解析與綁定
偶爾你會發現自己處於一種奇怪的狀況。你一步步地、以最自然的方式進入這種狀況,但當你身處其中時,你突然感到驚訝,並問自己這一切究竟是如何發生的。
索爾·海爾達爾,《康提基號》
噢,不!我們的語言實作正在漏水!早在我們加入變數和程式區塊時,我們就有了緊密的作用域。但是當我們後來加入閉包時,我們原本防水的直譯器出現了一個漏洞。大多數真實的程式不太可能滑過這個漏洞,但作為語言實作者,我們發誓要關心正確性,即使在語義最深、最潮濕的角落也是如此。
我們將用整整一章來探索這個漏洞,然後仔細修補它。在這個過程中,我們將更嚴格地理解 Lox 以及 C 傳統中的其他語言所使用的詞法作用域。我們也將有機會了解語義分析—一種強大的技術,可以在不必執行程式碼的情況下從使用者的原始碼中提取意義。
11.1靜態作用域
快速複習:Lox 與大多數現代語言一樣,使用詞法作用域。這意味著你可以僅透過閱讀程式的文字來找出變數名稱所指的宣告。例如:
var a = "outer"; { var a = "inner"; print a; }
在這裡,我們知道正在列印的 a 是前一行宣告的變數,而不是全域變數。執行程式不會—不能—影響這一點。作用域規則是語言靜態語義的一部分,這就是為什麼它們也稱為靜態作用域。
我還沒有明確說明這些作用域規則,但現在是精確的時候了。
變數的使用是指程式碼中,在包含使用該變數的表達式之最內層作用域中,同名的前一個宣告。
這句話有很多東西需要拆解。
-
我使用「變數使用」而不是「變數表達式」來涵蓋變數表達式和賦值。對「使用該變數的表達式」也是如此。
-
「前一個」表示在程式文字中之前出現。
var a = "outer"; { print a; var a = "inner"; }
在這裡,正在列印的
a是外層的,因為它出現在使用它的print語句之前。在大多數情況下,在直線程式碼中,文字中前面的宣告也將在時間上早於使用。但情況並非總是如此。正如我們將看到的,函式可能會延遲一段程式碼,使其動態時間執行不再反映靜態文字順序。 -
「最內層」的存在是因為我們的好朋友遮蔽。在封閉的作用域中,可能有不止一個具有給定名稱的變數,如下所示:
var a = "outer"; { var a = "inner"; print a; }
我們的規則通過說最內層的作用域獲勝來消除這種情況的歧義。
由於此規則沒有提及任何執行時行為,因此它表示變數表達式始終在程式的整個執行過程中指向相同的宣告。到目前為止,我們的直譯器大致上正確地實作了該規則。但是,當我們加入閉包時,一個錯誤悄悄地溜進來了。
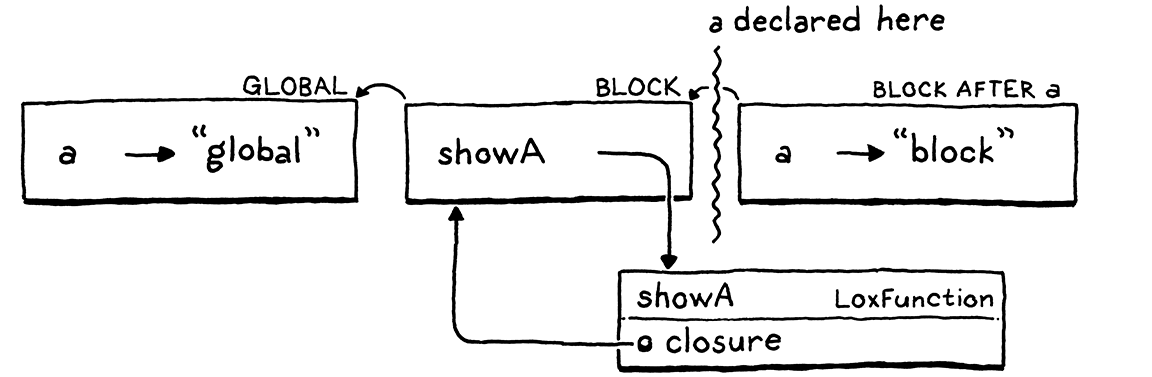
var a = "global"; { fun showA() { print a; } showA(); var a = "block"; showA(); }
在你輸入並執行此程式之前,請先決定你認為它應該列印什麼。
好 . . . 明白了嗎?如果你熟悉其他語言中的閉包,你會期望它列印「global」兩次。第一次呼叫 showA() 肯定應該列印「global」,因為我們甚至還沒有到達內部 a 的宣告。根據我們的規則,變數表達式總是解析為相同的變數,這表示第二次呼叫 showA() 應該列印相同的內容。
