區域變數
當想像力形塑出
未知事物的樣貌,詩人的筆
將它們轉化為形體,並賦予虛無飄渺之物
一個棲身之所和一個名字。威廉·莎士比亞,《仲夏夜之夢》
上一章為 clox 引入了變數,但僅限於全域變數。在這一章中,我們將擴展它以支援區塊、區塊作用域和區域變數。在 jlox 中,我們設法將所有這些和全域變數都打包到一章中。對於 clox 來說,這相當於兩章的工作量,部分原因坦白說,在 C 語言中一切都需要更多精力。
但更重要的原因是,我們處理區域變數的方法與我們實作全域變數的方式截然不同。全域變數在 Lox 中是後期綁定的。這裡的「後期」是指「在編譯時之後解析」。這有利於保持編譯器簡單,但不利於效能。區域變數是語言中最常用的部分之一。如果區域變數速度慢,一切都會很慢。因此,我們需要一個盡可能高效的區域變數策略。
幸運的是,詞法作用域可以幫助我們。顧名思義,詞法作用域意味著我們只需查看程式的文本即可解析區域變數—區域變數不是後期綁定的。我們在編譯器中做的任何處理工作都是我們在執行階段不必做的工作,因此我們對區域變數的實作將非常依賴編譯器。
22 . 1表示區域變數
在現代編寫程式語言的好處是,有很多其他語言可以學習。那麼 C 和 Java 如何管理它們的區域變數呢?當然是在堆疊上!它們通常使用晶片和作業系統支援的本機堆疊機制。這對我們來說有點太底層了,但在 clox 的虛擬世界中,我們有自己的堆疊可以使用。
現在,我們只使用它來保存暫存變數—我們在計算表達式時需要記住的短暫資料區塊。只要不干擾這些,我們也可以將區域變數放入堆疊中。這對效能來說很棒。為新的區域變數分配空間只需要增加 stackTop 指標,而釋放空間也同樣是減少。從已知的堆疊插槽存取變數是陣列的索引查找。
不過,我們需要小心。VM 期望堆疊的行為像一個堆疊。我們必須接受只能在堆疊頂部分配新的區域變數,而且我們必須接受只有在堆疊上沒有其他內容時才能丟棄區域變數。此外,我們需要確保暫存變數不會相互干擾。
方便的是,Lox 的設計與這些約束和諧一致。新的區域變數總是透過宣告陳述式來建立。陳述式不會嵌套在表達式中,因此在陳述式開始執行時,堆疊上永遠不會有任何暫存變數。區塊是嚴格嵌套的。當區塊結束時,它總是會帶走最內層、最近宣告的區域變數。由於這些也是最後進入作用域的區域變數,因此它們應該在我們需要的堆疊頂部。
逐步執行此範例程式,並觀察區域變數如何進入和離開作用域
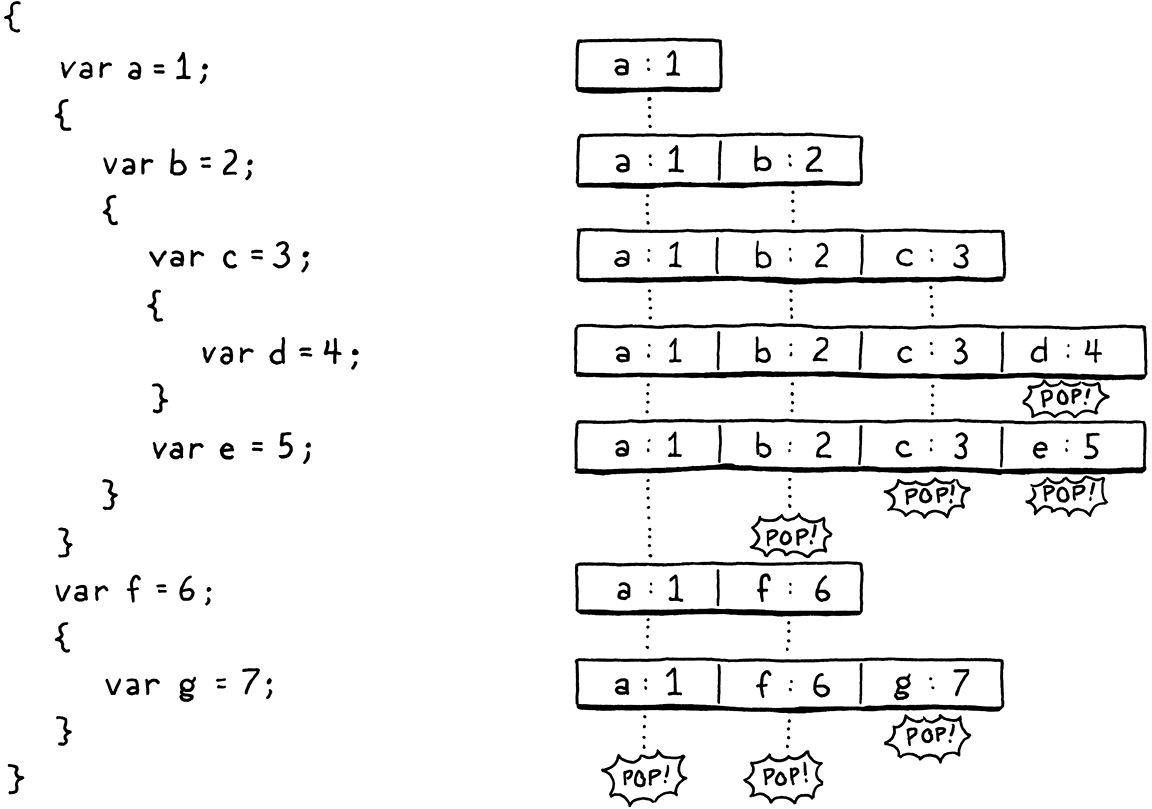
它們如何完美地適合堆疊?看來堆疊適合在執行階段儲存區域變數。但我們可以更進一步。我們不僅知道它們會在堆疊上,而且我們甚至可以準確地確定它們在堆疊上的位置。由於編譯器確切知道在任何時間點哪些區域變數在作用域內,因此它可以有效地在編譯期間模擬堆疊,並記錄每個變數在堆疊中的位置。
我們將利用這一點,將這些堆疊偏移量用作讀取和儲存區域變數的位元組碼指令的運算元。這使得處理區域變數變得非常快速—就像索引到陣列一樣簡單。
我們需要在編譯器中追蹤很多狀態才能使整個過程順利進行,因此讓我們從那裡開始。在 jlox 中,我們使用「環境」HashMap 的連結鏈來追蹤目前在作用域中的區域變數。這有點像是表示詞法作用域的經典教科書方法。對於 clox,像往常一樣,我們會更接近底層。所有狀態都存在於一個新的結構中。
} ParseRule;
在 struct ParseRule 之後新增
typedef struct { Local locals[UINT8_COUNT]; int localCount; int scopeDepth; } Compiler;
