in = mid(); in();
當您執行此程式時,它應該會印出
return from outer create inner closure value
我知道,這很複雜。 重要的部分是 outer()—宣告 x 的位置—在 inner() 的宣告執行之前返回並從堆疊中彈出其所有變數。 因此,在我們為 inner() 建立閉包的那一刻,x 已經不在堆疊中了。
這裡,我為您追蹤了執行流程
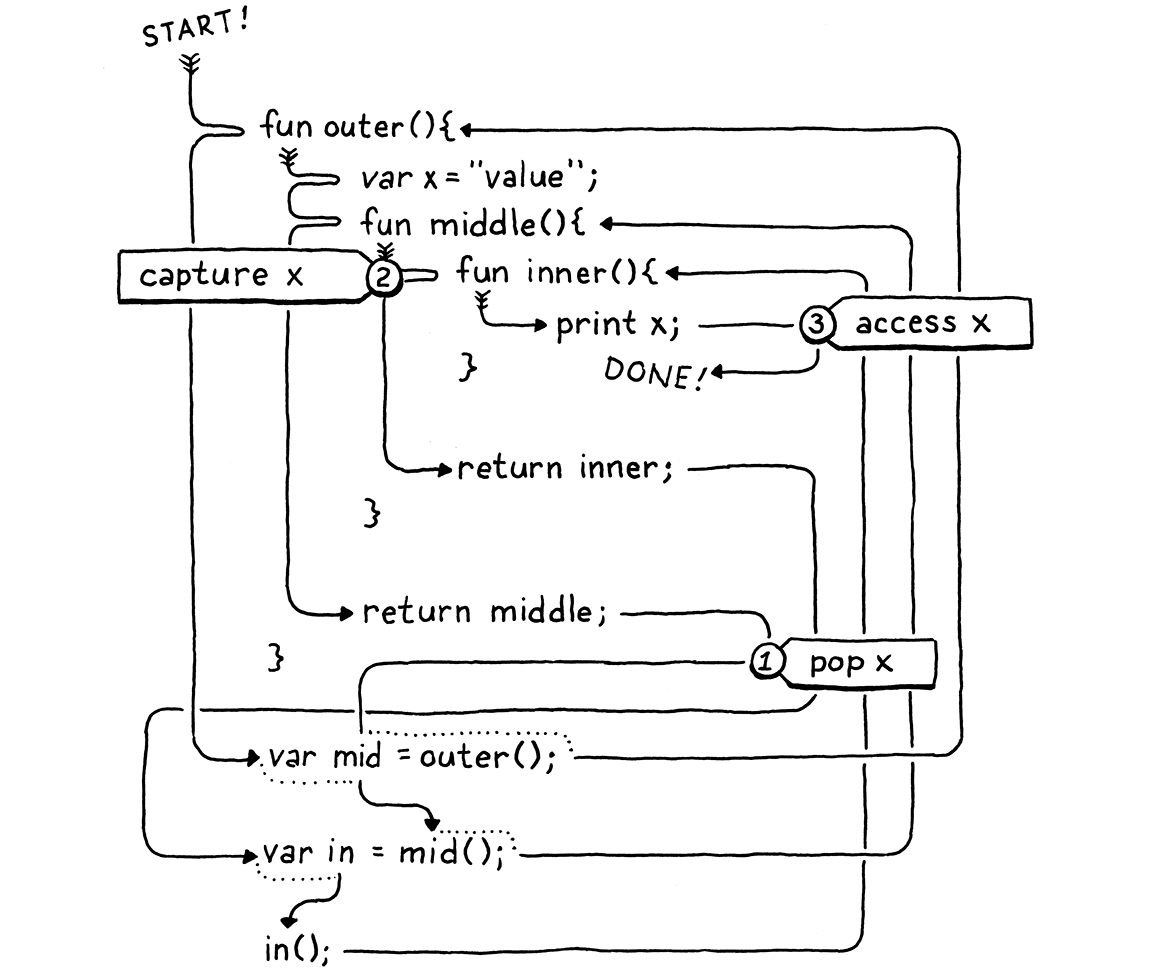
請參閱 x 如何在被捕獲 ② 之前彈出 ①,然後稍後被存取 ③? 我們實際上存在兩個問題
-
我們需要解析在直接封閉函數之外的周圍函數中宣告的本機變數。
-
我們需要能夠捕獲已離開堆疊的變數。
幸運的是,我們正處於向 VM 新增 upvalue 的過程中,而 upvalue 是專為追蹤已脫離堆疊的變數而設計的。 因此,在一個聰明的自我參照中,我們可以利用 upvalue 來允許 upvalue 捕獲在直接周圍函數之外宣告的變數。
解決方案是允許閉包捕獲本機變數或直接封閉函數中的現有 upvalue。 如果深度巢狀函數參考了在數個跳躍之外宣告的本機變數,我們將透過讓每個函數捕獲下一個函數要抓取的 upvalue 來將其貫穿所有中間函數。
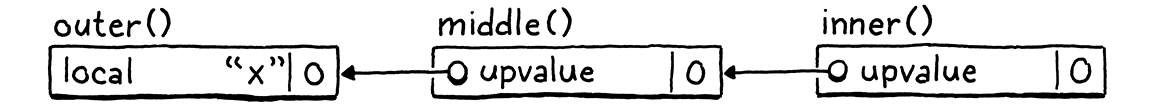
在上面的範例中,middle() 捕獲直接封閉函數 outer() 中的本機變數 x,並將其儲存在自己的 upvalue 中。 即使 middle() 本身不參考 x,它也會執行此操作。 然後,當 inner() 的宣告執行時,其閉包會從 middle() 的 ObjClosure 中抓取捕獲 x 的 upvalue。 函數會僅從直接周圍的函數捕獲—本機變數或 upvalue—,這可以保證在內部函數宣告執行的時間點仍然存在。
為了實作此功能,resolveUpvalue() 變成遞迴的。
if (local != -1) {
return addUpvalue(compiler, (uint8_t)local, true);
}
在 resolveUpvalue() 中
int upvalue = resolveUpvalue(compiler->enclosing, name); if (upvalue != -1) { return addUpvalue(compiler, (uint8_t)upvalue, false); }
return -1;
它只有另外三行程式碼,但我發現這個函數第一次就很難寫對。 儘管事實是我沒有發明任何新東西,只是將概念從 Lua 移植過來。 大多數遞迴函數要麼在遞迴呼叫之前執行所有工作(前序遍歷,或「在向下方向」),要麼在遞迴呼叫之後執行所有工作(後序遍歷,或「在返回方向」)。 這個函數同時執行這兩者。 遞迴呼叫就在中間。
我們將慢慢地逐步說明。 首先,我們在封閉函數中尋找符合的本機變數。 如果找到一個,我們會捕獲該本機變數並返回。 這是基本情況。
否則,我們會在直接封閉函數之外尋找本機變數。 我們透過在封閉編譯器(而不是目前的編譯器)上遞迴呼叫 resolveUpvalue() 來執行此操作。 這個 resolveUpvalue() 呼叫系列會沿著巢狀編譯器的鏈條移動,直到它遇到基本情況之一—要麼它找到要捕獲的實際本機變數,要麼它用完編譯器。
找到本機變數時,最深層巢狀的 resolveUpvalue() 呼叫會捕獲它並返回 upvalue 索引。 這會返回給內部函數宣告的下一個呼叫。 該呼叫會從周圍函數捕獲 upvalue,依此類推。 當每個巢狀 resolveUpvalue() 呼叫返回時,我們會鑽回出現我們要解析的識別碼的最內部函數宣告。 在沿途的每個步驟中,我們都會將一個 upvalue 新增到介入函數,並將產生的 upvalue 索引向下傳遞到下一個呼叫。
在解析 x 時,逐步說明原始範例可能會有所幫助
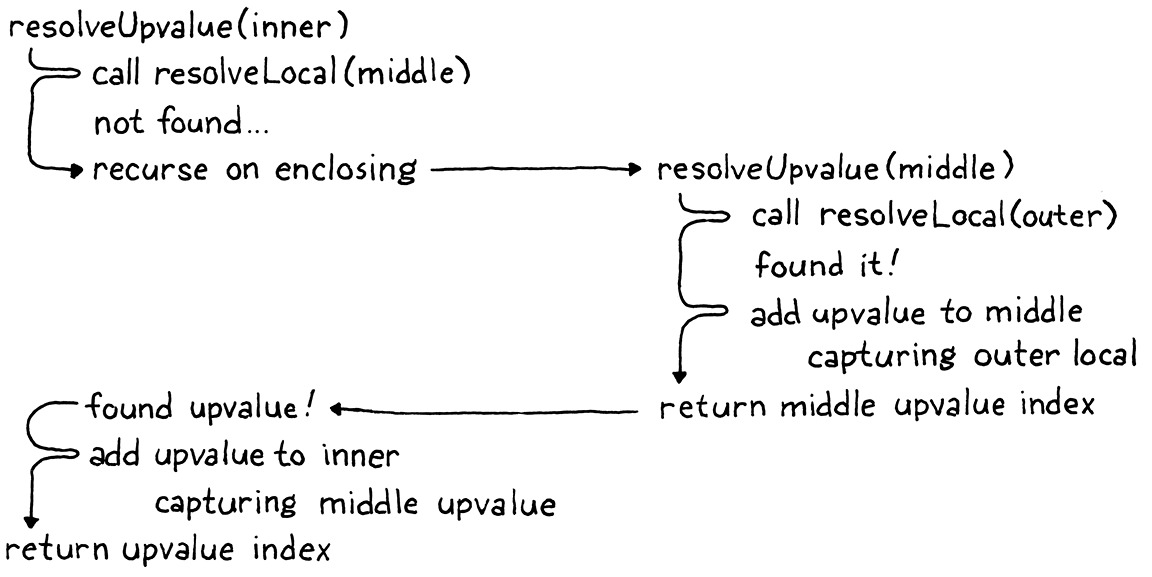
請注意,對 addUpvalue() 的新呼叫會為 isLocal 參數傳遞 false。 現在您看到該旗標控制閉包是捕獲本機變數還是來自周圍函數的 upvalue。
當編譯器到達函數宣告的末尾時,每個變數參考都已解析為本機變數、upvalue 或全域變數。 每個 upvalue 又可以捕獲來自周圍函數的本機變數,或者在傳遞閉包的情況下捕獲 upvalue。 我們最終擁有足夠的資料來發出位元組碼,位元組碼會在執行階段建立一個閉包,該閉包會捕獲所有正確的變數。
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
在 function() 中
for (int i = 0; i < function->upvalueCount; i++) { emitByte(compiler.upvalues[i].isLocal ? 1 : 0); emitByte(compiler.upvalues[i].index); }
}
OP_CLOSURE 指令的獨特之處在於它具有可變大小的編碼。 對於閉包捕獲的每個 upvalue,都有兩個單一位元組運算元。 每對運算元都指定該 upvalue 捕獲的內容。 如果第一個位元組是一,則它會捕獲封閉函數中的本機變數。 如果為零,則它會捕獲該函數的其中一個 upvalue。 下一個位元組是要捕獲的本機插槽或 upvalue 索引。