唉,它列印:
global block
讓我強調一下,此程式從未重新賦值任何變數,並且僅包含單一 print 語句。然而,不知何故,對於從未賦值的變數的 print 語句在不同的時間點列印了兩個不同的值。我們肯定在某個地方弄壞了東西。
11.1.1作用域和可變環境
在我們的直譯器中,環境是靜態作用域的動態體現。兩者大多保持同步—當我們進入新的作用域時,我們創建一個新的環境,當我們離開作用域時,我們丟棄它。我們對環境執行的另一個操作是:在其中綁定變數。這就是我們錯誤所在。
讓我們逐步瀏覽那個有問題的範例,看看每一步的環境是什麼樣子。首先,我們在全域作用域中宣告 a。

這給我們一個單一的環境,其中有一個單一的變數。然後我們進入程式區塊並執行 showA() 的宣告。
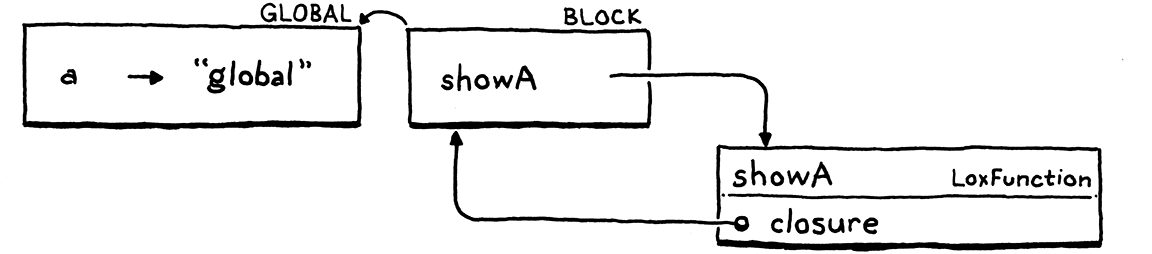
我們為該程式區塊取得一個新的環境。在其中,我們宣告一個名稱 showA,它綁定到我們建立來表示函式的 LoxFunction 物件。該物件有一個 closure 欄位,用於捕獲宣告函式的環境,因此它具有返回到程式區塊環境的參考。
現在我們呼叫 showA()。
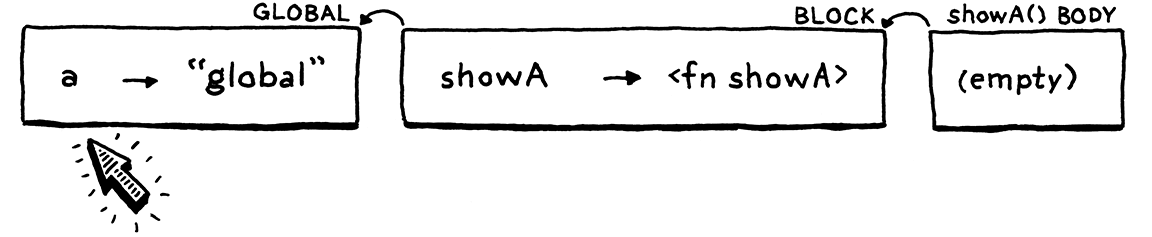
直譯器為 showA() 的函式主體動態創建一個新的環境。它是空的,因為該函式沒有宣告任何變數。該環境的父環境是該函式的閉包—外部程式區塊環境。
在 showA() 的主體內部,我們列印 a 的值。直譯器透過遍歷環境鏈來查找此值。它一直到達全域環境才在那裡找到它並列印 "global"。太棒了。
接下來,我們宣告第二個 a,這次是在程式區塊內部。
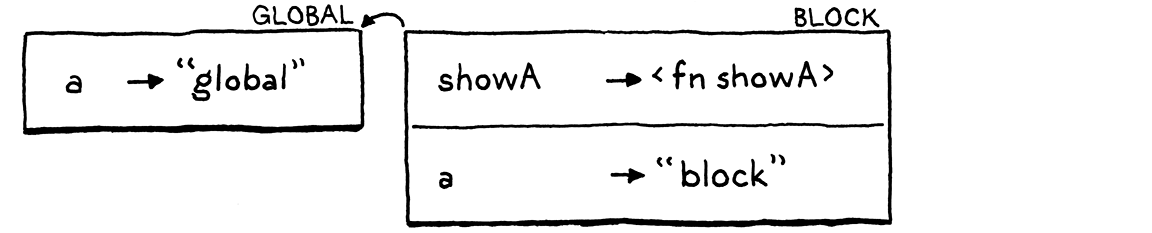
它與 showA() 位於相同的程式區塊—相同的作用域—中,因此它會進入相同的環境,這也是 showA() 的閉包所參考的相同環境。這就是有趣的地方。我們再次呼叫 showA()。
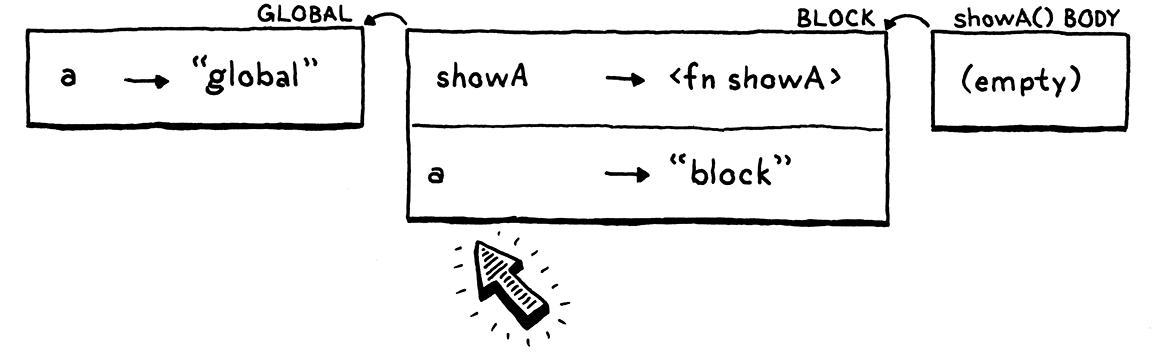
我們再次為 showA() 的主體創建一個新的空環境,將它連接到該閉包,然後運行主體。當直譯器遍歷環境鏈以查找 a 時,它現在在程式區塊環境中發現了新的 a。嗚。
我選擇以一種我希望與你對作用域的非正式直覺一致的方式來實作環境。我們傾向於認為程式區塊中的所有程式碼都位於相同的作用域中,因此我們的直譯器使用單一環境來表示它。每個環境都是一個可變的雜湊表。當宣告一個新的局部變數時,它會被添加到該作用域的現有環境中。
這個直覺,就像生活中的許多事物一樣,並不完全正確。程式區塊不一定都位於相同的作用域中。考慮一下:
{
var a;
// 1.
var b;
// 2.
}
在第一個標記的行中,只有 a 在作用域中。在第二行,a 和 b 都在作用域中。如果你將「作用域」定義為一組宣告,那麼它們顯然不是相同的範圍—它們不包含相同的宣告。這就像每個 var 語句將程式區塊分割為兩個獨立的作用域,宣告變數之前的那個作用域和之後的那個作用域,後者包括新的變數。