Parser parser;
我們有一個簡單的扁平陣列,其中包含編譯過程中每個點作用域內的所有區域變數。它們在陣列中按宣告出現在程式碼中的順序排序。由於我們將用來編碼區域變數的指令運算元是一個位元組,因此我們的 VM 對一次作用域內可以存在的區域變數數量有硬性限制。這表示我們也可以為區域變數陣列提供固定大小。
#define DEBUG_TRACE_EXECUTION
#define UINT8_COUNT (UINT8_MAX + 1)
#endif
回到 Compiler 結構中,localCount 欄位追蹤作用域內的區域變數數量—使用了多少個陣列插槽。我們還追蹤「作用域深度」。這是包圍我們正在編譯的目前程式碼區塊的區塊數量。
我們的 Java 直譯器使用映射鏈來將每個區塊的變數與其他區塊分開。這次,我們將簡單地使用它們出現的嵌套層級來編號變數。零是全域作用域,一是最頂層的區塊,二是內部區塊,你懂的。我們使用這個來追蹤每個區域變數屬於哪個區塊,以便我們知道在區塊結束時要丟棄哪些區域變數。
陣列中的每個區域變數都是其中之一
} ParseRule;
在 struct ParseRule 之後新增
typedef struct { Token name; int depth; } Local;
typedef struct {
我們儲存變數的名稱。當我們解析識別項時,我們會將識別項的語素與每個區域變數的名稱進行比較以找到匹配項。如果你不知道變數的名稱,就很難解析變數。depth 欄位記錄宣告區域變數的區塊的作用域深度。這就是我們現在需要的所有狀態。
這與我們在 jlox 中的表示形式非常不同,但它仍然允許我們回答編譯器需要向詞法環境提出的所有相同問題。下一步是弄清楚編譯器如何取得此狀態。如果我們是有原則的工程師,我們會為前端的每個函式提供一個接受 Compiler 指標的參數。我們會在開始時建立一個 Compiler,並仔細地將它傳遞到每個函式呼叫中 . . . ,但這表示我們必須對我們已經編寫的程式碼進行許多乏味的變更,因此這裡改用全域變數
Parser parser;
在變數 parser 之後新增
Compiler* current = NULL;
Chunk* compilingChunk;
這裡有一個小函式來初始化編譯器
在 emitConstant() 之後新增
static void initCompiler(Compiler* compiler) { compiler->localCount = 0; compiler->scopeDepth = 0; current = compiler; }
當我們第一次啟動 VM 時,我們會呼叫它來使一切恢復到乾淨狀態。
initScanner(source);
在 compile() 中
Compiler compiler; initCompiler(&compiler);
compilingChunk = chunk;
我們的編譯器具有它需要的資料,但沒有對該資料的操作。無法建立和銷毀作用域,或新增和解析變數。我們將在需要它們時新增它們。首先,讓我們開始建構一些語言功能。
22 . 2區塊陳述式
在我們擁有任何區域變數之前,我們需要一些區域作用域。這些來自兩個方面:函式主體和區塊。函式是我們將在稍後章節中處理的大量工作,因此現在我們只會處理區塊。像往常一樣,我們從語法開始。我們將引入的新語法是
