呼叫與函式
電腦科學中的任何問題都可以透過增加一層間接層次來解決。除了間接層次太多的問題。
David Wheeler
本章是一個龐然大物。我嘗試將功能分解成小塊,但有時你必須吞下整個餐點。我們的下一個任務是函式。我們可以從只有函式宣告開始,但是當你無法呼叫它們時,這就不是很有用。我們可以進行呼叫,但沒有什麼可以呼叫。而且,如果沒有連接到任何你可看到的東西,在 VM 中支援兩者的所有運行時支援也不是很有回報。所以我們將全部完成。這很多,但是當我們完成時,我們會感覺良好。
24 . 1函式物件
VM 中最有趣的結構變化是圍繞堆疊。我們已經有一個用於區域變數和暫存器的堆疊,所以我們已經完成了一半。但是我們沒有呼叫堆疊的概念。在我們取得重大進展之前,我們必須解決這個問題。但是首先,讓我們編寫一些程式碼。一旦我開始行動,我總是感覺好多了。如果沒有某種函式的表示形式,我們就無法做太多事情,所以我們先從那裡開始。從 VM 的角度來看,函式是什麼?
函式有一個可以執行的主體,所以這表示一些位元組碼。我們可以將整個程式及其所有函式宣告編譯成一個大的單塊 Chunk。每個函式都會有一個指向 Chunk 內部程式碼的第一個指令的指標。
這大致是編譯為原生程式碼的工作方式,你會得到一個堅實的機器碼 Blob。但是對於我們的位元組碼 VM,我們可以做一些更高層次的事情。我認為一個更乾淨的模型是給每個函式自己的 Chunk。我們還需要一些其他元數據,所以讓我們現在就把所有東西都塞進一個 struct 中。
struct Obj* next; };
在 struct Obj 之後新增
typedef struct { Obj obj; int arity; Chunk chunk; ObjString* name; } ObjFunction;
struct ObjString {
函式在 Lox 中是一級的,所以它們需要是實際的 Lox 物件。因此,ObjFunction 具有所有物件類型共有的相同 Obj 標頭。arity 欄位會儲存函式預期的參數數量。然後,除了 chunk 之外,我們還會儲存函式的名稱。這對於報告可讀的執行時錯誤會很方便。
這是「object」模組第一次需要參考 Chunk,所以我們取得一個包含項目。
#include "common.h"
#include "chunk.h"
#include "value.h"
就像我們對字串所做的那樣,我們定義了一些輔助工具,使 C 中的 Lox 函式更容易使用。有點像是窮人的物件導向。首先,我們將宣告一個 C 函式來建立一個新的 Lox 函式。
uint32_t hash; };
在 struct ObjString 之後新增
ObjFunction* newFunction();
ObjString* takeString(char* chars, int length);
實作在這裡
在 allocateObject() 之後新增
ObjFunction* newFunction() { ObjFunction* function = ALLOCATE_OBJ(ObjFunction, OBJ_FUNCTION); function->arity = 0; function->name = NULL; initChunk(&function->chunk); return function; }
我們使用我們的朋友 ALLOCATE_OBJ() 來分配記憶體並初始化物件的標頭,以便 VM 知道它是什麼類型的物件。我們沒有像使用 ObjString 那樣傳入參數來初始化函式,而是以一種空白狀態設定函式—零參數數量、沒有名稱,也沒有程式碼。這將在稍後建立函式後填入。
由於我們有一種新的物件類型,我們需要在 enum 中加入新的物件類型。
typedef enum {
在 enum ObjType 中
OBJ_FUNCTION,
OBJ_STRING, } ObjType;
當我們完成函式物件時,我們必須將其借用的位元歸還給作業系統。
switch (object->type) {
在 freeObject() 中
case OBJ_FUNCTION: { ObjFunction* function = (ObjFunction*)object; freeChunk(&function->chunk); FREE(ObjFunction, object); break; }
case OBJ_STRING: {
這個 switch case 負責釋放 ObjFunction 本身以及它擁有的任何其他記憶體。函式擁有它們的 chunk,所以我們呼叫 Chunk 的解構函式。
Lox 讓你列印任何物件,而函式是一級物件,所以我們也需要處理它們。
switch (OBJ_TYPE(value)) {
在 printObject() 中
case OBJ_FUNCTION: printFunction(AS_FUNCTION(value)); break;
case OBJ_STRING:
這會呼叫
在 copyString() 之後新增
static void printFunction(ObjFunction* function) { printf("<fn %s>", function->name->chars); }
由於函式知道它的名稱,因此它不妨說出來。
最後,我們有幾個巨集用於將值轉換為函式。首先,請確保你的值實際上是一個函式。
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
#define IS_STRING(value) isObjType(value, OBJ_STRING)
假設評估為 true,那麼你可以使用這個將 Value 安全地轉換為 ObjFunction 指標
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
#define AS_STRING(value) ((ObjString*)AS_OBJ(value))
這樣一來,我們的物件模型就知道如何表示函式了。我現在感覺熱身了。你準備好迎接更困難的事情了嗎?
24 . 2編譯為函式物件
現在,我們的編譯器假設它始終編譯為單個 chunk。隨著每個函式的程式碼存在於單獨的 chunk 中,情況變得更加複雜。當編譯器到達函式宣告時,它需要在編譯其主體時將程式碼發射到函式的 chunk 中。在函式主體的末尾,編譯器需要返回到先前正在使用的 chunk。
對於函式主體內的程式碼來說,這沒有問題,但是沒有在其中的程式碼呢?Lox 程式的「頂層」也是命令式程式碼,我們需要一個 chunk 來將其編譯到其中。我們可以透過將頂層程式碼也放置在自動定義的函式內來簡化編譯器和 VM。這樣,編譯器始終在某種函式主體內,而 VM 始終透過呼叫函式來執行程式碼。就像整個程式都包裝在隱式的 main() 函式中一樣。
在我們開始使用使用者定義的函式之前,讓我們進行重組以支援隱式的頂層函式。它從 Compiler struct 開始。它不是直接指向編譯器寫入的 Chunk,而是具有對正在建構的函式物件的參考。
typedef struct {
在 struct Compiler 中
ObjFunction* function; FunctionType type;
Local locals[UINT8_COUNT];
我們也有一個小的 FunctionType 列舉。這讓編譯器知道何時編譯頂層程式碼與函式主體。大多數編譯器並不關心這個—這就是為什麼它是一個有用的抽象—但在一個或兩個地方,這種區別是有意義的。我們稍後會談到一個。
在 struct Local 之後新增
typedef enum { TYPE_FUNCTION, TYPE_SCRIPT } FunctionType;
編譯器中每個寫入 Chunk 的地方現在都需要透過該 function 指標。幸運的是,在許多章節之前,我們將對 chunk 的存取封裝在 currentChunk() 函式中。我們只需要修復它,其餘的編譯器就會很高興。
Compiler* current = NULL;
在變數 current 之後新增
取代 5 行
static Chunk* currentChunk() { return ¤t->function->chunk; }
static void errorAt(Token* token, const char* message) {