這種奇特的編碼表示我們需要在反組譯碼程式碼中對 OP_CLOSURE 提供一些自訂支援。
printf("\n");
在 disassembleInstruction() 中
ObjFunction* function = AS_FUNCTION(
chunk->constants.values[constant]);
for (int j = 0; j < function->upvalueCount; j++) {
int isLocal = chunk->code[offset++];
int index = chunk->code[offset++];
printf("%04d | %s %d\n",
offset - 2, isLocal ? "local" : "upvalue", index);
}
return offset;
例如,取這個腳本
fun outer() { var a = 1; var b = 2; fun middle() { var c = 3; var d = 4; fun inner() { print a + c + b + d; } } }
如果我們反組譯建立 inner() 閉包的指令,它會印出這個
0004 9 OP_CLOSURE 2 <fn inner> 0006 | upvalue 0 0008 | local 1 0010 | upvalue 1 0012 | local 2
我們還有另外兩個更簡單的指令要新增反組譯碼程式支援。
case OP_SET_GLOBAL:
return constantInstruction("OP_SET_GLOBAL", chunk, offset);
在 disassembleInstruction() 中
case OP_GET_UPVALUE: return byteInstruction("OP_GET_UPVALUE", chunk, offset); case OP_SET_UPVALUE: return byteInstruction("OP_SET_UPVALUE", chunk, offset);
case OP_EQUAL:
這兩者都具有單一位元組運算元,因此沒有什麼令人興奮的事情發生。 我們確實需要新增一個 include,以便偵錯模組可以存取 AS_FUNCTION()。
#include "debug.h"
#include "object.h"
#include "value.h"
有了這個,我們的編譯器就如我們所願了。 對於每個函數宣告,它會輸出一個 OP_CLOSURE 指令,然後是一系列運算元位元組對,用於它需要在執行階段捕獲的每個 upvalue。 現在是跳到 VM 的那一側並讓事情開始運作的時候了。
25 . 3Upvalue 物件
每個 OP_CLOSURE 指令後面都會跟著一系列位元組,這些位元組指定 ObjClosure 應該擁有的 upvalue。 在我們處理這些運算元之前,我們需要 upvalue 的執行階段表示。
在 struct ObjString 之後新增
typedef struct ObjUpvalue { Obj obj; Value* location; } ObjUpvalue;
我們知道 upvalue 必須管理不再存在於堆疊中的封閉變數,這意味著需要進行一些動態配置。 在我們的 VM 中執行此操作的最簡單方法是基於我們已有的物件系統。 這樣,當我們在下一章中實作垃圾收集器時,GC 也可以管理 upvalue 的記憶體。
因此,我們的執行階段 upvalue 結構是一個 ObjUpvalue,具有典型的 Obj 標頭欄位。 之後是一個 location 欄位,它指向封閉的變數。 請注意,這是指向 Value 的指標,而不是 Value 本身。 它是對變數的參考,而不是對值的參考。 這很重要,因為這表示當我們指定給 upvalue 捕獲的變數時,我們指定給的是實際變數,而不是複本。 例如
fun outer() { var x = "before"; fun inner() { x = "assigned"; } inner(); print x; } outer();
即使閉包指定給 x 且周圍的函數存取它,這個程式也應該印出「assigned」。
由於 upvalue 是物件,我們擁有所有常見的物件機制,從類似建構函式的函數開始
ObjString* copyString(const char* chars, int length);
在 copyString() 之後新增
ObjUpvalue* newUpvalue(Value* slot);
void printObject(Value value);
它會取得封閉變數所在插槽的位址。 以下是實作
在 copyString() 之後新增
ObjUpvalue* newUpvalue(Value* slot) { ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE); upvalue->location = slot; return upvalue; }
我們只初始化物件並儲存指標。 這需要新的物件類型。
OBJ_STRING,
在 enum ObjType 中
OBJ_UPVALUE
} ObjType;
在背面,有一個類似解構函式的函數
FREE(ObjString, object);
break;
}
在 freeObject() 中