statement → exprStmt | printStmt | block ; block → "{" declaration* "}" ;
區塊是一種陳述式,因此它們的規則會進入 statement 產生式。編譯一個區塊的對應程式碼如下所示
if (match(TOKEN_PRINT)) {
printStatement();
在 statement() 中
} else if (match(TOKEN_LEFT_BRACE)) { beginScope(); block(); endScope();
} else {
在剖析初始大括號之後,我們使用此輔助函式來編譯區塊的其餘部分
在 expression() 之後新增
static void block() { while (!check(TOKEN_RIGHT_BRACE) && !check(TOKEN_EOF)) { declaration(); } consume(TOKEN_RIGHT_BRACE, "Expect '}' after block."); }
它會持續解析宣告和陳述式,直到遇到右大括號為止。如同我們在解析器中處理任何迴圈一樣,我們也會檢查符號串流的結尾。這樣一來,如果程式碼格式不正確,缺少右大括號,編譯器就不會陷入迴圈中。
執行程式區塊僅表示依序執行它包含的陳述式,因此編譯它們沒有太多複雜之處。程式區塊在語義上有趣的行為是建立作用域。在編譯程式區塊的主體之前,我們會呼叫此函數以進入新的本機作用域。
在 endCompiler() 之後新增
static void beginScope() { current->scopeDepth++; }
為了「建立」作用域,我們所做的只是增加目前的深度。這肯定比 jlox 快得多,jlox 會為每個作用域分配一個全新的 HashMap。有了 beginScope(),您大概可以猜到 endScope() 的作用。
在 beginScope() 之後新增
static void endScope() { current->scopeDepth--; }
這就是程式區塊和作用域的全部內容—或多或少—所以我們準備好將一些變數放入其中。
22 . 3宣告區域變數
通常我們會從這裡開始解析,但我們的編譯器已經支援解析和編譯變數宣告。我們現在有了 var 陳述式、識別符號運算式和賦值。只是編譯器假設所有變數都是全域的。因此,我們不需要任何新的解析支援,我們只需要將新的作用域語義連結到現有的程式碼即可。
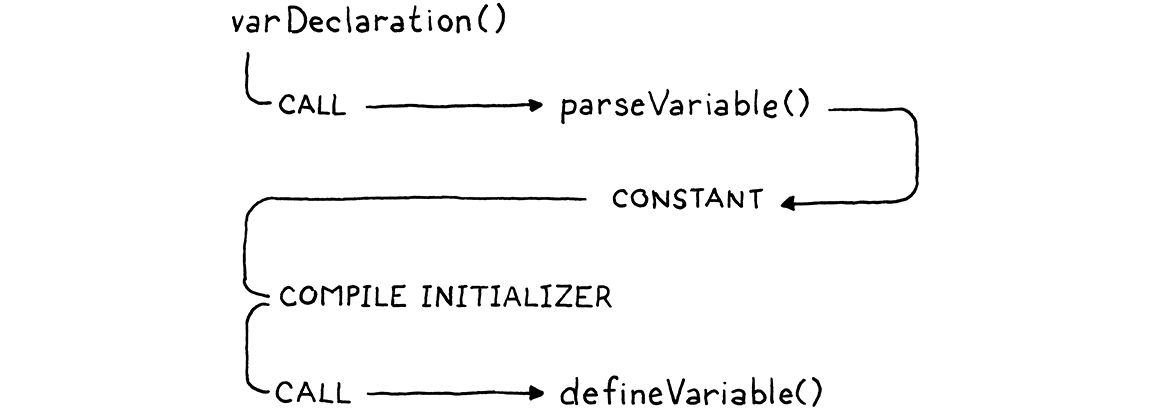
變數宣告解析始於 varDeclaration(),並依賴於其他幾個函數。首先,parseVariable() 會使用變數名稱的識別符號符號,將其詞素作為字串新增到程式碼區塊的常數表,然後傳回新增位置的常數表索引。然後,在 varDeclaration() 編譯初始值設定式之後,它會呼叫 defineVariable() 以發出將變數值儲存在全域變數雜湊表中的位元碼。
這兩個輔助函數都需要一些變更才能支援區域變數。在 parseVariable() 中,我們新增
consume(TOKEN_IDENTIFIER, errorMessage);
在 parseVariable() 中
declareVariable(); if (current->scopeDepth > 0) return 0;
return identifierConstant(&parser.previous);