但是在我們的實作中,環境的行為就像整個程式區塊都是一個作用域,只是一個隨著時間變化的作用域。閉包不喜歡這樣。當宣告一個函式時,它會捕獲對當前環境的參考。函式應該捕獲環境的凍結快照,就像它在宣告函式時存在的那樣。但是,在 Java 程式碼中,它具有對實際可變環境物件的參考。當稍後在與該環境對應的作用域中宣告變數時,閉包會看到新的變數,即使該宣告並未在函式之前出現。
11.1.2持久環境
有一種程式設計風格使用所謂的持久資料結構。與你在命令式程式設計中熟悉的鬆散資料結構不同,持久資料結構永遠無法直接修改。相反,對現有結構的任何「修改」都會產生一個全新的物件,其中包含所有原始資料和新的修改。原始物件保持不變。
如果我們將該技術應用於 Environment,那麼每次您宣告變數時,它都會返回一個新的環境,其中包含所有先前宣告的變數以及一個新的名稱。宣告變數將會執行隱式的「分割」,在宣告變數之前和之後都會有一個環境。
閉包會保留對函式宣告時所使用 Environment 實例的參考。由於該區塊中任何後續的宣告都會產生新的 Environment 物件,因此閉包將看不到新的變數,並且我們的錯誤將會被修正。
這是一個解決問題的合法方法,也是在 Scheme 解譯器中實作環境的經典方法。我們也可以為 Lox 這樣做,但這意味著要回頭修改一大堆現有的程式碼。
我不會帶您經歷那一切。我們將保持環境的表示方式不變。我們不會讓資料更具靜態結構,而是將靜態解析融入到存取操作本身中。
11 . 2語義分析
我們的解譯器會解析一個變數—追蹤它指的是哪個宣告—在每次評估變數運算式時都這樣做。如果該變數被包裹在一個執行一千次的迴圈中,則該變數將會被重新解析一千次。
我們知道靜態作用域意味著變數的使用始終解析為相同的宣告,這可以僅透過查看文字來確定。鑑於此,為什麼我們要每次都動態地執行此操作?這樣做不僅會打開導致我們煩人錯誤的漏洞,而且還會不必要地緩慢。
一個更好的解決方案是一次解析每個變數的使用。編寫一段程式碼來檢查使用者的程式,找到每個提及的變數,並找出每個變數指的是哪個宣告。此過程是語義分析的一個範例。解析器僅判斷程式在文法上是否正確(語法分析),而語義分析則更進一步,開始弄清楚程式的各個部分實際上意味著什麼。在這種情況下,我們的分析將解析變數綁定。我們不僅會知道一個運算式是一個變數,還會知道它是哪個變數。
我們有很多方法可以儲存變數及其宣告之間的綁定。當我們為 Lox 建立 C 解譯器時,我們將有更有效的方式來儲存和存取區域變數。但是對於 jlox,我希望盡可能減少我們對現有程式碼庫造成的損害。我不希望丟棄一堆大部分都還可以的程式碼。
相反,我們將以一種可以充分利用現有 Environment 類別的方式來儲存解析。回想一下,在有問題的範例中,如何解讀對 `a` 的存取。
在第一次(正確)的評估中,我們查看鏈中的三個環境,然後才找到 `a` 的全域宣告。然後,當稍後在區塊作用域中宣告內部 `a` 時,它會遮蔽全域的 `a`。
下一次查找會遍歷鏈,在第二個環境中找到 `a` 並在此停止。每個環境都對應一個宣告變數的單一詞法作用域。如果我們能夠確保變數查找始終在環境鏈中遍歷相同數量的連結,那將確保每次都在相同的作用域中找到相同的變數。
要「解析」變數的使用,我們只需要計算在環境鏈中宣告的變數將會距離多遠的「跳轉」。有趣的問題是何時執行此計算—或者,換句話說,我們在解譯器的實作中的哪個位置塞入其程式碼?