目前的 chunk 始終是我們正在編譯的中間函式所擁有的 chunk。接下來,我們需要實際建立該函式。以前,VM 將 Chunk 傳遞給編譯器,該編譯器會用程式碼填滿它。相反地,編譯器將建立並傳回一個函式,其中包含編譯的頂層程式碼—這就是我們現在支援的全部—的使用者程式。
24 . 2 . 1在編譯時建立函式
我們從 compile() 中開始將它穿線,這是進入編譯器的主要入口點。
Compiler compiler;
在 compile() 中
取代 2 行
initCompiler(&compiler, TYPE_SCRIPT);
parser.hadError = false;
編譯器的初始化方式有很多變化。首先,我們初始化新的 Compiler 欄位。
函式 initCompiler()
取代 1 行
static void initCompiler(Compiler* compiler, FunctionType type) { compiler->function = NULL; compiler->type = type;
compiler->localCount = 0;
然後,我們分配一個新的函式物件來編譯到其中。
compiler->scopeDepth = 0;
在 initCompiler() 中
compiler->function = newFunction();
current = compiler;
在編譯器中建立 ObjFunction 可能看起來有點奇怪。函式物件是函式的運行時表示,但我們在這裡是在編譯時建立它。考慮它的方式是,函式類似於字串或數字常值。它構成了編譯時和運行時世界之間的橋樑。當我們開始處理函式宣告時,它們確實是常值—它們是一種產生內建類型值的符號。因此,編譯器會在編譯期間建立函式物件。然後,在執行時,它們只會被呼叫。
這裡有另一段奇怪的程式碼
current = compiler;
在 initCompiler() 中
Local* local = ¤t->locals[current->localCount++]; local->depth = 0; local->name.start = ""; local->name.length = 0;
}
請記住,編譯器的 locals 陣列會追蹤哪些堆疊槽與哪些局部變數或臨時變數相關聯。從現在開始,編譯器會隱式地宣告堆疊槽零供 VM 內部使用。我們給它一個空名稱,以便使用者無法寫出引用它的識別符號。當它變得有用時,我會解釋這是怎麼回事。
這是初始化的一方。當我們完成編譯某些程式碼時,另一端也需要做一些變更。
函式 endCompiler()
取代 1 行
static ObjFunction* endCompiler() {
emitReturn();
先前,當 interpret() 呼叫編譯器時,它會傳入一個要寫入的 Chunk。現在編譯器本身會建立函式物件,我們返回該函式。我們從這裡的目前編譯器中取得它
emitReturn();
在 endCompiler() 中
ObjFunction* function = current->function;
#ifdef DEBUG_PRINT_CODE
然後像這樣將它返回給 compile()
#endif
在 endCompiler() 中
return function;
}
現在是在此函式中進行另一個調整的好時機。先前,我們新增了一些診斷程式碼,讓 VM 轉儲反組譯的位元組碼,以便我們可以除錯編譯器。我們應該修正它,使其在產生的 chunk 包裝在函式中後仍能繼續運作。
#ifdef DEBUG_PRINT_CODE
if (!parser.hadError) {
在 endCompiler() 中
取代 1 行
disassembleChunk(currentChunk(), function->name != NULL ? function->name->chars : "<script>");
} #endif
請注意此處的檢查,以查看函式的名稱是否為 NULL?使用者定義的函式有名稱,但是我們為頂層程式碼建立的隱式函式沒有名稱,即使在我們自己的診斷程式碼中,我們也需要優雅地處理它。說到這
static void printFunction(ObjFunction* function) {
在 printFunction() 中
if (function->name == NULL) { printf("<script>"); return; }
printf("<fn %s>", function->name->chars);
使用者無法取得對頂層函式的參考並嘗試列印它,但是我們列印整個堆疊的 DEBUG_TRACE_EXECUTION 診斷程式碼可以而且確實會這樣做。
將層級提高到 compile(),我們調整其簽名。
#include "vm.h"
函式 compile()
取代 1 行
ObjFunction* compile(const char* source);
#endif
現在它會返回一個函式,而不是接收一個 chunk。在實作中
函式 compile()
取代 1 行
ObjFunction* compile(const char* source) {
initScanner(source);
最後,我們得到一些實際的程式碼。我們將函式結尾變更為此
while (!match(TOKEN_EOF)) {
declaration();
}
在 compile() 中
取代 2 行
ObjFunction* function = endCompiler(); return parser.hadError ? NULL : function;
}
我們從編譯器取得函式物件。如果沒有編譯錯誤,我們會返回它。否則,我們會透過返回 NULL 來發出錯誤訊號。這樣,VM 就不會嘗試執行可能包含無效位元組碼的函式。
最終,我們將更新 interpret() 以處理 compile() 的新宣告,但首先我們還有一些其他變更要做。
24. 3呼叫框架
現在是進行重大概念飛躍的時候了。在我們可以實作函式宣告和呼叫之前,我們需要讓 VM 準備好處理它們。我們需要擔心的主要問題有兩個
24. 3. 1配置局部變數
編譯器會為局部變數配置堆疊槽。當程式中的局部變數集分佈在多個函式中時,應該如何運作?
一種選擇是將它們完全分開。每個函式都會在 VM 堆疊中取得其專用的槽集,它會 永久擁有這些槽,即使該函式未被呼叫也是如此。整個程式中的每個局部變數都會在 VM 中擁有一小塊記憶體,供自己使用。
信不信由你,早期的程式語言實作就是這樣運作的。第一個 Fortran 編譯器會為每個變數靜態配置記憶體。顯而易見的問題是,這樣效率很低。大多數函式在任何時間點都不處於被呼叫的狀態,因此為它們保留未使用的記憶體是浪費的。
但更根本的問題是遞迴。使用遞迴時,您可以同時「進入」對同一個函式的多次呼叫。每次呼叫都需要自己的記憶體來儲存其局部變數。在 jlox 中,我們透過在每次呼叫函式或進入程式碼區塊時動態配置環境記憶體來解決此問題。在 clox 中,我們不希望每次函式呼叫都付出這種效能成本。
相反地,我們的解決方案介於 Fortran 的靜態配置和 jlox 的動態方法之間。VM 中的值堆疊基於以下觀察結果:局部變數和臨時變數的行為方式為後進先出。幸運的是,即使您在組合中加入函式呼叫,情況仍然如此。以下是一個範例
fun first() { var a = 1; second(); var b = 2; } fun second() { var c = 3; var d = 4; } first();
逐步執行程式,並查看每次哪些變數在記憶體中
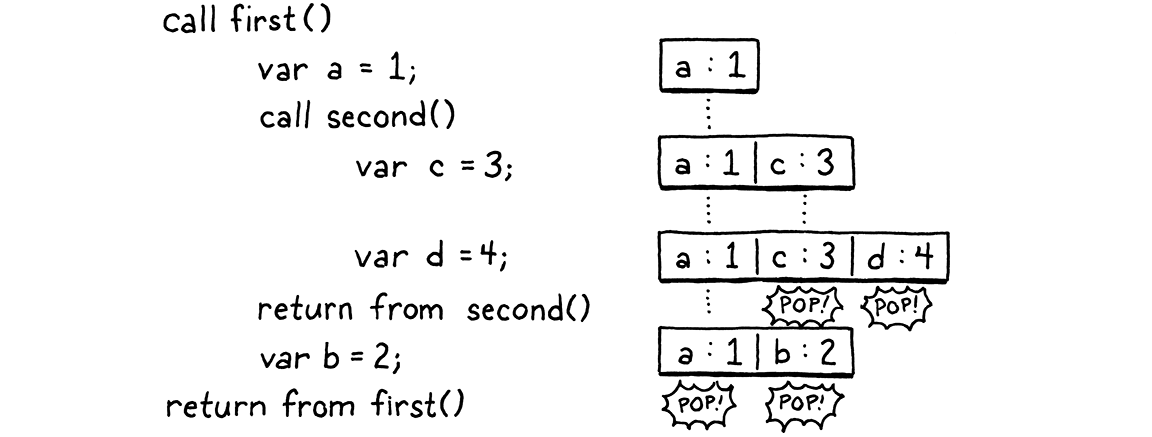
當執行流程流經這兩個呼叫時,每個局部變數都遵守一個原則:在第一個變數需要使用之前,任何在其之後宣告的變數都將被捨棄。即使跨呼叫,情況也是如此。我們知道我們將在完成 a 之前完成 c 和 d。看來我們應該能夠在 VM 的值堆疊上配置局部變數。
理想情況下,我們仍然可以在編譯時期決定每個變數在堆疊中的位置。這可以讓處理變數的位元組碼指令保持簡單快速。在上面的範例中,我們可以想像以直接的方式進行此操作,但這並不總是有效。考慮
fun first() { var a = 1; second(); var b = 2; second(); } fun second() { var c = 3; var d = 4; } first();