首先,我們「宣告」變數。我稍後會說明這代表什麼。之後,如果我們在區域作用域中,則退出函數。在執行階段,不會依名稱查閱區域變數。不需要將變數名稱塞入常數表中,因此如果宣告位於區域作用域內,我們就傳回一個虛擬的表格索引作為替代。
在 defineVariable() 中,如果我們位於區域作用域中,我們需要發出程式碼以儲存區域變數。它看起來像這樣
static void defineVariable(uint8_t global) {
在 defineVariable() 中
if (current->scopeDepth > 0) { return; }
emitBytes(OP_DEFINE_GLOBAL, global);
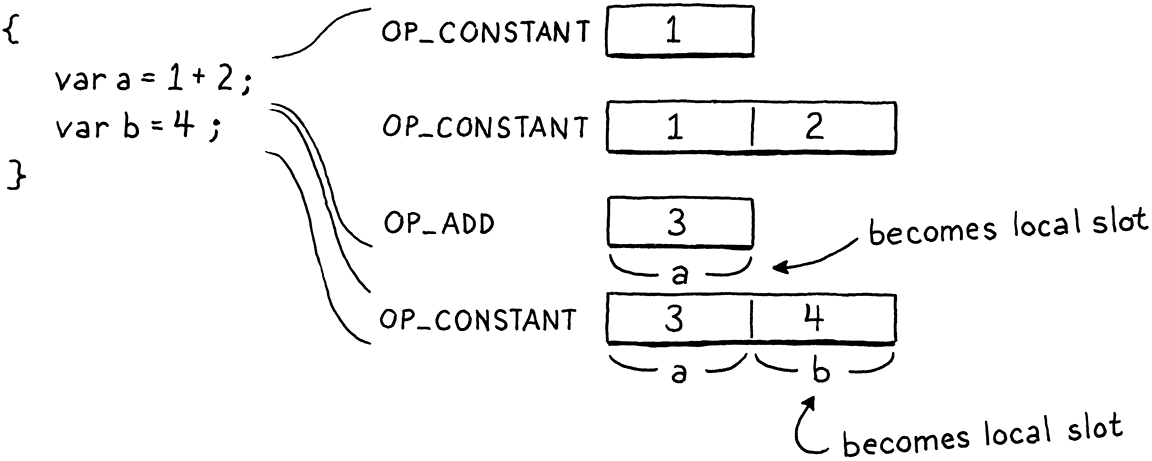
等等,什麼?沒錯。就這樣。沒有任何程式碼可以在執行階段建立區域變數。想想 VM 的狀態。它已經執行了變數初始值設定式的程式碼(如果使用者省略了初始值設定式,則為隱含的 nil),而且該值正以唯一剩餘的暫存值形式位於堆疊頂端。我們也知道新的區域變數會配置在堆疊頂端 . . .,而該值正好位於該位置。因此,沒有任何事情要做。暫存值直接變成區域變數。這效率極高。
好的,那麼「宣告」是什麼意思呢?以下是它的作用
在 identifierConstant() 之後新增
static void declareVariable() { if (current->scopeDepth == 0) return; Token* name = &parser.previous; addLocal(*name); }
這是編譯器記錄變數存在的位置。我們只會對區域變數執行此操作,因此如果我們位於最上層的全域作用域中,我們就會直接跳出。由於全域變數是延遲繫結的,編譯器不會追蹤它已看到的宣告。
但是對於區域變數,編譯器確實需要記住變數存在。這就是宣告的作用—它會將變數新增到編譯器目前作用域中的變數清單。我們使用另一個新的函數來實作這一點。
在 identifierConstant() 之後新增
static void addLocal(Token name) { Local* local = ¤t->locals[current->localCount++]; local->name = name; local->depth = current->scopeDepth; }
這會初始化編譯器變數陣列中的下一個可用 Local。它會儲存變數的 名稱和擁有該變數的作用域深度。
我們的實作對於正確的 Lox 程式沒有問題,但是對於無效的程式碼呢?我們的目標是穩健。要處理的第一個錯誤實際上不是使用者的錯,而是 VM 的限制。用於處理區域變數的指令會透過槽索引來參考它們。該索引儲存在單一位元組運算元中,這表示 VM 一次只支援最多 256 個區域變數。
如果我們嘗試超出此限制,我們不僅無法在執行階段參考它們,而且編譯器也會覆寫自己的區域變數陣列。讓我們防止這種情況發生。
static void addLocal(Token name) {
在 addLocal() 中
if (current->localCount == UINT8_COUNT) { error("Too many local variables in function."); return; }
Local* local = ¤t->locals[current->localCount++];
下一個案例比較棘手。考慮一下
{