由於我們正在根據原始碼的結構計算靜態屬性,因此顯而易見的答案是在解析器中。那是傳統的位置,也是我們稍後在 clox 中放置它的地方。它在這裡也可以工作,但我想要一個藉口向您展示另一種技術。我們將把我們的解析器寫成一個單獨的傳遞。
11 . 2 . 1變數解析傳遞
在解析器產生語法樹之後,但在解譯器開始執行它之前,我們將對樹執行一次單次遍歷,以解析其中包含的所有變數。解析和執行之間的其他傳遞很常見。如果 Lox 具有靜態型別,我們可以在那裡插入型別檢查器。最佳化通常也以這種方式在單獨的傳遞中實作。基本上,任何不依賴僅在執行階段可用的狀態的工作都可以以這種方式完成。
我們的變數解析傳遞就像一種小型解譯器。它會遍歷樹,訪問每個節點,但是靜態分析與動態執行不同。
-
沒有副作用。當靜態分析訪問列印語句時,它實際上不會列印任何內容。對外部函式或其他與外界接觸的操作的呼叫會被存根化且沒有任何效果。
-
沒有控制流程。迴圈只會被訪問一次。`if` 語句中的兩個分支都會被訪問。邏輯運算子不會短路。
11 . 3解析器類別
與 Java 中的所有事物一樣,我們的變數解析傳遞也體現在一個類別中。
建立新檔案
package com.craftinginterpreters.lox; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Stack; class Resolver implements Expr.Visitor<Void>, Stmt.Visitor<Void> { private final Interpreter interpreter; Resolver(Interpreter interpreter) { this.interpreter = interpreter; } }
由於解析器需要訪問語法樹中的每個節點,因此它會實作我們已有的訪問者抽象。在解析變數時,只有少數幾種節點是令人感興趣的。
-
區塊語句會為其包含的語句引入新的作用域。
-
函式宣告會為其主體引入新的作用域,並在其作用域中繫結其參數。
-
變數宣告會將新的變數新增到目前的作用域。
-
變數和賦值運算式需要解析它們的變數。
其餘的節點沒有做任何特別的事情,但是我們仍然需要為它們實作訪問方法,以遍歷它們的子樹。即使 `+` 運算式本身沒有任何要解析的變數,它的任一運算元都可能有。
11 . 3 . 1解析區塊
我們從區塊開始,因為它們會建立所有魔法發生的本機作用域。
在 Resolver() 之後新增
@Override public Void visitBlockStmt(Stmt.Block stmt) { beginScope(); resolve(stmt.statements); endScope(); return null; }
這會開始新的作用域,遍歷區塊內的語句,然後捨棄該作用域。有趣的東西位於那些輔助方法中。我們從簡單的方法開始。
在 Resolver() 之後新增
void resolve(List<Stmt> statements) { for (Stmt statement : statements) { resolve(statement); } }
這會遍歷語句列表並解析每個語句。它會接著呼叫
在 visitBlockStmt() 之後新增
private void resolve(Stmt stmt) { stmt.accept(this); }
在我們進行的同時,讓我們新增另一個重載,我們稍後將需要它來解析運算式。
在 resolve(Stmt stmt) 之後新增
private void resolve(Expr expr) { expr.accept(this); }
這些方法與 Interpreter 中的 `evaluate()` 和 `execute()` 方法類似—它們會轉而將訪問者模式應用於給定的語法樹節點。
真正的有趣行為是圍繞作用域。像這樣建立新的區塊作用域
在 resolve() 之後新增
private void beginScope() { scopes.push(new HashMap<String, Boolean>()); }
詞法作用域會嵌套在解譯器和解析器中。它們的行為類似堆疊。解譯器使用連結列表實作該堆疊—Environment 物件的鏈。在解析器中,我們使用實際的 Java Stack。
private final Interpreter interpreter;
在類別 Resolver 中
private final Stack<Map<String, Boolean>> scopes = new Stack<>();