在第一次呼叫 second() 時,c 和 d 將進入插槽 1 和 2。但在第二次呼叫時,我們需要為 b 騰出空間,因此 c 和 d 需要在插槽 2 和 3 中。因此,編譯器無法在函式呼叫之間為每個局部變數釘住確切的插槽。但是,在給定的函式內,每個局部變數的相對位置是固定的。變數 d 始終位於 c 之後的插槽中。這是關鍵的見解。
當呼叫函式時,我們不知道堆疊的頂部會在哪裡,因為它可以從不同的內容呼叫。但是,無論頂部在哪裡,我們都知道函式的所有局部變數相對於該起始點的位置。因此,與許多問題一樣,我們透過間接層級解決了配置問題。
在每次函式呼叫的開頭,VM 會記錄該函式自己的局部變數開始的第一個插槽的位置。處理局部變數的指令會透過相對於該位置的插槽索引來存取它們,而不是像今天一樣相對於堆疊的底部來存取它們。在編譯時期,我們會計算這些相對插槽。在執行時期,我們會透過加上函式呼叫的起始插槽,將該相對插槽轉換為絕對堆疊索引。
就好像函式在較大的堆疊中獲得一個「視窗」或「框架」,它可以在其中儲存其局部變數。呼叫框架的位置在執行時期決定,但在該區域內及其相對位置,我們知道在哪裡可以找到東西。
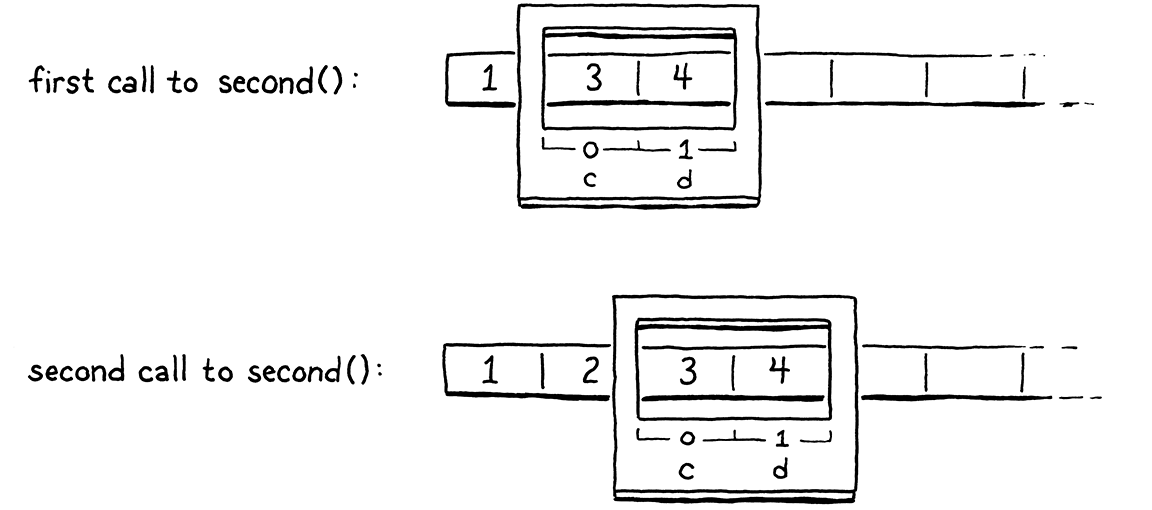
記錄函式局部變數起始位置的歷史名稱是框架指標,因為它指向函式呼叫框架的開頭。有時您會聽到基底指標,因為它指向所有函式變數所在的基底堆疊槽。
這是我們需要追蹤的第一個資料。每次我們呼叫函式時,VM 都會判斷該函式的變數開始的第一個堆疊槽。
24. 3. 2返回位址
現在,VM 會透過遞增 ip 欄位來執行指令流。唯一有趣的行為是圍繞著將 ip 偏移較大數量的控制流程指令。呼叫函式非常簡單—只需將 ip 設定為指向該函式 chunk 中的第一個指令即可。但是當函式完成時呢?
VM 需要返回到呼叫函式的 chunk,並在呼叫後立即在指令處恢復執行。因此,對於每個函式呼叫,我們需要追蹤當呼叫完成時我們跳回的位置。這稱為返回位址,因為它是 VM 在呼叫後返回的指令位址。
同樣,由於遞迴,單一函式可能有多個返回位址,因此這是每次叫用的屬性,而不是函式本身的屬性。
24. 3. 3呼叫堆疊
因此,對於每個作用中的函式叫用—每個尚未返回的呼叫—我們都需要追蹤該函式的局部變數在堆疊中的哪個位置開始,以及呼叫者應在何處恢復。我們會將此與其他一些東西一起放入新的結構中。
#define STACK_MAX 256
typedef struct { ObjFunction* function; uint8_t* ip; Value* slots; } CallFrame;
typedef struct {
CallFrame 代表單一持續的函式呼叫。slots 欄位指向 VM 的值堆疊中此函式可以使用的第一個插槽。我給它一個複數名稱,因為—感謝 C 的怪異「指標有點像陣列」的東西—我們會將它視為陣列。
返回位址的實作與我上面描述的略有不同。呼叫者不是將返回位址儲存在被呼叫者的框架中,而是儲存自己的 ip。當我們從函式返回時,VM 會跳到呼叫者 CallFrame 的 ip 並從那裡恢復。
我還在這裡塞入一個指向被呼叫函式的指標。我們將使用它來查找常數並進行其他一些操作。
每次呼叫函式時,我們都會建立一個這種結構。我們可以動態地在堆積上配置它們,但這樣很慢。函式呼叫是核心操作,因此它們需要盡可能快。幸運的是,我們可以做出與變數相同的觀察:函式呼叫具有堆疊語義。如果 first() 呼叫 second(),則對 second() 的呼叫會在 first() 完成之前完成。
因此,在 VM 中,我們預先建立一個此類 CallFrame 結構的陣列,並像處理值陣列一樣將其視為堆疊。
typedef struct {
在 VM 結構中
取代 2 行
CallFrame frames[FRAMES_MAX]; int frameCount;
Value stack[STACK_MAX];
此陣列取代了我們過去直接在 VM 中使用的 chunk 和 ip 欄位。現在,每個 CallFrame 都有自己的 ip 和指向其正在執行的 ObjFunction 的指標。從那裡,我們可以存取函式的 chunk。
VM 中的新 frameCount 欄位儲存 CallFrame 堆疊的目前高度—正在進行的函式呼叫數。為了保持 clox 的簡單性,陣列的容量是固定的。這意味著,與許多語言實作一樣,我們可以處理的最大呼叫深度是有限的。對於 clox,它在此處定義
#include "value.h"
取代 1 行
#define FRAMES_MAX 64 #define STACK_MAX (FRAMES_MAX * UINT8_COUNT)
typedef struct {
我們還根據它重新定義值堆疊的大小,以確保即使在非常深的呼叫樹中,我們也有足夠的堆疊插槽。當 VM 啟動時,CallFrame 堆疊是空的。
vm.stackTop = vm.stack;
在 resetStack() 中
vm.frameCount = 0;
}
“vm.h”標頭需要存取 ObjFunction,因此我們加入一個 include。
#define clox_vm_h
取代 1 行
#include "object.h"
#include "table.h"
現在我們準備好移至 VM 的實作檔案。我們有一些繁瑣的工作要做。我們已將 ip 從 VM 結構移至 CallFrame。我們需要修正 VM 中每一行觸及 ip 的程式碼以處理此問題。此外,需要更新依堆疊插槽存取區域變數的指令,以相對於目前 CallFrame 的 slots 欄位執行此操作。
我們將從頂部開始並逐一完成它。
static InterpretResult run() {
在 run() 中
取代 4 行
CallFrame* frame = &vm.frames[vm.frameCount - 1]; #define READ_BYTE() (*frame->ip++) #define READ_SHORT() \ (frame->ip += 2, \ (uint16_t)((frame->ip[-2] << 8) | frame->ip[-1])) #define READ_CONSTANT() \ (frame->function->chunk.constants.values[READ_BYTE()])
#define READ_STRING() AS_STRING(READ_CONSTANT())
首先,我們將目前最頂端的 CallFrame 儲存在主要位元組碼執行函式中的區域變數中。然後,我們將位元組碼存取巨集替換為透過該變數存取 ip 的版本。
現在開始處理每個需要一點細心照顧的指令。
case OP_GET_LOCAL: {
uint8_t slot = READ_BYTE();
在 run() 中
取代 1 行
push(frame->slots[slot]);
break;
先前,OP_GET_LOCAL 直接從 VM 的堆疊陣列讀取給定的區域插槽,這意味著它會從堆疊底部開始索引該插槽。現在,它會存取目前框架的 slots 陣列,這表示它會相對於該框架的開頭存取給定的編號插槽。
設定區域變數的方式相同。
case OP_SET_LOCAL: {
uint8_t slot = READ_BYTE();
在 run() 中
取代 1 行
frame->slots[slot] = peek(0);
break;
跳躍指令過去會修改 VM 的 ip 欄位。現在,它們對目前框架的 ip 執行相同的操作。
case OP_JUMP: {
uint16_t offset = READ_SHORT();
在 run() 中
取代 1 行
frame->ip += offset;
break;
條件跳躍也相同
case OP_JUMP_IF_FALSE: {
uint16_t offset = READ_SHORT();
在 run() 中
取代 1 行
if (isFalsey(peek(0))) frame->ip += offset;
break;
還有我們的向後跳躍迴圈指令
case OP_LOOP: {
uint16_t offset = READ_SHORT();
在 run() 中
取代 1 行
frame->ip -= offset;
break;
我們有一些診斷程式碼,會在執行時列印每個指令,以協助我們偵錯 VM。這也需要使用新的結構。
printf("\n");
在 run() 中
取代 2 行
disassembleInstruction(&frame->function->chunk, (int)(frame->ip - frame->function->chunk.code));
#endif