var a = "first";
var a = "second";
}
在最上層,Lox 允許使用與先前宣告相同的名稱重新宣告變數,因為這對於 REPL 很有用。但是在區域作用域內,這是一個相當奇怪的事情。這很可能是個錯誤,而且許多語言(包括我們自己的 Lox)都將此假設奉為圭臬,將其視為錯誤。
請注意,上面的程式與此程式不同
{
var a = "outer";
{
var a = "inner";
}
}
在不同作用域中,即使作用域重疊且兩者同時可見,也可以有兩個名稱相同的變數。這稱為遮蔽,而 Lox 確實允許這樣做。只有在相同的區域作用域中擁有兩個名稱相同的變數才會是錯誤。
我們會像這樣偵測該錯誤
Token* name = &parser.previous;
在 declareVariable() 中
for (int i = current->localCount - 1; i >= 0; i--) { Local* local = ¤t->locals[i]; if (local->depth != -1 && local->depth < current->scopeDepth) { break; } if (identifiersEqual(name, &local->name)) { error("Already a variable with this name in this scope."); } }
addLocal(*name); }
區域變數會在宣告時附加到陣列,這表示目前的作用域始終位於陣列的末端。當我們宣告新變數時,我們會從結尾開始向後搜尋,尋找具有相同名稱的現有變數。如果我們在目前的作用域中找到一個,我們會報告錯誤。否則,如果我們到達陣列的開頭或另一個作用域擁有的變數,則表示我們已經檢查了作用域中的所有現有變數。
若要查看兩個識別符號是否相同,我們會使用此方法
在 identifierConstant() 之後新增
static bool identifiersEqual(Token* a, Token* b) { if (a->length != b->length) return false; return memcmp(a->start, b->start, a->length) == 0; }
由於我們知道兩個詞素的長度,因此我們會先檢查長度。這將會快速導致許多不相等的字串失敗。如果 長度相同,我們會使用 memcmp() 檢查字元。若要取得 memcmp(),我們需要一個 include。
#include <stdlib.h>
#include <string.h>
#include "common.h"
有了這個,我們就可以讓變數誕生。但是,就像幽靈一樣,它們會在宣告它們的作用域之外徘徊。當程式區塊結束時,我們需要讓它們安息。
current->scopeDepth--;
在 endScope() 中
while (current->localCount > 0 && current->locals[current->localCount - 1].depth > current->scopeDepth) { emitByte(OP_POP); current->localCount--; }
}
當我們彈出作用域時,我們會向後走過區域陣列,尋找任何在我們剛剛離開的作用域深度宣告的變數。我們會透過簡單地減少陣列的長度來捨棄它們。