Resolver(Interpreter interpreter) {
此欄位會追蹤目前處於作用域中的作用域堆疊。堆疊中的每個元素都是一個 Map,表示單一的區塊作用域。與 Environment 中一樣,鍵是變數名稱。值是布林值,原因我稍後會解釋。
作用域堆疊僅用於本機區塊作用域。在全域作用域的最上層宣告的變數不會被解析器追蹤,因為它們在 Lox 中更具動態性。在解析變數時,如果我們在本地作用域的堆疊中找不到它,我們會假設它一定是全域變數。
由於作用域儲存在明確的堆疊中,因此退出一個作用域很簡單。
在 beginScope() 之後新增
private void endScope() { scopes.pop(); }
現在我們可以推送和彈出一個空作用域的堆疊。讓我們在它們中放入一些東西。
11 . 3 . 2解析變數宣告
解析變數宣告會將新的條目新增到目前最內層的作用域的對應表中。這看起來很簡單,但是我們需要做一些小小的處理。
在 visitBlockStmt() 之後新增
@Override public Void visitVarStmt(Stmt.Var stmt) { declare(stmt.name); if (stmt.initializer != null) { resolve(stmt.initializer); } define(stmt.name); return null; }
我們將繫結分成兩個步驟:宣告然後定義,以便處理類似以下這種有趣的邊緣案例
var a = "outer"; { var a = a; }
當本機變數的初始值設定式引用與正在宣告的變數同名的變數時,會發生什麼情況?我們有幾種選擇
-
執行初始值設定式,然後將新變數放入作用域中。在這裡,新的本機 `a` 將使用「outer」進行初始化,它是全域變數的值。換句話說,先前的宣告會被轉換成
var temp = a; // Run the initializer. var a; // Declare the variable. a = temp; // Initialize it.
-
將新變數放入作用域中,然後執行初始值設定式。這意味著您可以在變數初始化之前觀察到它,因此我們需要弄清楚它那時會具有什麼值。可能是 `nil`。這意味著新的本機 `a` 將會被重新初始化為其自己的隱式初始值 `nil`。現在,轉換成程式碼的樣子會像這樣
var a; // Define the variable. a = a; // Run the initializer.
-
在初始值設定式中引用變數會發生錯誤。如果初始值設定式提及正在初始化的變數,則讓解譯器在編譯時或執行階段失敗。
以上的前兩個選項中,哪個看起來像是使用者實際想要的?遮蔽很少見且通常是錯誤,因此基於被遮蔽的變數的值來初始化遮蔽變數似乎不太可能是故意的。
第二個選項甚至更沒有用處。新變數將始終具有值 `nil`。永遠沒有必要按名稱提及它。您可以使用明確的 `nil` 代替。
由於前兩個選項可能會掩蓋使用者錯誤,因此我們將採用第三個選項。此外,我們會將它設為編譯錯誤而不是執行階段錯誤。這樣,使用者在執行任何程式碼之前就會收到問題警報。
為了做到這一點,當我們訪問運算式時,我們需要知道我們是否在某個變數的初始值設定式內。我們透過將繫結分成兩個步驟來做到這一點。第一個是宣告它。
在 endScope() 之後新增
private void declare(Token name) { if (scopes.isEmpty()) return; Map<String, Boolean> scope = scopes.peek(); scope.put(name.lexeme, false); }
宣告會將變數新增到最內層的作用域,使其遮蔽任何外部作用域的變數,並讓我們知道該變數存在。我們將其名稱與作用域映射中的 false 綁定,以將其標記為「尚未準備好」。作用域映射中與鍵關聯的值表示我們是否已完成解析該變數的初始化運算式。
宣告變數後,我們會在新的變數存在但不可用的同一個作用域中,解析其初始化運算式。一旦初始化運算式完成,變數就準備好正式使用。我們透過定義它來做到這一點。
在 declare() 後新增
private void define(Token name) { if (scopes.isEmpty()) return; scopes.peek().put(name.lexeme, true); }
我們將變數的值在作用域映射中設定為 true,以將其標記為完全初始化並可供使用。它活起來了!