現在,我們不再傳入 VM 的 chunk 和 ip 欄位,而是從目前的 CallFrame 讀取。
你知道嗎,其實也沒那麼糟。大多數指令都只使用巨集,因此不需要修改。接下來,我們將跳到呼叫 run() 的程式碼層級。
InterpretResult interpret(const char* source) {
在 interpret() 中
取代 10 行
ObjFunction* function = compile(source); if (function == NULL) return INTERPRET_COMPILE_ERROR; push(OBJ_VAL(function)); CallFrame* frame = &vm.frames[vm.frameCount++]; frame->function = function; frame->ip = function->chunk.code; frame->slots = vm.stack;
InterpretResult result = run();
我們終於將先前的編譯器變更與我們剛才所做的後端變更連結起來。首先,我們將原始碼傳遞給編譯器。它會傳回一個新的 ObjFunction,其中包含已編譯的頂層程式碼。如果我們收到 NULL,則表示編譯時發生了一些錯誤,編譯器已回報。在這種情況下,我們會退出,因為我們無法執行任何動作。
否則,我們會將函式儲存在堆疊上,並準備一個初始 CallFrame 來執行其程式碼。現在您可以了解為什麼編譯器會保留堆疊插槽零—該插槽會儲存正在呼叫的函式。在新的 CallFrame 中,我們會指向函式,將其 ip 初始化為指向函式位元組碼的開頭,並設定其堆疊視窗以從 VM 的值堆疊的最底部開始。
這會讓直譯器準備好開始執行程式碼。完成後,VM 過去會釋放硬式編碼的 chunk。現在,ObjFunction 擁有該程式碼,我們不再需要執行此操作,因此 interpret() 的結尾只是這樣
frame->slots = vm.stack;
在 interpret() 中
取代 4 行
return run();
}
最後一段參考舊 VM 欄位的程式碼是 runtimeError()。我們將在本章稍後重新探討它,但現在讓我們將其變更為這樣
fputs("\n", stderr);
在 runtimeError() 中
取代 2 行
CallFrame* frame = &vm.frames[vm.frameCount - 1]; size_t instruction = frame->ip - frame->function->chunk.code - 1; int line = frame->function->chunk.lines[instruction];
fprintf(stderr, "[line %d] in script\n", line);
它不再直接從 VM 讀取 chunk 和 ip,而是從堆疊最頂端的 CallFrame 中提取這些值。這應該會使函式再次運作並像以前一樣執行。
假設我們都正確地執行了以上操作,我們就讓 clox 回到了可執行的狀態。啟動它,它就會 . . . 執行與之前完全相同的操作。我們尚未新增任何新功能,因此這有點令人失望。但所有的基礎設施都已就緒,可以讓我們使用。讓我們善用它。
24 . 4函式宣告
在我們可以使用呼叫運算式之前,我們需要一些可以呼叫的東西,因此我們先進行函式宣告。fun 以關鍵字開頭。
static void declaration() {
在 declaration() 中
取代 1 行
if (match(TOKEN_FUN)) { funDeclaration(); } else if (match(TOKEN_VAR)) {
varDeclaration();
這會將控制權傳遞到這裡
在 block() 之後加入
static void funDeclaration() { uint8_t global = parseVariable("Expect function name."); markInitialized(); function(TYPE_FUNCTION); defineVariable(global); }
函式是一級值,而函式宣告只是建立一個函式並將其儲存在新宣告的變數中。因此,我們像處理任何其他變數宣告一樣剖析名稱。頂層的函式宣告會將函式繫結至全域變數。在區塊或其他函式內,函式宣告會建立區域變數。
在較早的章節中,我解釋了變數如何在兩個階段定義。這可確保您無法在變數自己的初始化程式中存取變數的值。這很糟糕,因為變數還沒有值。
函式不會遇到這個問題。函式在其主體中參考自己的名稱是安全的。在完全定義之前,您無法呼叫函式並執行主體,因此您永遠不會看到未初始化狀態的變數。實際上,允許這樣做對於支援遞迴區域函式很有用。
為了使之運作,我們會在編譯名稱時立即將函式宣告的變數標記為「已初始化」,然後再編譯主體。這樣一來,名稱就可以在主體內被參考,而不會產生錯誤。
但是,我們確實需要一個檢查。
static void markInitialized() {
在 markInitialized() 中
if (current->scopeDepth == 0) return;
current->locals[current->localCount - 1].depth =
之前,我們只會在知道我們位於區域範圍內時才呼叫 markInitialized()。現在,頂層的函式宣告也會呼叫此函式。發生這種情況時,沒有要標記為已初始化的區域變數—該函式會繫結至全域變數。
接下來,我們編譯函式本身—其參數清單和區塊主體。為此,我們使用單獨的輔助函式。該輔助函式會產生程式碼,將產生的函式物件保留在堆疊的頂端。之後,我們呼叫 defineVariable() 以將該函式儲存回我們為其宣告的變數中。
我將編譯參數和主體的程式碼分開,因為我們稍後將重複使用它來剖析類別內的方法宣告。讓我們從這個開始逐步建構它
在 block() 之後加入
static void function(FunctionType type) { Compiler compiler; initCompiler(&compiler, type); beginScope(); consume(TOKEN_LEFT_PAREN, "Expect '(' after function name."); consume(TOKEN_RIGHT_PAREN, "Expect ')' after parameters."); consume(TOKEN_LEFT_BRACE, "Expect '{' before function body."); block(); ObjFunction* function = endCompiler(); emitBytes(OP_CONSTANT, makeConstant(OBJ_VAL(function))); }
目前,我們不會擔心參數。我們剖析一對空的括號,後接主體。主體以左大括號開頭,我們在此處剖析它。然後,我們呼叫現有的 block() 函式,該函式知道如何編譯包括右大括號在內的其餘區塊。
24 . 4 . 1編譯器的堆疊
有趣的部分是頂部和底部的編譯器程式碼。Compiler 結構會儲存資料,例如哪些插槽由哪些區域變數擁有、我們目前處於多少層巢狀區塊等等。所有這些都特定於單個函式。但是,現在前端需要處理編譯彼此巢狀的多個函式。
管理此問題的訣竅是為正在編譯的每個函式建立單獨的 Compiler。當我們開始編譯函式宣告時,我們會在 C 堆疊上建立新的 Compiler 並對其進行初始化。initCompiler() 會將該 Compiler 設定為目前的 Compiler。然後,當我們編譯主體時,所有發出位元組碼的函式都會寫入由新 Compiler 的函式擁有的 chunk。
在我們到達函式區塊主體的末尾之後,我們會呼叫 endCompiler()。這會產生新編譯的函式物件,我們將其儲存為周圍函式的常數表中的常數。但是,等等,我們要如何回到周圍的函式?當 initCompiler() 覆寫目前的編譯器指標時,我們遺失了它。
我們透過將一系列巢狀 Compiler 結構視為堆疊來修正此問題。與 VM 中的 Value 和 CallFrame 堆疊不同,我們不會使用陣列。相反地,我們使用連結清單。每個 Compiler 都會指回包含它的函式的 Compiler,一直回到頂層程式碼的根 Compiler。
} FunctionType;
在列舉 FunctionType 之後加入
取代 1 行