case OBJ_UPVALUE: FREE(ObjUpvalue, object); break;
}
多個閉包可以封閉相同的變數,因此 ObjUpvalue 不擁有它參考的變數。 因此,唯一要釋放的是 ObjUpvalue 本身。
最後,要列印
case OBJ_STRING:
printf("%s", AS_CSTRING(value));
break;
在 printObject() 中
case OBJ_UPVALUE: printf("upvalue"); break;
}
列印對終端使用者沒有用處。 upvalue 僅是物件,以便我們可以利用 VM 的記憶體管理。 它們不是 Lox 使用者可以在程式中直接存取的一級值。 因此,此程式碼永遠不會實際執行 . . . ,但它可以防止編譯器對未處理的 switch case 大喊大叫,所以我們在這裡。
25 . 3 . 1閉包中的 Upvalue
當我第一次介紹 upvalue 時,我說每個閉包都有一個它們的陣列。 我們終於回頭來實作它了。
ObjFunction* function;
在 struct ObjClosure 中
ObjUpvalue** upvalues; int upvalueCount;
} ObjClosure;
不同的閉包可能具有不同數量的 upvalue,因此我們需要一個動態陣列。 upvalue 本身也是動態配置的,因此我們最終會得到一個雙指標—指向動態配置的 upvalue 指標陣列的指標。 我們也會儲存陣列中的元素數量。
當我們建立 ObjClosure 時,我們會配置適當大小的 upvalue 陣列,我們在編譯時決定了該大小並將其儲存在 ObjFunction 中。
ObjClosure* newClosure(ObjFunction* function) {
在 newClosure() 中
ObjUpvalue** upvalues = ALLOCATE(ObjUpvalue*, function->upvalueCount); for (int i = 0; i < function->upvalueCount; i++) { upvalues[i] = NULL; }
ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE);
在建立閉包物件本身之前,我們會配置 upvalue 陣列並將它們全部初始化為 NULL。 這個圍繞記憶體的奇怪儀式是為了取悅(即將到來的)垃圾收集神靈的精心舞蹈。 它確保記憶體管理器永遠不會看到未初始化的記憶體。
然後,我們將陣列儲存在新的閉包中,並從 ObjFunction 複製計數。
closure->function = function;
在 newClosure() 中
closure->upvalues = upvalues; closure->upvalueCount = function->upvalueCount;
return closure;
當我們釋放 ObjClosure 時,也會釋放 upvalue 陣列。
case OBJ_CLOSURE: {
在 freeObject() 中
ObjClosure* closure = (ObjClosure*)object; FREE_ARRAY(ObjUpvalue*, closure->upvalues, closure->upvalueCount);
FREE(ObjClosure, object);
ObjClosure 本身不擁有 ObjUpvalue 物件,但它擁有指向這些 upvalue 的指標陣列。
當直譯器建立閉包時,會在直譯器中填入 upvalue 陣列。在這裡,我們會遍歷 OP_CLOSURE 之後的所有運算元,以查看每個槽捕捉哪種類型的 upvalue。
push(OBJ_VAL(closure));
在 run() 中
for (int i = 0; i < closure->upvalueCount; i++) { uint8_t isLocal = READ_BYTE(); uint8_t index = READ_BYTE(); if (isLocal) { closure->upvalues[i] = captureUpvalue(frame->slots + index); } else { closure->upvalues[i] = frame->closure->upvalues[index]; } }
break;
這段程式碼是閉包誕生的神奇時刻。我們迭代閉包期望的每個 upvalue。對於每一個,我們讀取一對運算元位元組。如果 upvalue 關閉的是封閉函式中的局部變數,我們讓 captureUpvalue() 完成工作。
否則,我們從周圍的函式捕捉一個 upvalue。OP_CLOSURE 指令會在函式宣告的結尾發出。當我們執行該宣告時,目前的函式是周圍的函式。這表示目前的函式的閉包儲存在呼叫堆疊頂端的 CallFrame 中。因此,要從封閉函式取得 upvalue,我們可以從 frame 局部變數中讀取,該變數會快取對該 CallFrame 的參考。
關閉局部變數比較有趣。大部分工作會在單獨的函式中完成,但首先我們要計算傳遞給它的參數。我們需要取得一個指標,指向封閉函式堆疊視窗中捕捉到的局部變數的槽。該視窗從 frame->slots 開始,指向槽零。加上 index 會偏移到我們想要捕捉的局部槽。我們在這裡傳遞該指標。
在 callValue() 之後新增