11.3.3解析變數運算式
變數宣告—以及我們將要介紹的函式宣告—會寫入作用域映射。當我們解析變數運算式時,會讀取這些映射。
在 visitVarStmt() 後新增
@Override public Void visitVariableExpr(Expr.Variable expr) { if (!scopes.isEmpty() && scopes.peek().get(expr.name.lexeme) == Boolean.FALSE) { Lox.error(expr.name, "Can't read local variable in its own initializer."); } resolveLocal(expr, expr.name); return null; }
首先,我們檢查是否正在其自身的初始化運算式中存取變數。這就是作用域映射中的值發揮作用的地方。如果變數存在於目前的作用域中,但其值為 false,則表示我們已宣告它,但尚未定義它。我們會報告該錯誤。
在檢查之後,我們實際上使用此輔助函式解析變數本身
在 define() 後新增
private void resolveLocal(Expr expr, Token name) { for (int i = scopes.size() - 1; i >= 0; i--) { if (scopes.get(i).containsKey(name.lexeme)) { interpreter.resolve(expr, scopes.size() - 1 - i); return; } } }
這看起來很像 Environment 中用於評估變數的程式碼,這是理所當然的。我們從最內層的作用域開始,向外移動,在每個映射中尋找相符的名稱。如果我們找到該變數,我們會解析它,並傳入目前最內層的作用域與找到變數的作用域之間的範圍數量。因此,如果在目前的作用域中找到變數,我們會傳入 0。如果在緊鄰的封閉作用域中,則傳入 1。你應該明白了。
如果我們走遍所有區塊作用域,但始終找不到該變數,我們會將其保留為未解析,並假設它是全域的。我們稍後會介紹 resolve() 方法的實作。現在,讓我們繼續處理其他語法節點。
11.3.4解析賦值運算式
另一個引用變數的運算式是賦值。解析賦值看起來像這樣
在 visitVarStmt() 後新增
@Override public Void visitAssignExpr(Expr.Assign expr) { resolve(expr.value); resolveLocal(expr, expr.name); return null; }
首先,我們會解析賦值的運算式,以防其中也包含對其他變數的參考。然後,我們使用現有的 resolveLocal() 方法來解析被賦值的變數。
11.3.5解析函式宣告
最後是函式。函式既會綁定名稱,也會引入作用域。函式本身的名稱會綁定到宣告函式的周圍作用域中。當我們進入函式的主體時,也會將其參數綁定到內部的函式作用域中。
在 visitBlockStmt() 之後新增
@Override public Void visitFunctionStmt(Stmt.Function stmt) { declare(stmt.name); define(stmt.name); resolveFunction(stmt); return null; }
與 visitVariableStmt() 類似,我們會在目前的作用域中宣告和定義函式的名稱。但是,與變數不同的是,我們會在解析函式的主體之前,搶先定義名稱。這讓函式可以在其自身的主體內遞迴地引用自身。
然後,我們使用以下方法解析函式的主體
在 resolve() 之後新增
private void resolveFunction(Stmt.Function function) { beginScope(); for (Token param : function.params) { declare(param); define(param); } resolve(function.body); endScope(); }
這是一個獨立的方法,因為當我們稍後新增類別時,我們也會將其用於解析 Lox 方法。它會為主體建立新的作用域,然後為函式的每個參數綁定變數。
準備好之後,它會在該作用域中解析函式的主體。這與解譯器處理函式宣告的方式不同。在執行階段,宣告函式不會對函式的主體做任何事。函式的主體要到稍後呼叫函式時才會被觸及。在靜態分析中,我們會立即遍歷到主體中。
11.3.6解析其他語法樹節點
這涵蓋了語法的有趣角落。我們處理宣告、讀取或寫入變數的每個位置,以及建立或銷毀作用域的每個位置。即使變數解析不會影響它們,我們也需要所有其他語法樹節點的 visit 方法,以便遞迴到它們的子樹中。很抱歉,這部分很無聊,但請耐心點。我們將採取「由上而下」的方式,從陳述式開始。
一個運算式陳述式包含一個要遍歷的運算式。
在 visitBlockStmt() 之後新增
@Override public Void visitExpressionStmt(Stmt.Expression stmt) { resolve(stmt.expression); return null; }
if 陳述式有一個條件的運算式,以及一個或兩個分支的陳述式。
在 visitFunctionStmt() 後新增
@Override public Void visitIfStmt(Stmt.If stmt) { resolve(stmt.condition); resolve(stmt.thenBranch); if (stmt.elseBranch != null) resolve(stmt.elseBranch); return null; }
在這裡,我們看到解析與解譯的不同之處。當我們解析 if 陳述式時,沒有控制流程。我們會解析條件和兩個分支。動態執行只會進入正在執行的分支,而靜態分析則比較保守—它會分析可能執行的任何分支。由於執行階段可能會到達任一分支,因此我們會解析這兩個分支。
與運算式陳述式一樣,print 陳述式包含單一子運算式。
在 visitIfStmt() 後新增
@Override public Void visitPrintStmt(Stmt.Print stmt) { resolve(stmt.expression); return null; }
回傳也是一樣。
在 visitPrintStmt() 後新增
@Override public Void visitReturnStmt(Stmt.Return stmt) { if (stmt.value != null) { resolve(stmt.value); } return null; }
如同在 if 陳述式中,使用 while 陳述式,我們會解析其條件並只解析主體一次。
在 visitVarStmt() 後新增
@Override public Void visitWhileStmt(Stmt.While stmt) { resolve(stmt.condition); resolve(stmt.body); return null; }
這涵蓋了所有陳述式。接下來是運算式 . . .