這裡也有執行階段元件。區域變數會佔用堆疊上的槽。當區域變數超出作用域時,就不再需要該槽,應該釋放它。因此,對於我們捨棄的每個變數,我們也會發出一個 OP_POP 指令,以將其從堆疊中彈出。
22 . 4使用區域變數
我們現在可以編譯和執行區域變數宣告。在執行階段,它們的值會位於堆疊上的應有位置。讓我們開始使用它們。我們會同時執行變數存取和賦值,因為它們會接觸到編譯器中的相同函數。
我們已經有取得和設定全域變數的程式碼,而且—就像好的軟體工程師一樣—我們希望盡可能重複使用現有的程式碼。類似這樣
static void namedVariable(Token name, bool canAssign) {
在 namedVariable() 中
取代 1 行
uint8_t getOp, setOp; int arg = resolveLocal(current, &name); if (arg != -1) { getOp = OP_GET_LOCAL; setOp = OP_SET_LOCAL; } else { arg = identifierConstant(&name); getOp = OP_GET_GLOBAL; setOp = OP_SET_GLOBAL; }
if (canAssign && match(TOKEN_EQUAL)) {
我們不是硬式編碼發出用於變數存取和賦值的位元碼指令,而是使用幾個 C 變數。首先,我們嘗試尋找具有指定名稱的區域變數。如果我們找到一個,我們會使用用於處理區域變數的指令。否則,我們假設它是全域變數,並使用現有的全域變數位元碼指令。
在下方一點,我們使用這些變數發出正確的指令。對於賦值
if (canAssign && match(TOKEN_EQUAL)) {
expression();
在 namedVariable() 中
取代 1 行
emitBytes(setOp, (uint8_t)arg);
} else {
對於存取
emitBytes(setOp, (uint8_t)arg);
} else {
在 namedVariable() 中
取代 1 行
emitBytes(getOp, (uint8_t)arg);
}
本章的真正核心(我們解析區域變數的部分)在這裡
在 identifiersEqual() 之後新增
static int resolveLocal(Compiler* compiler, Token* name) { for (int i = compiler->localCount - 1; i >= 0; i--) { Local* local = &compiler->locals[i]; if (identifiersEqual(name, &local->name)) { return i; } } return -1; }
總而言之,這很簡單。我們會走過目前在作用域中的區域變數清單。如果其中一個變數的名稱與識別符號 Token 相同,則識別符號必須參考該變數。我們找到它了!我們會向後走過陣列,以便找到具有識別符號的最後宣告變數。這可確保內部的區域變數可以正確地遮蔽周圍作用域中具有相同名稱的區域變數。
在執行階段,我們會使用堆疊槽索引載入和儲存區域變數,因此這就是編譯器在解析變數後需要計算的內容。每當宣告變數時,我們都會將其附加到 Compiler 中的區域陣列。這表示第一個區域變數的索引為零,下一個區域變數的索引為一,依此類推。換句話說,編譯器中的區域陣列與 VM 的堆疊在執行階段具有完全相同的配置。變數在區域陣列中的索引與其堆疊槽相同。真是太方便了!