typedef struct Compiler { struct Compiler* enclosing;
ObjFunction* function;
在 Compiler 結構內部,我們無法參考 Compiler typedef,因為該宣告尚未完成。相反地,我們為結構本身命名,並將其用於欄位的類型。C 很奇怪。
當初始化新的 Compiler 時,我們會以該指標擷取即將不再是目前的編譯器。
static void initCompiler(Compiler* compiler, FunctionType type) {
在 initCompiler() 中
compiler->enclosing = current;
compiler->function = NULL;
然後,當編譯器完成時,它會將自己從堆疊中彈出,方法是將先前的編譯器恢復為新的當前編譯器。
#endif
在 endCompiler() 中
current = current->enclosing;
return function;
請注意,我們甚至不需要動態分配編譯器結構。每個結構都以 C 堆疊中的區域變數形式儲存—無論是在 compile() 或 function() 中。編譯器的連結串列穿梭於 C 堆疊。我們可以擁有無限數量的編譯器,原因在於我們的編譯器使用遞迴下降,因此當您有巢狀函式宣告時,function() 最終會遞迴呼叫自身。
24 . 4 . 2函式參數
如果無法將引數傳遞給函式,函式就不是很有用,因此接下來讓我們處理參數。
consume(TOKEN_LEFT_PAREN, "Expect '(' after function name.");
在 function() 中
if (!check(TOKEN_RIGHT_PAREN)) { do { current->function->arity++; if (current->function->arity > 255) { errorAtCurrent("Can't have more than 255 parameters."); } uint8_t constant = parseVariable("Expect parameter name."); defineVariable(constant); } while (match(TOKEN_COMMA)); }
consume(TOKEN_RIGHT_PAREN, "Expect ')' after parameters.");
在語意上,參數只是在函式主體最外層詞彙範圍中宣告的區域變數。我們可以使用現有的編譯器支援來宣告具名的區域變數,以便剖析和編譯參數。與具有初始設定式的區域變數不同,這裡沒有程式碼初始化參數的值。稍後,當我們在函式呼叫中進行引數傳遞時,我們將會看到它們如何被初始化。
在我們進行的同時,我們透過計算剖析的參數數量來記錄函式的元數。我們與函式一起儲存的另一個中繼資料是其名稱。在編譯函式宣告時,我們會在剖析函式名稱後立即呼叫 initCompiler()。這表示我們可以立即從先前的語彙單元取得名稱。
current = compiler;
在 initCompiler() 中
if (type != TYPE_SCRIPT) { current->function->name = copyString(parser.previous.start, parser.previous.length); }
Local* local = ¤t->locals[current->localCount++];
請注意,我們會仔細建立名稱字串的複本。請記住,語素直接指向原始原始碼字串。一旦程式碼完成編譯,該字串可能會被釋放。我們在編譯器中建立的函式物件比編譯器更長久,並且會持續到執行階段。因此,它需要自己的堆積配置名稱字串,以便可以保留。
太棒了。現在我們可以編譯函式宣告,像這樣
fun areWeHavingItYet() { print "Yes we are!"; } print areWeHavingItYet;
我們只是無法用它們做任何有用的事。
24 . 5函式呼叫
在本節結束時,我們將開始看到一些有趣的行為。下一步是呼叫函式。我們通常不會這樣想,但函式呼叫運算式有點像是中綴的 ( 運算子。左側有一個高優先順序的運算式,代表被呼叫的物件—通常只是一個單一的識別碼。然後是中間的 (,接著是以逗號分隔的引數運算式,最後是結尾的 ) 包裹。
這種奇特的語法觀點解釋了如何將語法掛鉤到我們的剖析表中。
ParseRule rules[] = {
在 unary() 之後新增
取代 1 行
[TOKEN_LEFT_PAREN] = {grouping, call, PREC_CALL},
[TOKEN_RIGHT_PAREN] = {NULL, NULL, PREC_NONE},
當剖析器遇到運算式後面的左括號時,它會分派到新的剖析器函式。
在 binary() 之後新增
static void call(bool canAssign) { uint8_t argCount = argumentList(); emitBytes(OP_CALL, argCount); }
我們已經消耗了 ( 語彙單元,因此接下來我們使用獨立的 argumentList() 輔助函式來編譯引數。該函式會傳回它編譯的引數數量。每個引數運算式都會產生程式碼,將其值留在堆疊上,以準備進行呼叫。之後,我們會發出新的 OP_CALL 指令來叫用函式,並使用引數計數作為運算元。
我們使用這個朋友編譯引數
在 defineVariable() 之後新增
static uint8_t argumentList() { uint8_t argCount = 0; if (!check(TOKEN_RIGHT_PAREN)) { do { expression(); argCount++; } while (match(TOKEN_COMMA)); } consume(TOKEN_RIGHT_PAREN, "Expect ')' after arguments."); return argCount; }
從 jlox 來看,該程式碼應該很熟悉。只要我們在每個運算式後找到逗號,就會逐一讀取引數。一旦用完,我們就會消耗最後的右括號,然後就完成了。
嗯,幾乎是。回到 jlox,我們新增了一個編譯時期檢查,以確保您傳遞給呼叫的引數不超過 255 個。當時,我說那是因為 clox 也需要類似的限制。現在您可以看到原因—由於我們將引數計數塞入位元組碼作為單一位元組運算元,因此我們最多只能到 255 個。我們也需要在這個編譯器中驗證這一點。
expression();
在 argumentList() 中
if (argCount == 255) { error("Can't have more than 255 arguments."); }
argCount++;
那是前端。讓我們跳到後端,並在中間快速停下來宣告新的指令。
OP_LOOP,
在 enum OpCode 中
OP_CALL,
OP_RETURN,
24 . 5 . 1將引數繫結至參數
在開始實作之前,我們應該先思考呼叫點的堆疊外觀,以及我們需要從那裡做什麼。當我們到達呼叫指令時,我們已經執行了被呼叫函式的運算式,然後是它的引數。假設我們的程式看起來像這樣
fun sum(a, b, c) { return a + b + c; } print 4 + sum(5, 6, 7);
如果我們在對 sum() 的呼叫的 OP_CALL 指令上暫停 VM,則堆疊看起來會像這樣

從 sum() 本身的角度來看這個情況。當編譯器編譯 sum() 時,它會自動配置位置零。然後,在那之後,它會依序為參數 a、b 和 c 配置區域位置。若要執行對 sum() 的呼叫,我們需要一個以被呼叫函式和可用堆疊位置區域初始化的 CallFrame。然後,我們需要收集傳遞給函式的引數,並將它們放入對應的參數位置。
當 VM 開始執行 sum() 的主體時,我們希望它的堆疊視窗看起來像這樣
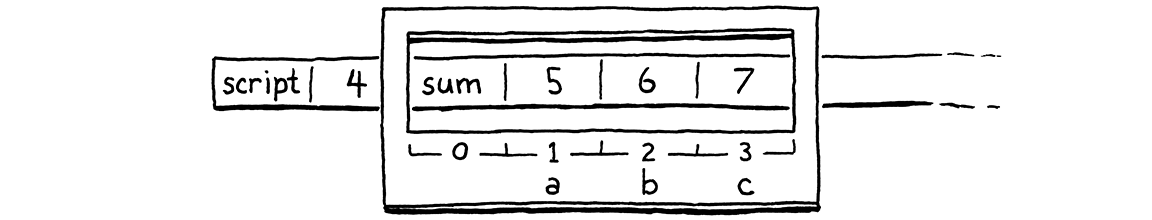
您是否注意到呼叫者設定的引數位置和被呼叫者需要的參數位置都正好是正確的順序?真是太方便了!這並非巧合。當我談到每個 CallFrame 都有自己的堆疊視窗時,我從未說過那些視窗必須是不相交的。沒有任何東西可以阻止我們將它們重疊,像這樣
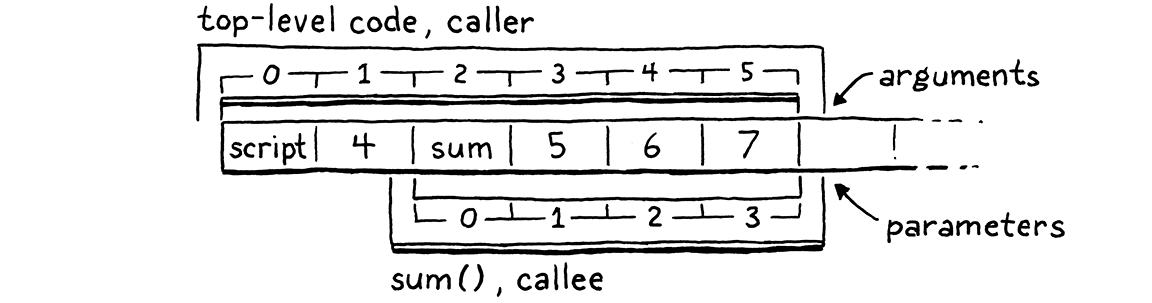