我們老朋友二元運算式。我們會遍歷並解析兩個運算元。
在 visitAssignExpr() 後新增
@Override public Void visitBinaryExpr(Expr.Binary expr) { resolve(expr.left); resolve(expr.right); return null; }
呼叫類似—我們遍歷引數清單並解析所有引數。被呼叫的東西也是一個運算式(通常是變數運算式),因此也會被解析。
在 visitBinaryExpr() 後新增
@Override public Void visitCallExpr(Expr.Call expr) { resolve(expr.callee); for (Expr argument : expr.arguments) { resolve(argument); } return null; }
括號很簡單。
在 visitCallExpr() 後新增
@Override public Void visitGroupingExpr(Expr.Grouping expr) { resolve(expr.expression); return null; }
常值是最簡單的。
在 visitGroupingExpr() 後新增
@Override public Void visitLiteralExpr(Expr.Literal expr) { return null; }
常值運算式不會提及任何變數,也不包含任何子運算式,因此不需要做任何事。
由於靜態分析不會執行控制流程或短路,因此邏輯運算式與其他二元運算子完全相同。
在 visitLiteralExpr() 後新增
@Override public Void visitLogicalExpr(Expr.Logical expr) { resolve(expr.left); resolve(expr.right); return null; }
最後,是最後一個節點。我們會解析它的其中一個運算元。
在 visitLogicalExpr() 後新增
@Override public Void visitUnaryExpr(Expr.Unary expr) { resolve(expr.right); return null; }
有了所有這些 visit 方法,Java 編譯器應該會滿意 Resolver 完全實作了 Stmt.Visitor 和 Expr.Visitor。現在是休息一下、吃點心、或許小睡片刻的好時機。
11.4解譯已解析的變數
讓我們看看我們的解析器有什麼用。每次它存取變數時,它都會告訴解譯器,目前作用域與定義變數的作用域之間有多少個作用域。在執行階段,這完全對應於目前環境與解譯器可以找到變數值的封閉環境之間的環境數量。解析器透過呼叫這個方法將該數字傳遞給解譯器
在 execute() 後新增
void resolve(Expr expr, int depth) { locals.put(expr, depth); }
我們想要將解析資訊儲存在某個地方,以便在稍後執行變數或賦值運算式時使用,但要儲存在哪裡?一個顯而易見的地方是直接在語法樹節點本身中。這是一種很好的方法,許多編譯器都將這類分析的結果儲存在這裡。
我們可以這樣做,但這需要修改我們的語法樹產生器。相反地,我們將採取另一種常見的方法,將其儲存在一個將每個語法樹節點與其解析資料關聯起來的映射中。
像 IDE 這樣的互動式工具通常會逐步重新解析和重新解析使用者程式的部分。當狀態的位元隱藏在語法樹的枝葉中時,可能很難找到所有需要重新計算的狀態位元。將這些資料儲存在節點外部的好處是可以輕鬆地捨棄它—只需清除映射即可。
private Environment environment = globals;
在 class Interpreter 中
private final Map<Expr, Integer> locals = new HashMap<>();
Interpreter() {
你可能會認為當有多個運算式引用同一個變數時,我們需要某種巢狀樹狀結構,以避免混淆,但每個運算式節點都是它自己的 Java 物件,具有自己獨特的識別碼。單一的整體映射在將它們分開方面沒有任何問題。
與往常一樣,使用集合需要我們匯入幾個名稱。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
還有
import java.util.List;
import java.util.Map;
class Interpreter implements Expr.Visitor<Object>,
11.4.1存取已解析的變數
我們的解譯器現在可以存取每個變數的已解析位置。最後,我們要利用它。我們用這個取代變數運算式的 visit 方法
public Object visitVariableExpr(Expr.Variable expr) {
在 visitVariableExpr() 中
取代 1 行
return lookUpVariable(expr.name, expr);
}
這會委派給
在 visitVariableExpr() 後新增
private Object lookUpVariable(Token name, Expr expr) { Integer distance = locals.get(expr); if (distance != null) { return environment.getAt(distance, name.lexeme); } else { return globals.get(name); } }
這裡有幾件事正在進行。首先,我們會查詢映射中已解析的距離。請記住,我們只解析區域變數。全域變數會被特殊處理,不會出現在映射中(因此稱為 locals)。因此,如果我們在映射中找不到距離,則它一定是全域的。在這種情況下,我們會直接在全域環境中動態地查詢它。如果未定義該變數,則會擲回執行階段錯誤。
如果我們確實取得距離,則表示我們有區域變數,而且我們可以利用靜態分析的結果。我們不會呼叫 get(),而是呼叫 Environment 上的這個新方法
在 define() 後新增
Object getAt(int distance, String name) { return ancestor(distance).values.get(name); }
舊的 get() 方法會動態地遍歷封閉環境的鏈,搜尋每個環境,看看該變數是否可能隱藏在某處。但現在我們確切地知道鏈中的哪個環境會擁有該變數。我們使用此輔助方法來到達它