static ObjUpvalue* captureUpvalue(Value* local) { ObjUpvalue* createdUpvalue = newUpvalue(local); return createdUpvalue; }
這看起來有點傻。它所做的只是建立一個新的 ObjUpvalue 來捕捉給定的堆疊槽並傳回它。我們需要一個單獨的函式來做這個嗎?嗯,不,還不需要。但你知道我們最終會在這裡加入更多程式碼。
首先,讓我們總結一下我們正在做的事情。回到處理 OP_CLOSURE 的直譯器程式碼中,我們最終會完成迭代 upvalue 陣列並初始化每一個。當完成時,我們會有一個新的閉包,其中包含指向變數的 upvalue 陣列。
有了這個,我們可以實作處理這些 upvalue 的指令。
}
在 run() 中
case OP_GET_UPVALUE: { uint8_t slot = READ_BYTE(); push(*frame->closure->upvalues[slot]->location); break; }
case OP_EQUAL: {
運算元是目前函式的 upvalue 陣列的索引。因此,我們只需查閱對應的 upvalue 並取消其位置指標的參考,以讀取該槽中的值。設定變數也是類似的。
}
在 run() 中
case OP_SET_UPVALUE: { uint8_t slot = READ_BYTE(); *frame->closure->upvalues[slot]->location = peek(0); break; }
case OP_EQUAL: {
我們取出堆疊頂端的值,並將其儲存到所選 upvalue 指向的槽中。就像局部變數的指令一樣,這些指令快速是很重要的。使用者程式會不斷讀取和寫入變數,因此如果速度慢,一切都會很慢。而且,像往常一樣,我們讓它們變快的方法是保持它們的簡單性。這兩個新的指令非常好:沒有控制流程,沒有複雜的算術,只有幾個指標間接尋址和一個 push()。
這是一個里程碑。只要所有變數都保留在堆疊上,我們就有可以運作的閉包。試試看這個
fun outer() { var x = "outside"; fun inner() { print x; } inner(); } outer();
執行此程式碼,它會正確印出「outside」。
25 . 4關閉的 Upvalue
當然,閉包的一個關鍵功能是它們會在需要的時間內保留變數,即使宣告變數的函式已傳回。這是另一個應該有效的範例
fun outer() { var x = "outside"; fun inner() { print x; } return inner; } var closure = outer(); closure();
但如果您現在執行它 . . .誰知道它會做什麼?在執行階段,它最終會從不再包含封閉變數的堆疊槽中讀取。就像我提過幾次一樣,問題的關鍵在於閉包中的變數沒有堆疊語義。這表示我們必須在宣告它們的函式傳回時,將它們從堆疊中提取出來。本章的最後一部分會執行此操作。
25 . 4 . 1值和變數
在我們開始編寫程式碼之前,我想深入探討一個重要的語義點。閉包會關閉值還是變數?這不僅僅是一個學術問題。我不只是在吹毛求疵。請考慮
var globalSet; var globalGet; fun main() { var a = "initial"; fun set() { a = "updated"; } fun get() { print a; } globalSet = set; globalGet = get; } main(); globalSet(); globalGet();
外部的 main() 函式會建立兩個閉包,並將它們儲存在全域變數中,以便它們的生命週期比 main() 本身的執行時間長。這兩個閉包都捕捉相同的變數。第一個閉包會為它賦予一個新值,而第二個閉包會讀取該變數。
呼叫 globalGet() 會印出什麼?如果閉包捕捉值,那麼每個閉包都會取得 a 的自己的副本,其值為閉包的函式宣告執行時 a 的值。呼叫 globalSet() 會修改 set() 的 a 副本,但 get() 的副本將不受影響。因此,呼叫 globalGet() 會印出「initial」。
如果閉包關閉變數,那麼 get() 和 set() 都會捕捉—參考—相同的可變變數。當 set() 變更 a 時,它會變更 get() 從中讀取的同一個 a。只有一個 a。這反過來意味著呼叫 globalGet() 會印出「updated」。
是哪一個?Lox 和我所知的大多數其他具有閉包的語言的答案是後者。閉包會捕捉變數。您可以將它們視為捕捉值所存在的位置。當我們處理不再位於堆疊上的封閉變數時,請務必記住這一點。當變數移至堆積時,我們需要確保捕捉該變數的所有閉包都保留對其一個新位置的參考。這樣,當變數被修改時,所有閉包都會看到變更。
25 . 4 . 2關閉 upvalue
我們知道局部變數總是從堆疊開始。這速度更快,並允許我們的單趟編譯器在發現變數已被捕捉之前發出程式碼。我們也知道,如果閉包的生命週期比宣告捕捉變數的函式長,則封閉變數需要移至堆積。
依照 Lua,我們將使用開啟的 upvalue 來指稱指向仍在堆疊上的局部變數的 upvalue。當變數移至堆積時,我們正在關閉 upvalue,結果自然是關閉的 upvalue。我們需要回答的兩個問題是
-
封閉變數會移至堆積上的哪個位置?
-
我們何時關閉 upvalue?