如果我們走完整個陣列後沒有找到具有指定名稱的變數,則它一定不是區域變數。在這種情況下,我們會傳回 -1 以表示找不到它,應該假設它是一個全域變數。
22 . 4 . 1解譯區域變數
我們的編譯器正在發出兩個新的指令,因此讓我們讓它們運作。首先是載入區域變數
OP_POP,
在 enum OpCode 中
OP_GET_LOCAL,
OP_GET_GLOBAL,
及其實作
case OP_POP: pop(); break;
在 run() 中
case OP_GET_LOCAL: { uint8_t slot = READ_BYTE(); push(vm.stack[slot]); break; }
case OP_GET_GLOBAL: {
它會為區域變數所在的堆疊槽取得單一位元組運算元。它會從該索引載入值,然後將其推送到堆疊頂端,以便後續指令可以找到它。
接下來是賦值
OP_GET_LOCAL,
在 enum OpCode 中
OP_SET_LOCAL,
OP_GET_GLOBAL,
您大概可以預測其實作。
}
在 run() 中
case OP_SET_LOCAL: { uint8_t slot = READ_BYTE(); vm.stack[slot] = peek(0); break; }
case OP_GET_GLOBAL: {
它會從堆疊頂端取得指定的值,並將其儲存在對應於區域變數的堆疊槽中。請注意,它不會從堆疊中彈出該值。請記住,賦值是一個表達式,每個表達式都會產生一個值。賦值表達式的值就是被賦的值本身,因此 VM 只是將該值留在堆疊上。
如果沒有對這兩個新指令的支援,我們的反組譯器是不完整的。
return simpleInstruction("OP_POP", offset);
在 disassembleInstruction() 中
case OP_GET_LOCAL: return byteInstruction("OP_GET_LOCAL", chunk, offset); case OP_SET_LOCAL: return byteInstruction("OP_SET_LOCAL", chunk, offset);
case OP_GET_GLOBAL:
編譯器會將區域變數編譯為直接存取槽。區域變數的名稱永遠不會離開編譯器而進入程式碼區塊。這對效能來說很好,但對內省來說就不太好。當我們反組譯這些指令時,我們無法像處理全域變數那樣顯示變數的名稱。相反地,我們只顯示槽號。
在 simpleInstruction() 之後新增
static int byteInstruction(const char* name, Chunk* chunk, int offset) { uint8_t slot = chunk->code[offset + 1]; printf("%-16s %4d\n", name, slot); return offset + 2; }
22 . 4 . 2另一個作用域邊緣案例
我們已經花了一些時間來處理一些關於作用域的奇怪邊緣案例。我們確保遮蔽可以正確運作。如果同一個區域作用域中的兩個變數具有相同的名稱,我們會報告錯誤。由於我不太清楚的原因,變數作用域似乎有很多這樣的問題。我從未見過任何語言感覺它完全優雅。
在結束本章之前,我們還有一個邊緣案例要處理。回想一下我們在 jlox 的變數解析實作中首次遇到的這個奇怪的傢伙
{
var a = "outer";
{
var a = a;
}
}
當時我們透過將變數的宣告分為兩個階段來解決它,我們在這裡也會這樣做