呼叫者堆疊的頂端包含被呼叫的函式,後接依序排列的引數。我們知道呼叫者在那些引數之上沒有任何其他正在使用的位置,因為在評估引數運算式時所需的任何暫存變數現在都已被捨棄。被呼叫者堆疊的底部會重疊,以便參數位置與引數值已經存在的位置完全對齊。
這表示我們不需要做任何工作來「將引數繫結至參數」。不需要在位置之間或跨環境複製值。引數已經在它們需要的位置。很難在效能方面超越這一點。
是時候實作呼叫指令了。
}
在 run() 中
case OP_CALL: { int argCount = READ_BYTE(); if (!callValue(peek(argCount), argCount)) { return INTERPRET_RUNTIME_ERROR; } break; }
case OP_RETURN: {
我們需要知道被呼叫的函式和傳遞給它的引數數量。我們從指令的運算元取得後者。這也告訴我們要在堆疊上哪裡找到函式,方法是從堆疊頂端數過引數位置。我們會將該資料傳遞給獨立的 callValue() 函式。如果它傳回 false,則表示呼叫導致某種執行階段錯誤。當發生這種情況時,我們會中止解譯器。
如果 callValue() 成功,則在被呼叫函式的 CallFrame 堆疊上會有一個新的框架。run() 函式有自己快取的目前框架指標,因此我們需要更新它。
return INTERPRET_RUNTIME_ERROR;
}
在 run() 中
frame = &vm.frames[vm.frameCount - 1];
break;
由於位元組碼分派迴圈是從該 frame 變數讀取,因此當 VM 執行下一個指令時,它會從新呼叫的函式的 CallFrame 讀取 ip 並跳轉到其程式碼。執行該呼叫的工作從這裡開始
在 peek() 之後新增
static bool callValue(Value callee, int argCount) { if (IS_OBJ(callee)) { switch (OBJ_TYPE(callee)) { case OBJ_FUNCTION: return call(AS_FUNCTION(callee), argCount); default: break; // Non-callable object type. } } runtimeError("Can only call functions and classes."); return false; }
這裡不僅僅是初始化新的 CallFrame。由於 Lox 是動態型別的,因此沒有任何東西可以阻止使用者撰寫錯誤的程式碼,例如
var notAFunction = 123; notAFunction();
如果發生這種情況,執行階段需要安全地報告錯誤並停止。因此,我們要做的第一件事是檢查我們要呼叫的值的類型。如果它不是函式,我們會發生錯誤。否則,實際的呼叫會在這裡發生
在 peek() 之後新增
static bool call(ObjFunction* function, int argCount) { CallFrame* frame = &vm.frames[vm.frameCount++]; frame->function = function; frame->ip = function->chunk.code; frame->slots = vm.stackTop - argCount - 1; return true; }
這只是初始化堆疊上的下一個 CallFrame。它會儲存指向被呼叫函式的指標,並將框架的 ip 指向函式位元組碼的開頭。最後,它會設定 slots 指標,以便為框架提供堆疊的視窗。那裡的算術運算可確保堆疊上已有的引數與函式的參數對齊
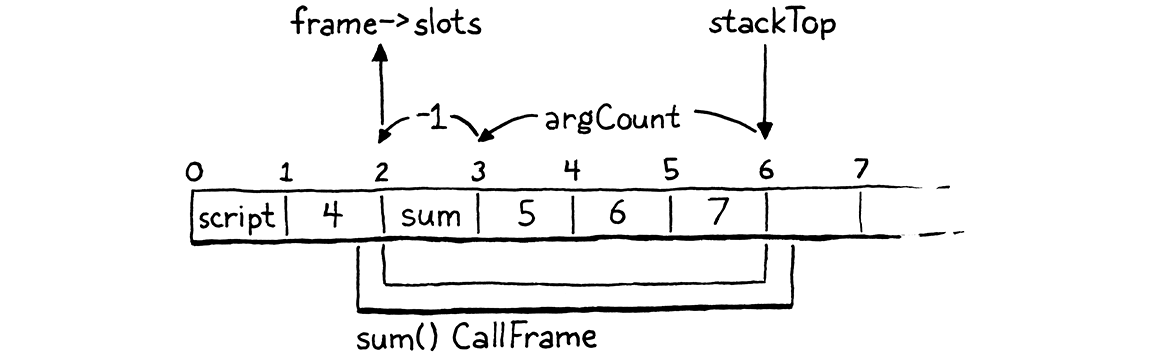
有趣的 - 1 是為了說明堆疊位置零,編譯器會在稍後新增方法時預留該位置。參數從位置一開始,因此我們讓視窗提前一個位置開始,以使其與引數對齊。
在我們繼續之前,讓我們將新的指令新增至我們的反組譯器。
return jumpInstruction("OP_LOOP", -1, chunk, offset);
在 disassembleInstruction() 中
case OP_CALL: return byteInstruction("OP_CALL", chunk, offset);
case OP_RETURN:
還有一次快速的短途旅行。既然我們有一個方便的函式可以初始化 CallFrame,我們不妨也使用它來設定執行最上層程式碼的第一個框架。
push(OBJ_VAL(function));
在 interpret() 中
取代 4 行
call(function, 0);
return run();
好,現在回到呼叫 . . .
24 . 5 . 2執行階段錯誤檢查
重疊的堆疊視窗根據以下假設運作:一個呼叫會為每個函式的參數傳遞正好一個引數。但是,再次強調,由於 Lox 並非靜態型別,因此愚蠢的使用者可能會傳遞太多或太少的引數。在 Lox 中,我們將其定義為執行階段錯誤,我們會像這樣報告
static bool call(ObjFunction* function, int argCount) {
在 call() 中
if (argCount != function->arity) { runtimeError("Expected %d arguments but got %d.", function->arity, argCount); return false; }
CallFrame* frame = &vm.frames[vm.frameCount++];
非常簡單。這就是為什麼我們將每個函式的元數儲存在其 ObjFunction 內的原因。
我們需要報告另一個錯誤,該錯誤與使用者本身的愚蠢行為無關,而是與我們自身有關。由於 CallFrame 陣列具有固定大小,因此我們需要確保深度呼叫鏈不會溢位。
}
在 call() 中
if (vm.frameCount == FRAMES_MAX) { runtimeError("Stack overflow."); return false; }
CallFrame* frame = &vm.frames[vm.frameCount++];
實際上,如果程式碼接近這個限制,很可能在某些失控的遞迴程式碼中存在錯誤。
24 . 5 . 3印出堆疊追蹤
既然我們在討論執行階段錯誤,不如花點時間讓它們更有用。在執行階段錯誤時停止是很重要的,這樣可以防止虛擬機器以不明確的方式崩潰。但是,單純中止並不能幫助使用者修復導致錯誤的程式碼。
輔助除錯執行階段錯誤的經典工具是堆疊追蹤—印出程式碼終止時仍在執行的每個函式,以及終止時的執行位置。現在我們有了呼叫堆疊,而且方便地儲存了每個函式的名稱,我們可以在執行階段錯誤擾亂使用者生活和諧時顯示整個堆疊。它看起來像這樣:
fputs("\n", stderr);
在 runtimeError() 中
取代 4 行
for (int i = vm.frameCount - 1; i >= 0; i--) { CallFrame* frame = &vm.frames[i]; ObjFunction* function = frame->function; size_t instruction = frame->ip - function->chunk.code - 1; fprintf(stderr, "[line %d] in ", function->chunk.lines[instruction]); if (function->name == NULL) { fprintf(stderr, "script\n"); } else { fprintf(stderr, "%s()\n", function->name->chars); } }
resetStack(); }
在印出錯誤訊息本身之後,我們從頂端(最近呼叫的函式)到底部(頂層程式碼)遍歷呼叫堆疊。對於每個 frame,我們找出該 frame 的函式中對應於目前 ip 的行號。然後,我們印出該行號以及函式名稱。
例如,如果你執行這個損壞的程式碼:
fun a() { b(); } fun b() { c(); } fun c() { c("too", "many"); } a();
它會印出:
Expected 0 arguments but got 2. [line 4] in c() [line 2] in b() [line 1] in a() [line 7] in script
看起來還不錯,對吧?