第一個問題的答案很簡單。我們已經在堆積上有一個方便的物件,可以代表對變數的參考—ObjUpvalue 本身。封閉變數將移至 ObjUpvalue 結構內的新欄位。這樣,我們就不需要執行任何額外的堆積配置來關閉 upvalue。
第二個問題也很直接。只要變數位於堆疊上,就可能有程式碼在那裡參考它,而且該程式碼必須正確運作。因此,將變數提升至堆積的邏輯時間是盡可能晚。如果我們在局部變數超出範圍時立即移動它,我們可以確定在該點之後沒有程式碼會嘗試從堆疊存取它。在變數超出範圍之後,如果任何程式碼嘗試使用它,編譯器將會報告錯誤。
當局部變數超出範圍時,編譯器已經發出 OP_POP 指令。如果變數被閉包捕捉,我們將改為發出不同的指令,以將該變數從堆疊提升到其對應的 upvalue。為此,編譯器需要知道哪些局部變數被關閉。
編譯器已經為函式中的每個局部變數維護一個 Upvalue 結構的陣列,以追蹤確切的狀態。該陣列適用於回答「此閉包使用哪些變數?」但它不適合回答「任何函式是否捕捉此局部變數?」尤其是,一旦某個閉包的編譯器完成,封閉函式的編譯器 (其變數已被捕捉) 將無法再存取任何 upvalue 狀態。
換句話說,編譯器維護從 upvalue 到它們捕捉的局部變數的指標,但不是反方向。因此,我們首先需要在現有的 Local 結構內加入一些額外的追蹤,以便我們判斷給定的局部變數是否被閉包捕捉。
int depth;
在結構 Local 中
bool isCaptured;
} Local;
如果局部變數被任何後來的巢狀函式宣告捕捉,則此欄位為 true。最初,所有局部變數都未被捕捉。
local->depth = -1;
在 addLocal() 中
local->isCaptured = false;
}
同樣地,編譯器隱含宣告的特殊「槽零局部變數」不會被捕捉。
local->depth = 0;
在 initCompiler() 中
local->isCaptured = false;
local->name.start = "";
在解析識別碼時,如果我們最終為局部變數建立 upvalue,我們會將其標示為已捕捉。
if (local != -1) {
在 resolveUpvalue() 中
compiler->enclosing->locals[local].isCaptured = true;
return addUpvalue(compiler, (uint8_t)local, true);
現在,在區塊範圍的結尾,當編譯器發出程式碼以釋放局部變數的堆疊槽時,我們可以判斷哪些需要提升到堆積。我們將為此使用一個新的指令。
while (current->localCount > 0 &&
current->locals[current->localCount - 1].depth >
current->scopeDepth) {
在 endScope() 中
取代 1 行
if (current->locals[current->localCount - 1].isCaptured) { emitByte(OP_CLOSE_UPVALUE); } else { emitByte(OP_POP); }
current->localCount--; }
這個指令不需要運算元。我們知道當這個指令執行時,變數永遠會在堆疊的最頂端。我們宣告這個指令。
OP_CLOSURE,
在 enum OpCode 中
OP_CLOSE_UPVALUE,
OP_RETURN,
並為它加入簡單的反組譯器支援
}
在 disassembleInstruction() 中
case OP_CLOSE_UPVALUE: return simpleInstruction("OP_CLOSE_UPVALUE", offset);
case OP_RETURN:
太棒了。現在產生的位元組碼會確切地告訴執行時期,每個捕獲的區域變數何時必須移動到堆積中。更好的是,它只會針對被閉包使用且需要這種特殊處理的區域變數執行此操作。這與我們的一般效能目標一致,我們希望使用者只為他們使用的功能付費。未被閉包使用的變數會像以前一樣完全在堆疊上生存和消亡。
25 . 4 . 3追蹤開放的 upvalue
讓我們轉到執行時期方面。在我們可以解釋 OP_CLOSE_UPVALUE 指令之前,我們有一個問題需要解決。之前,當我談到閉包是捕獲變數還是值時,我說如果多個閉包存取同一個變數,它們最終會參考到記憶體中完全相同的儲存位置,這點很重要。這樣,如果一個閉包寫入變數,另一個閉包就會看到變更。
目前,如果兩個閉包捕獲相同的區域變數,VM 會為每個閉包建立一個單獨的 Upvalue。必要的共享機制遺失了。當我們將變數從堆疊中移出時,如果我們只將它移動到其中一個 upvalue 中,則另一個 upvalue 將會有一個孤立的值。
為了修正這個問題,每當 VM 需要一個捕獲特定區域變數槽的 upvalue 時,我們將首先搜尋指向該槽的現有 upvalue。如果找到,我們就重複使用它。挑戰在於,所有先前建立的 upvalue 都被偷偷地藏在各種閉包的 upvalue 陣列中。這些閉包可能位於 VM 記憶體的任何位置。
第一步是讓 VM 擁有自己的所有指向仍在堆疊上的變數的開放 upvalue 清單。每次 VM 需要 upvalue 時都搜尋清單聽起來可能很慢,但實際上並不會太慢。堆疊上實際被閉包捕獲的變數數量往往很小。而且,建立閉包的函式宣告很少位於使用者程式碼中效能關鍵的執行路徑上。
更好的是,我們可以依照它們指向的堆疊槽索引來排序開放 upvalue 的清單。常見的情況是,某個槽*尚未*被捕獲—在閉包之間共享變數並不常見—而且閉包傾向於捕獲靠近堆疊頂端的區域變數。如果我們以堆疊槽順序儲存開放 upvalue 陣列,一旦我們跳過正在捕獲的區域變數所在的槽,我們就知道它不會被找到。當該區域變數靠近堆疊頂端時,我們可以很早地退出迴圈。