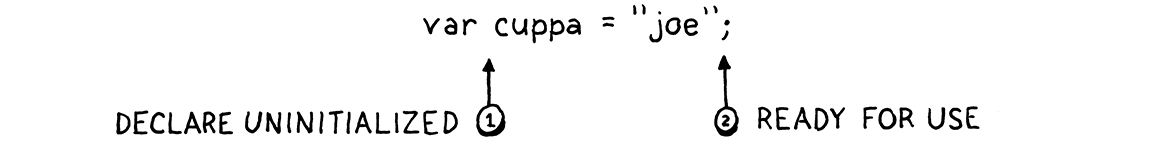
當變數宣告開始時—換句話說,在其初始化程式之前—該名稱會在目前作用域中宣告。變數存在,但處於特殊的「未初始化」狀態。然後我們編譯初始化程式。如果在該表達式中的任何時候,我們解析一個指向該變數的識別符號,我們會看到它尚未初始化並報告錯誤。在我們完成編譯初始化程式後,我們會將變數標記為已初始化且可以使用。
為了實現這一點,當我們宣告一個區域變數時,我們需要以某種方式指示「未初始化」狀態。我們可以在 Local 中新增一個新的欄位,但讓我們在記憶體使用上更節省一點。相反地,我們會將變數的作用域深度設定為一個特殊的哨兵值,-1。
local->name = name;
在 addLocal() 中
取代 1 行
local->depth = -1;
}
稍後,一旦變數的初始化程式被編譯完成,我們會將其標記為已初始化。
if (current->scopeDepth > 0) {
在 defineVariable() 中
markInitialized();
return; }
這是如此實現的
在 parseVariable() 之後新增
static void markInitialized() { current->locals[current->localCount - 1].depth = current->scopeDepth; }
因此,這才是編譯器中「宣告」和「定義」變數的真正含義。「宣告」是指將變數新增到作用域中,而「定義」是指該變數變得可用。
當我們解析對區域變數的引用時,我們會檢查作用域深度,以查看它是否已完全定義。
if (identifiersEqual(name, &local->name)) {
在 resolveLocal() 中
if (local->depth == -1) { error("Can't read local variable in its own initializer."); }
return i;
如果變數具有哨兵深度,則它必須是對其自身初始化程式中變數的引用,我們會將其報告為錯誤。
本章就到這裡!我們新增了區塊、區域變數和真正的詞法作用域。考慮到我們為變數引入了完全不同的運行時表示形式,我們不必編寫大量程式碼。實作結果相當乾淨且有效率。
您會注意到,我們編寫的幾乎所有程式碼都在編譯器中。在運行時,它只有兩個小指令。您會看到這在 clox 與 jlox 相比是一個持續的趨勢。最佳化器工具箱中最重要的一項是將工作提前到編譯器中,這樣您就不必在運行時執行它。在本章中,這意味著解析每個區域變數確切佔用的堆疊槽。這樣一來,在運行時就不需要進行任何查閱或解析。
挑戰
-
我們簡單的區域陣列可以很容易地計算每個區域變數的堆疊槽。但這意味著當編譯器解析對變數的引用時,我們必須對陣列進行線性掃描。
提出更有效率的方法。您認為額外的複雜性值得嗎?
-
其他語言如何處理像這樣的程式碼
var a = a;
如果那是您的語言,您會怎麼做?為什麼?
-
許多語言區分了可以重新賦值的變數和不能重新賦值的變數。在 Java 中,
final修飾符會阻止您向變數賦值。在 JavaScript 中,使用let宣告的變數可以賦值,但使用const宣告的變數則不能。Swift 將let視為單次賦值,並使用var表示可賦值的變數。Scala 和 Kotlin 使用val和var。為 Lox 新增一個單次賦值變數形式的關鍵字。為您的選擇辯護,然後實現它。嘗試向使用您新關鍵字宣告的變數賦值應該會導致編譯錯誤。
-
擴充 clox 以允許在同一時間內有超過 256 個區域變數在作用域中。