24 . 5 . 4從函式返回
我們快完成了。我們可以呼叫函式,而虛擬機器會執行它們。但是我們還不能從它們返回。我們已經有 OP_RETURN 指令很長一段時間了,但它總是有一些臨時程式碼掛在其中,只是為了讓我們脫離位元組碼迴圈。是時候進行真正的實作了。
case OP_RETURN: {
在 run() 中
取代 2 行
Value result = pop(); vm.frameCount--; if (vm.frameCount == 0) { pop(); return INTERPRET_OK; } vm.stackTop = frame->slots; push(result); frame = &vm.frames[vm.frameCount - 1]; break;
}
當函式傳回一個值時,該值將位於堆疊頂端。我們即將捨棄被呼叫函式的整個堆疊視窗,因此我們將該傳回值彈出並保留它。然後,我們捨棄返回函式的 CallFrame。如果那是最後一個 CallFrame,則表示我們已完成執行頂層程式碼。整個程式已完成,因此我們從堆疊中彈出主腳本函式,然後退出直譯器。
否則,我們將捨棄被呼叫者用於其參數和區域變數的所有 slot。這包括呼叫者用於傳遞引數的相同 slot。現在呼叫已完成,呼叫者不再需要它們。這表示堆疊頂端最終會位於返回函式的堆疊視窗的開頭。
我們將傳回值推回堆疊中的新較低位置。然後,我們更新 run() 函式的快取指標以指向目前的 frame。就像我們開始呼叫時一樣,在位元組碼分派迴圈的下一次迭代中,虛擬機器會從該 frame 讀取 ip,並且執行將跳回呼叫者,就在它停止的位置,緊接在 OP_CALL 指令之後。
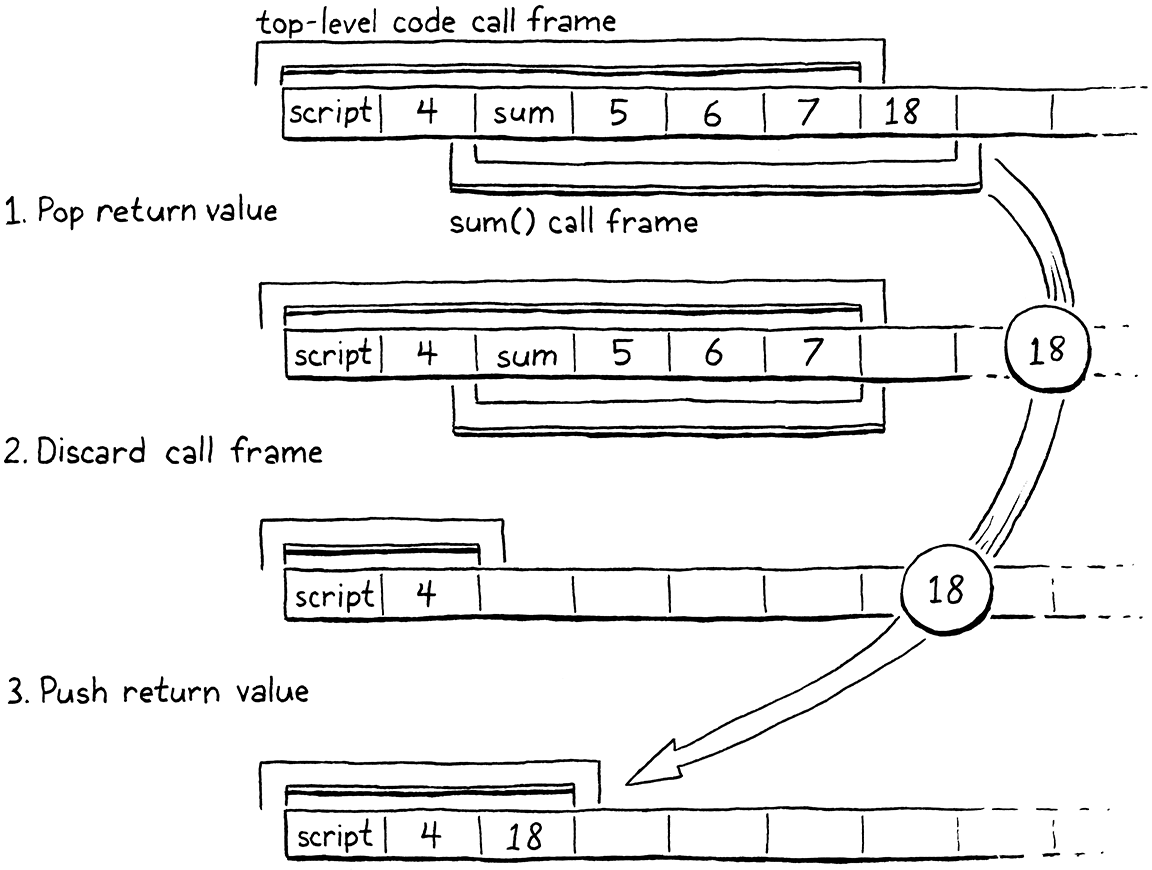
請注意,我們在這裡假設函式確實傳回了一個值,但是函式可以透過到達其主體的末尾來隱式傳回。
fun noReturn() { print "Do stuff"; // No return here. } print noReturn(); // ???
我們也需要正確處理這種情況。該語言指定在這種情況下會隱式傳回 nil。為了實現這一點,我們新增以下內容:
static void emitReturn() {
在 emitReturn() 中
emitByte(OP_NIL);
emitByte(OP_RETURN); }
編譯器呼叫 emitReturn() 以在函式主體的末尾寫入 OP_RETURN 指令。現在,在此之前,它會發出一個指令,將 nil 推入堆疊。這樣一來,我們就有了可用的函式呼叫!它們甚至可以接受參數!看起來我們好像知道自己在做什麼了。
24 . 6返回陳述式
如果你想要一個傳回非隱式 nil 的函式,你需要一個 return 陳述式。讓我們讓它運作起來。
ifStatement();
在 statement() 中
} else if (match(TOKEN_RETURN)) { returnStatement();
} else if (match(TOKEN_WHILE)) {
當編譯器看到 return 關鍵字時,它會來到這裡:
在 printStatement() 之後新增
static void returnStatement() { if (match(TOKEN_SEMICOLON)) { emitReturn(); } else { expression(); consume(TOKEN_SEMICOLON, "Expect ';' after return value."); emitByte(OP_RETURN); } }
傳回值運算式是可選的,因此剖析器會尋找分號 token 以判斷是否提供了值。如果沒有傳回值,則陳述式會隱式傳回 nil。我們透過呼叫 emitReturn() 來實作這一點,它會發出 OP_NIL 指令。否則,我們會編譯傳回值運算式,並使用 OP_RETURN 指令傳回它。
這與我們已經實作的 OP_RETURN 指令相同—我們不需要任何新的執行階段程式碼。這與 jlox 有很大的不同。在那裡,當執行 return 陳述式時,我們必須使用例外來展開堆疊。這是因為你可以從某些巢狀區塊的深處返回。由於 jlox 遞迴地遍歷 AST,這表示我們需要從一堆 Java 方法呼叫中脫離。
我們的位元組碼編譯器會將所有這些都扁平化。我們在剖析期間進行遞迴下降,但在執行階段,虛擬機器的位元組碼分派迴圈完全是扁平的。在 C 層面上根本沒有進行遞迴。因此,即使從某些巢狀區塊中返回,也和從函式主體的末尾返回一樣簡單。
不過,我們還沒有完全完成。新的 return 陳述式給了我們一個新的編譯錯誤要擔心。返回對於從函式返回很有用,但 Lox 程式的頂層也是命令式程式碼。你不應該能夠從那裡返回。
return "What?!";
我們已指定在任何函式之外都有 return 陳述式是一種編譯錯誤,我們實作如下:
static void returnStatement() {
在 returnStatement() 中
if (current->type == TYPE_SCRIPT) { error("Can't return from top-level code."); }
if (match(TOKEN_SEMICOLON)) {
這是我們將 FunctionType 列舉新增到編譯器的原因之一。
24 . 7原生函式
我們的虛擬機器變得越來越強大。我們有了函式、呼叫、參數、返回。你可以定義許多不同的函式,它們可以以有趣的方式互相呼叫。但是,歸根究底,它們實際上不能做任何事情。Lox 程式可以做的唯一使用者可見的事情,無論其複雜性如何,都是列印。為了新增更多功能,我們需要將它們公開給使用者。
程式語言實作透過原生函式來接觸物質世界。如果你希望能夠編寫檢查時間、讀取使用者輸入或存取檔案系統的程式碼,我們需要新增原生函式—可以從 Lox 呼叫,但在 C 中實作—這些函式會公開這些功能。
在語言層面,Lox 相當完整—它具有閉包、類別、繼承和其他有趣的東西。它感覺像一種玩具語言的原因之一是因為它幾乎沒有原生功能。我們可以透過新增一長串原生功能將其變成真正的語言。
但是,艱難地處理一堆作業系統操作實際上沒有什麼教育意義。一旦你看到如何將一段 C 程式碼繫結到 Lox,你就明白了。但是你確實需要看到一個,甚至單一的原生函式也需要我們建立所有將 Lox 與 C 連接的機制。因此,我們將仔細研究並完成所有繁重的工作。然後,完成後,我們將新增一個微小的原生函式,只是為了證明它可以運作。
我們需要新機器的原因是,從實作的角度來看,原生函式與 Lox 函式不同。呼叫它們時,它們不會推送 CallFrame,因為沒有 bytecode 程式碼可以讓該 frame 指向。它們沒有 bytecode 區塊。相反地,它們會以某種方式引用一段原生 C 程式碼。
我們在 clox 中透過將原生函式定義為完全不同的物件類型來處理這個問題。
} ObjFunction;
在 struct ObjFunction 之後新增
typedef Value (*NativeFn)(int argCount, Value* args); typedef struct { Obj obj; NativeFn function; } ObjNative;
struct ObjString {
表示比 ObjFunction 更簡單—僅僅是一個 Obj 標頭和一個指向實作原生行為的 C 函式的指標。原生函式會取得引數計數和一個指向堆疊中第一個引數的指標。它透過該指標存取引數。完成後,它會傳回結果值。
與往常一樣,新的物件類型會帶有一些附加物。若要建立 ObjNative,我們宣告一個類似建構函式的函式。
ObjFunction* newFunction();
在 newFunction() 之後新增
ObjNative* newNative(NativeFn function);
ObjString* takeString(char* chars, int length);