維護排序的清單需要在中間有效率地插入元素。這建議使用鏈結串列而不是動態陣列。由於我們自己定義了 ObjUpvalue 結構,因此最簡單的實作是將下一個指標直接放入 ObjUpvalue 結構本身中的侵入式清單。
Value* location;
在結構 *ObjUpvalue* 中
struct ObjUpvalue* next;
} ObjUpvalue;
當我們配置一個 upvalue 時,它還沒有附加到任何清單,因此連結是 NULL。
upvalue->location = slot;
在 newUpvalue() 中
upvalue->next = NULL;
return upvalue;
VM 擁有該清單,因此頭部指標會直接放入主要的 VM 結構中。
Table strings;
在結構 *VM* 中
ObjUpvalue* openUpvalues;
Obj* objects;
清單一開始是空的。
vm.frameCount = 0;
在 resetStack() 中
vm.openUpvalues = NULL;
}
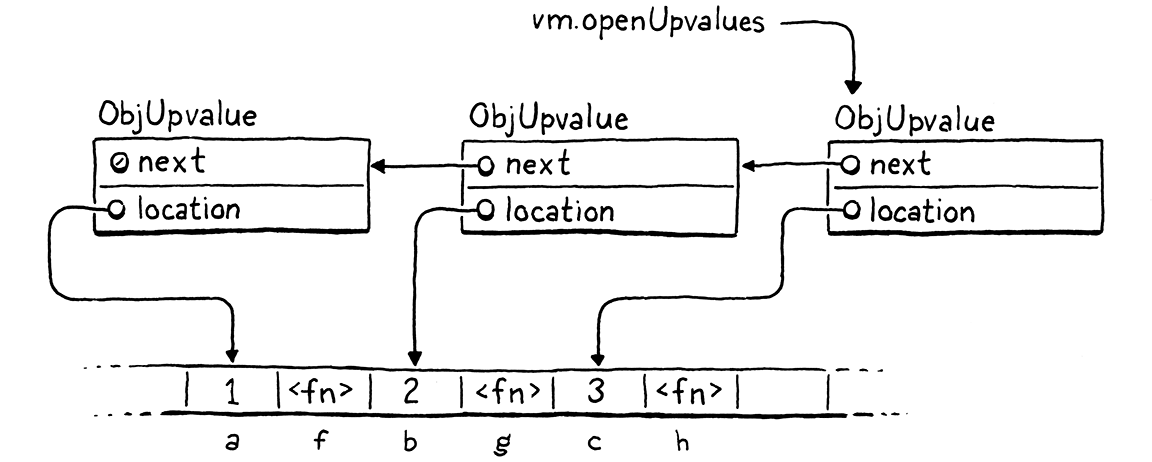
從 VM 指向的第一個 upvalue 開始,每個開放的 upvalue 都指向下一個開放的 upvalue,該 upvalue 參考堆疊上更下面的區域變數。例如,這個腳本,
{
var a = 1;
fun f() {
print a;
}
var b = 2;
fun g() {
print b;
}
var c = 3;
fun h() {
print c;
}
}
應該產生一系列像這樣的鏈結 upvalue
每當我們閉包一個區域變數時,在建立新的 upvalue 之前,我們會先在清單中尋找現有的 upvalue。
static ObjUpvalue* captureUpvalue(Value* local) {
在 captureUpvalue() 中
ObjUpvalue* prevUpvalue = NULL; ObjUpvalue* upvalue = vm.openUpvalues; while (upvalue != NULL && upvalue->location > local) { prevUpvalue = upvalue; upvalue = upvalue->next; } if (upvalue != NULL && upvalue->location == local) { return upvalue; }
ObjUpvalue* createdUpvalue = newUpvalue(local);
我們從清單的頭部開始,這是最接近堆疊頂端的 upvalue。我們走過清單,使用一個小的指標比較,迭代跳過每個指向我們正在尋找的槽上方的槽的 upvalue。當我們這樣做時,我們會追蹤清單中前一個 upvalue。如果我們最終在其後插入節點,我們將需要更新該節點的 next 指標。
我們有三個理由可以退出迴圈
-
我們停止的區域變數槽 *是* 我們正在尋找的槽。我們找到了一個現有的 upvalue 捕獲了該變數,因此我們重複使用該 upvalue。
-
我們已經用完要搜尋的 upvalue。當
upvalue為NULL時,表示清單中的每個開放 upvalue 都指向我們正在尋找的槽上方的區域變數,或者(更可能)upvalue 清單為空。無論哪種方式,我們都沒找到我們槽的 upvalue。 -
我們找到一個區域變數槽*低於*我們正在尋找的槽的 upvalue。由於清單已排序,這表示我們已經跳過了我們正在閉包的槽,因此一定沒有其現有的 upvalue。
在第一種情況下,我們完成了,並且已經傳回。否則,我們為我們的區域變數槽建立一個新的 upvalue,並將其插入到清單中的正確位置。
ObjUpvalue* createdUpvalue = newUpvalue(local);
在 captureUpvalue() 中
createdUpvalue->next = upvalue; if (prevUpvalue == NULL) { vm.openUpvalues = createdUpvalue; } else { prevUpvalue->next = createdUpvalue; }
return createdUpvalue;
此函式的目前版本已經建立 upvalue,因此我們只需要新增程式碼將 upvalue 插入清單中。我們退出清單遍歷的方式要嘛是跳過清單的結尾,要嘛是停止在第一個堆疊槽低於我們正在尋找的槽的 upvalue。無論哪種情況,這都表示我們需要將新的 upvalue 插入到 upvalue 所指向的物件*之前*(如果我們到達清單的結尾,則可能為 NULL)。
正如您可能在資料結構 101 中學到的,要將節點插入到鏈結串列中,您需要將前一個節點的 next 指標設定為指向您的新節點。當我們走過清單時,我們很方便地追蹤了前一個節點。我們還需要處理在清單的頭部插入新 upvalue 的特殊情況,在這種情況下,「next」指標是 VM 的頭部指標。
透過這個更新的函式,VM 現在確保對於任何給定的區域變數槽,只會有一個 ObjUpvalue。如果兩個閉包捕獲相同的變數,它們將會取得相同的 upvalue。我們現在準備將這些 upvalue 從堆疊中移出。
25 . 4 . 4在執行時期關閉 upvalue
編譯器會很有幫助地發出 OP_CLOSE_UPVALUE 指令,以準確告訴 VM 何時應該將區域變數提升到堆積中。執行該指令是解譯器的責任。
}
在 run() 中
case OP_CLOSE_UPVALUE: closeUpvalues(vm.stackTop - 1); pop(); break;
case OP_RETURN: {
當我們到達指令時,我們要提升的變數就在堆疊的最頂端。我們呼叫一個輔助函式,傳遞該堆疊槽的位址。該函式負責關閉 upvalue,並將區域變數從堆疊移動到堆積中。之後,VM 可以自由捨棄堆疊槽,它會透過呼叫 pop() 來執行此操作。
有趣的事情在這裡發生
在 captureUpvalue() 之後加入
static void closeUpvalues(Value* last) { while (vm.openUpvalues != NULL && vm.openUpvalues->location >= last) { ObjUpvalue* upvalue = vm.openUpvalues; upvalue->closed = *upvalue->location; upvalue->location = &upvalue->closed; vm.openUpvalues = upvalue->next; } }
此函式會取得指向堆疊槽的指標。它會關閉它可以找到的每一個指向該槽或堆疊上任何其上方槽的開放 upvalue。目前,我們只將指標傳遞到堆疊上的頂端槽,因此「或在其上方」部分不會起作用,但很快就會起作用。
為此,我們再次從上到下走過 VM 的開放 upvalue 清單。如果 upvalue 的位置指向我們正在關閉的槽範圍內,我們會關閉 upvalue。否則,一旦我們到達範圍外的 upvalue 時,我們知道其餘的也會在範圍外,因此我們停止迭代。
upvalue 被關閉的方式非常酷。首先,我們將變數的值複製到 ObjUpvalue 中的 closed 欄位。這就是封閉變數在堆積上的位置。OP_GET_UPVALUE 和 OP_SET_UPVALUE 指令需要在變數移動後在那裡尋找該變數。我們可以在這些指令的解譯器程式碼中新增一些條件邏輯,以檢查某些旗標,判斷 upvalue 是開放還是關閉。
但已經有間接層在作用了—這些指令會取消引用 location 指標以取得變數的值。當變數從堆疊移動到 closed 欄位時,我們只需將該 location 更新為 ObjUpvalue *自身*的 closed 欄位的位址即可。
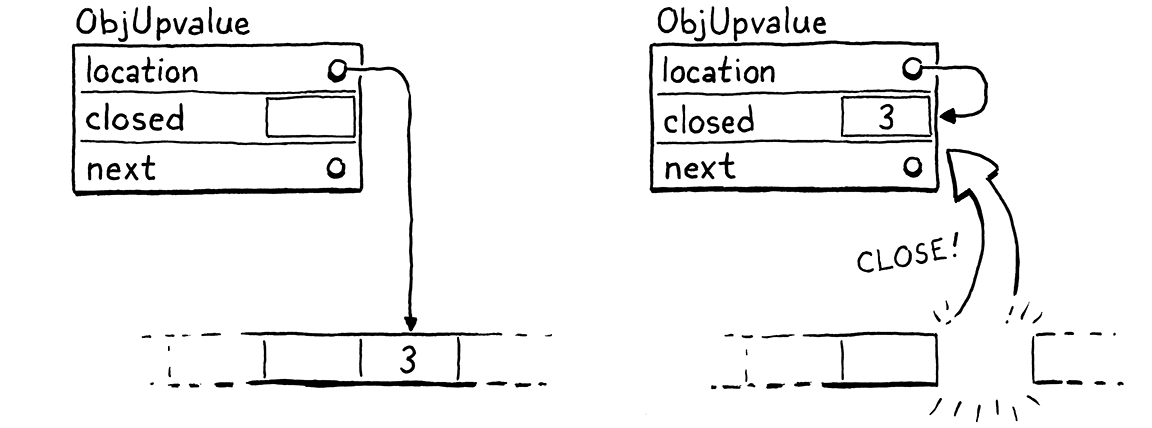
我們完全不需要變更 OP_GET_UPVALUE 和 OP_SET_UPVALUE 的解譯方式。這樣可以保持它們的簡單性,進而保持它們的快速性。但是,我們確實需要將新的欄位新增至 ObjUpvalue。
Value* location;
在結構 *ObjUpvalue* 中
Value closed;
struct ObjUpvalue* next;
而且我們應該在建立 ObjUpvalue 時將其歸零,這樣才不會有未初始化的記憶體到處流動。
ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE);
在 newUpvalue() 中
upvalue->closed = NIL_VAL;
upvalue->location = slot;
每當編譯器到達程式碼區塊的結尾時,它會捨棄該區塊中的所有區域變數,並為每個被閉包捕獲的區域變數發出一個 OP_CLOSE_UPVALUE 指令。編譯器在定義函式主體的最外層區塊範圍的結尾並不發出任何指令。該範圍包含函式的參數以及函式內立即宣告的任何區域變數。這些也需要被關閉。
這就是為什麼 closeUpvalues() 接受指向堆疊槽的指標的原因。當函式返回時,我們會呼叫同一個輔助函式,並傳入該函式所擁有的第一個堆疊槽。
Value result = pop();
在 run() 中
closeUpvalues(frame->slots);
vm.frameCount--;
透過傳入函式堆疊視窗中的第一個槽,我們會關閉返回函式所擁有的所有剩餘的開放向上值。這樣一來,我們現在就有了一個功能完整的閉包實現。被閉包捕獲的變數會在捕獲它們的函式需要它們時存活。
這真是做了很多工作!在 jlox 中,閉包是從我們的環境表示中自然產生的。在 clox 中,我們必須新增許多程式碼—新的位元組碼指令、編譯器中更多的資料結構,以及新的執行時物件。虛擬機器將閉包中的變數視為與其他變數非常不同。
這樣做是有理由的。就實作複雜度而言,jlox 給了我們「免費」的閉包。但是就效能而言,jlox 的閉包絕非如此。透過在堆積上分配所有環境,jlox 為所有區域變數付出了巨大的效能代價,即使大多數區域變數從未被閉包捕獲。
使用 clox,我們有一個更複雜的系統,但這使我們能夠調整實作以適應我們觀察到的區域變數的兩種使用模式。對於大多數具有堆疊語義的變數,我們會將它們完全分配在堆疊上,這樣既簡單又快速。然後,對於少數不適用的區域變數,我們有一個可以根據需要選擇使用的第二條較慢的路徑。
幸運的是,使用者感受不到這種複雜性。從他們的角度來看,Lox 中的區域變數既簡單又統一。語言本身與 jlox 的實作一樣簡單。但是在幕後,clox 會觀察使用者的操作,並針對他們的特定用途進行最佳化。隨著您的語言實作變得越來越複雜,您會發現自己會越來越多地這樣做。很大一部分的「最佳化」是關於新增特殊情況程式碼,這些程式碼會檢測某些用途,並為符合該模式的程式碼提供客製化、更快的路徑。
我們現在在 clox 中完全實作了詞法作用域,這是一個重要的里程碑。而且,現在我們有了具有複雜生命週期的函式和變數,我們也在 clox 的堆積中有很多物件在漂浮,並透過指標網路將它們串連在一起。 下一步是弄清楚如何管理該記憶體,以便我們可以在不再需要某些物件時釋放它們。
挑戰
-
將每個 ObjFunction 包裝在 ObjClosure 中會引入一個間接層級,這會產生效能成本。對於不關閉任何變數的函式來說,這種成本是不必要的,但它確實讓執行時環境可以一致地處理所有呼叫。
變更 clox,使其僅將需要向上值的函式包裝在 ObjClosures 中。程式碼複雜度和效能與始終包裝函式相比如何?請務必對使用和不使用閉包的程式進行基準測試。您應該如何權衡每個基準的重要性?如果一個變慢而另一個變快,您如何決定做出何種權衡以選擇實作策略?