我們實作如下:
在 newFunction() 之後新增
ObjNative* newNative(NativeFn function) { ObjNative* native = ALLOCATE_OBJ(ObjNative, OBJ_NATIVE); native->function = function; return native; }
建構函式會取得要包裝在 ObjNative 中的 C 函式指標。它會設定物件標頭並儲存函式。對於標頭,我們需要一個新的物件類型。
typedef enum {
OBJ_FUNCTION,
在 enum ObjType 中
OBJ_NATIVE,
OBJ_STRING, } ObjType;
虛擬機器還需要知道如何釋放原生函式物件。
}
在 freeObject() 中
case OBJ_NATIVE: FREE(ObjNative, object); break;
case OBJ_STRING: {
這裡沒有太多內容,因為 ObjNative 沒有擁有任何額外的記憶體。所有 Lox 物件支援的其他功能是列印。
break;
在 printObject() 中
case OBJ_NATIVE: printf("<native fn>"); break;
case OBJ_STRING:
為了支援動態類型,我們有一個巨集來判斷值是否為原生函式。
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
#define IS_NATIVE(value) isObjType(value, OBJ_NATIVE)
#define IS_STRING(value) isObjType(value, OBJ_STRING)
假設回傳值為真,此巨集會從代表原生函式的 Value 中提取 C 函式指標。
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
#define AS_NATIVE(value) \ (((ObjNative*)AS_OBJ(value))->function)
#define AS_STRING(value) ((ObjString*)AS_OBJ(value))
所有這些額外的處理讓虛擬機器能像處理其他物件一樣處理原生函式。您可以將它們儲存在變數中、傳遞它們、為它們舉辦生日派對等等。當然,我們真正關心的操作是呼叫它們—將它們用作呼叫運算式中的左運算元。
在 callValue() 中,我們新增另一個類型的情況。
case OBJ_FUNCTION:
return call(AS_FUNCTION(callee), argCount);
在 callValue() 中
case OBJ_NATIVE: { NativeFn native = AS_NATIVE(callee); Value result = native(argCount, vm.stackTop - argCount); vm.stackTop -= argCount + 1; push(result); return true; }
default:
如果被呼叫的物件是原生函式,我們會立即調用 C 函式。不需要處理 CallFrames 或其他任何事情。我們直接將控制權交給 C,取得結果,然後將其放回堆疊中。這使得原生函式盡可能地快速執行。
有了這個,使用者應該能夠呼叫原生函式,但目前還沒有任何原生函式可以呼叫。如果沒有像外部函式介面之類的東西,使用者就無法定義自己的原生函式。這是我們作為虛擬機器實作者的工作。我們先從一個輔助函式開始,用於定義一個公開給 Lox 程式的新原生函式。
在 runtimeError() 之後新增
static void defineNative(const char* name, NativeFn function) { push(OBJ_VAL(copyString(name, (int)strlen(name)))); push(OBJ_VAL(newNative(function))); tableSet(&vm.globals, AS_STRING(vm.stack[0]), vm.stack[1]); pop(); pop(); }
它接收一個指向 C 函式的指標,以及它在 Lox 中將被稱作的名稱。我們將函式包裝在一個 ObjNative 中,然後將其儲存在一個具有給定名稱的全域變數中。
您可能想知道為什麼我們要在堆疊上推入和彈出名稱和函式。這看起來很奇怪,對吧?當垃圾收集器參與時,您就必須擔心這類事情。copyString() 和 newNative() 都會動態分配記憶體。這意味著一旦我們有了垃圾收集器,它們可能會觸發收集。如果發生這種情況,我們需要確保收集器知道我們還沒用完名稱和 ObjFunction,以免它從我們這裡釋放它們。將它們儲存在值堆疊上可以達成此目的。
感覺有點傻,但經過所有這些工作之後,我們只會新增一個小小的原生函式。
在變數 vm 之後新增
static Value clockNative(int argCount, Value* args) { return NUMBER_VAL((double)clock() / CLOCKS_PER_SEC); }
這會回傳程式開始執行後經過的時間,以秒為單位。這對於基準測試 Lox 程式很有用。在 Lox 中,我們將其命名為 clock()。
initTable(&vm.strings);
在 initVM() 中
defineNative("clock", clockNative);
}
要取得 C 標準程式庫的 clock() 函式,「vm」模組需要一個 include。
#include <string.h>
#include <time.h>
#include "common.h"
這有很多材料需要處理,但我們完成了!輸入這些並試試看
fun fib(n) { if (n < 2) return n; return fib(n - 2) + fib(n - 1); } var start = clock(); print fib(35); print clock() - start;
我們可以編寫一個效率非常低的遞迴費波那契函式。更好的是,我們可以測量它有多低效。當然,這不是計算費波那契數的最聰明的方法。但它是測試語言實作對函式呼叫支援的好方法。在我的機器上,在 clox 中執行此程式碼比在 jlox 中快大約五倍。這是一個相當大的進步。
挑戰
-
讀取和寫入
ip欄位是位元組碼迴圈中最頻繁的操作之一。目前,我們是透過指向目前 CallFrame 的指標來存取它。這需要一個指標間接存取,這可能會迫使 CPU 繞過快取並存取主記憶體。這可能會是一個真正的效能瓶頸。理想情況下,我們會將
ip保存在原生 CPU 暫存器中。C 不允許我們在不直接進入內聯組語的情況下要求這樣做,但我們可以建構程式碼以鼓勵編譯器進行這種優化。如果我們將ip直接儲存在 C 本機變數中,並將其標記為register,則 C 編譯器很有可能會接受我們的禮貌請求。這確實意味著我們在開始和結束函式呼叫時,需要小心地將本機
ip載入並儲存回正確的 CallFrame。實作此優化。編寫一些基準測試,看看它如何影響效能。您認為額外的程式碼複雜性值得嗎? -
原生函式呼叫速度快的原因之一是我們沒有驗證呼叫傳遞的參數是否與函式預期的參數一樣多。我們真的應該這樣做,否則對沒有足夠參數的原生函式進行不正確的呼叫可能會導致函式讀取未初始化的記憶體。新增參數檢查。
-
目前,原生函式沒有辦法發出執行階段錯誤訊號。在實際的實作中,這是我們需要支援的,因為原生函式存在於 C 的靜態類型世界中,但會從動態類型的 Lox 領域中呼叫。如果使用者嘗試將字串傳遞給
sqrt(),則該原生函式需要報告執行階段錯誤。擴充原生函式系統以支援此功能。這種能力如何影響原生呼叫的效能?
-
新增一些您覺得有用的原生函式。使用這些函式編寫一些程式。您新增了什麼?它們如何影響語言的感覺以及它的實用性?