-
閱讀下面的設計注意事項。我會等。現在,您認為 Lox 應該如何運作?變更實作,為每個迴圈迭代建立一個新變數。
-
一個著名的公案教導我們「物件是窮人的閉包」(反之亦然)。我們的虛擬機器還不支援物件,但是現在我們有了閉包,我們可以近似它們。使用閉包,編寫一個 Lox 程式來模擬二維向量「物件」。它應該
-
定義一個「建構函式」函式,以使用給定的 x 和 y 座標建立一個新的向量。
-
提供「方法」來存取該建構函式返回的值的 x 和 y 座標。
-
定義一個加法「方法」,將兩個向量相加並產生第三個向量。
-
設計注意事項:關閉迴圈變數
閉包捕獲變數。當兩個閉包捕獲同一個變數時,它們會共享對同一個底層儲存位置的引用。當將新值指派給變數時,此事實是可見的。顯然,如果兩個閉包捕獲不同的變數,則不存在共享。
var globalOne; var globalTwo; fun main() { { var a = "one"; fun one() { print a; } globalOne = one; } { var a = "two"; fun two() { print a; } globalTwo = two; } } main(); globalOne(); globalTwo();
這會印出「one」然後印出「two」。在這個範例中,很明顯這兩個 a 變數是不同的。但並不總是這麼明顯。考慮一下
var globalOne; var globalTwo; fun main() { for (var a = 1; a <= 2; a = a + 1) { fun closure() { print a; } if (globalOne == nil) { globalOne = closure; } else { globalTwo = closure; } } } main(); globalOne(); globalTwo();
程式碼很複雜,因為 Lox 沒有集合類型。重要的部分是 main() 函式執行兩次 for 迴圈的迭代。每次通過迴圈時,它都會建立一個捕獲迴圈變數的閉包。它將第一個閉包儲存在 globalOne 中,將第二個儲存在 globalTwo 中。
絕對有兩個不同的閉包。它們是否關閉了兩個不同的變數?整個迴圈期間只有一個 a,還是每次迭代都會取得其自己的獨立 a 變數?
這裡的腳本很奇怪且牽強,但這確實會出現在不像 clox 那樣簡約的語言的實際程式碼中。這是一個 JavaScript 範例
var closures = []; for (var i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
這會印出「1」然後印出「2」,還是印出「3」兩次?您可能會驚訝地聽到它印出「3」兩次。在這個 JavaScript 程式中,只有一個 i 變數,其生命週期包含迴圈的所有迭代,包括最終結束。
如果您熟悉 JavaScript,您可能知道使用 var 宣告的變數會隱式提升到周圍的函式或頂層範圍。就像您真的寫成這樣一樣
var closures = []; var i; for (i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
在這一點上,很明顯只有一個 i。現在考慮一下,如果您變更程式以使用較新的 let 關鍵字
var closures = []; for (let i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
這個新程式的行為是否相同?不會。在這種情況下,它會印出「1」然後印出「2」。每個閉包都會取得自己的 i。當您想到它時,這有點奇怪。遞增子句是 i++。這看起來非常像是指派給並變更現有的變數,而不是建立一個新的變數。
讓我們嘗試其他一些語言。這是 Python
closures = [] for i in range(1, 3): closures.append(lambda: print(i)) closures[0]() closures[1]()
Python 並沒有真正的區塊作用域。變數是隱式宣告的,並且會自動設定為周圍函式的作用域。現在想想,有點像 JS 中的提升。因此,兩個閉包都捕獲同一個變數。但是,與 C 不同的是,我們不會透過將 i 遞增超過最後一個值來結束迴圈,因此這會印出「2」兩次。
Ruby 呢? Ruby 有兩種典型的數值迭代方式。這是經典的命令式樣式
closures = [] for i in 1..2 do closures << lambda { puts i } end closures[0].call closures[1].call
和 Python 一樣,這會印出「2」兩次。但是,更符合 Ruby 習慣的樣式是在範圍物件上使用高階 each() 方法
closures = [] (1..2).each do |i| closures << lambda { puts i } end closures[0].call closures[1].call
如果您不熟悉 Ruby,do |i| ... end 部分基本上是一個被建立並傳遞給 each() 方法的閉包。 |i| 是閉包的參數簽名。 each() 方法會調用該閉包兩次,第一次傳入 1 作為 i,第二次傳入 2。
在這種情況下,「迴圈變數」實際上是一個函式參數。而且,由於迴圈的每次迭代都是對函式的單獨調用,因此對於每個呼叫來說,這些絕對是單獨的變數。因此,這會印出「1」然後印出「2」。
如果一種語言具有基於迭代器的高階迴圈結構,例如 C# 中的 foreach、Java 的「增強型 for」、JavaScript 中的 for-of、Dart 中的 for-in 等,那麼我認為對於讀者來說,每次迭代建立一個新變數是很自然的。程式碼看起來像是新變數,因為迴圈標頭看起來像是變數宣告。而且沒有遞增運算式看起來像是要變更該變數以進入下一步。
如果您在 StackOverflow 和其他地方搜尋,您會發現證據表明這正是使用者所期望的,因為當他們沒有得到時,他們會感到非常驚訝。特別是,C# 最初並未為 foreach 迴圈的每次迭代建立一個新的迴圈變數。這是一個經常造成使用者困惑的原因,因此他們採取了非常罕見的步驟,對該語言發布了重大變更。在 C# 5 中,每次迭代都會建立一個新的變數。
舊的 C 風格 for 迴圈更難。遞增子句看起來確實像是變更。這意味著只有一個變數會在每個步驟中被更新。但是,對於每次迭代來說,共享一個迴圈變數幾乎永遠沒有用。您甚至可以偵測到這一點的唯一時間是閉包捕獲它時。而且,擁有一個引用變數的閉包,而該變數的值是導致您結束迴圈的值,通常沒有幫助。
務實的有用答案可能是像 JavaScript 在 for 迴圈中使用 let 那樣做。讓它看起來像是變更,但實際上每次都建立一個新變數,因為這是使用者想要的。儘管當您想到它時,這有點奇怪。