在 define() 後新增
Environment ancestor(int distance) { Environment environment = this; for (int i = 0; i < distance; i++) { environment = environment.enclosing; } return environment; }
這會在父鏈中固定跳躍數,並傳回那裡的環境。一旦有了它,getAt() 就只會傳回該環境映射中變數的值。它甚至不必檢查變數是否在那裡—我們知道它會在,因為解析器已經提前找到它了。
11 . 4 . 2賦值給已解析的變數
我們也可以透過賦值來使用變數。訪問賦值表達式的變更類似。
public Object visitAssignExpr(Expr.Assign expr) {
Object value = evaluate(expr.value);
在 visitAssignExpr() 中
取代 1 行
Integer distance = locals.get(expr);
if (distance != null) {
environment.assignAt(distance, expr.name, value);
} else {
globals.assign(expr.name, value);
}
return value;
同樣地,我們查找變數的作用域距離。如果找不到,我們假設它是全域的,並以與之前相同的方式處理。否則,我們呼叫這個新的方法。
在 getAt() 之後添加
void assignAt(int distance, Token name, Object value) { ancestor(distance).values.put(name.lexeme, value); }
如同 getAt() 對應於 get(),assignAt() 對應於 assign()。它會走訪固定數量的環境,然後將新的值塞入該地圖中。
這些是直譯器唯一的變更。這就是為什麼我選擇一種對已解析資料侵入性最小的表示方式。其餘的節點都繼續像之前一樣工作。即使是修改環境的程式碼也沒有改變。
11 . 4 . 3執行解析器
不過,我們確實需要實際執行解析器。我們在解析器完成其魔法之後插入新的遍歷。
// Stop if there was a syntax error.
if (hadError) return;
在 run() 中
Resolver resolver = new Resolver(interpreter); resolver.resolve(statements);
interpreter.interpret(statements);
如果存在任何解析錯誤,我們就不會執行解析器。如果程式碼有語法錯誤,它永遠不會執行,所以解析它沒有太多價值。如果語法乾淨,我們會告訴解析器執行它的任務。解析器有一個對直譯器的參考,並在它走訪變數時直接將解析資料塞入其中。當直譯器下次執行時,它就擁有它所需的一切。
至少,如果解析器成功的話是這樣。但是,解析期間的錯誤呢?
11 . 5解析錯誤
由於我們正在進行語意分析遍歷,我們有機會讓 Lox 的語意更精確,並幫助使用者在執行程式碼之前儘早發現錯誤。看看這個糟糕的傢伙
fun bad() { var a = "first"; var a = "second"; }
我們確實允許在全域作用域中宣告具有相同名稱的多個變數,但在局部作用域中這樣做可能是一個錯誤。如果他們知道變數已經存在,他們應該會賦值給它,而不是使用 var。如果他們不知道它存在,他們可能也不打算覆寫先前的變數。
我們可以在解析時靜態地偵測到這個錯誤。
Map<String, Boolean> scope = scopes.peek();
在 declare() 中
if (scope.containsKey(name.lexeme)) { Lox.error(name, "Already a variable with this name in this scope."); }
scope.put(name.lexeme, false);
當我們在局部作用域中宣告一個變數時,我們已經知道先前在同一個作用域中宣告的每個變數的名稱。如果我們看到衝突,我們會報告一個錯誤。
11 . 5 . 1無效的返回錯誤
這是另一個糟糕的小腳本
return "at top level";
這會執行一個 return 語句,但它甚至不在任何函式內部。它是頂層程式碼。我不知道使用者認為會發生什麼,但我不認為我們希望 Lox 允許這樣做。
我們可以擴展解析器來靜態地偵測到這一點。就像我們在走訪樹狀結構時追蹤作用域一樣,我們可以追蹤我們目前正在訪問的程式碼是否在函式宣告內部。
private final Stack<Map<String, Boolean>> scopes = new Stack<>();
在類別 Resolver 中
private FunctionType currentFunction = FunctionType.NONE;
Resolver(Interpreter interpreter) {
我們不使用單純的布林值,而是使用這個有趣的列舉
在 Resolver() 之後新增
private enum FunctionType { NONE, FUNCTION }
現在看起來有點蠢,但我們稍後會再加入幾個案例,然後它就會更有意義。當我們解析函式宣告時,我們會傳入該值。
define(stmt.name);
在 visitFunctionStmt() 中
取代 1 行
resolveFunction(stmt, FunctionType.FUNCTION);
return null;
在 resolveFunction() 中,我們取得該參數並將其儲存在欄位中,然後再解析主體。
方法 resolveFunction()
取代 1 行
private void resolveFunction( Stmt.Function function, FunctionType type) { FunctionType enclosingFunction = currentFunction; currentFunction = type;
beginScope();
我們先將欄位的先前值儲存在局部變數中。請記住,Lox 具有局部函式,因此您可以任意深度地巢狀函式宣告。我們不僅需要追蹤我們是否在函式中,還要追蹤我們在多少個函式中。
我們可以使用 FunctionType 值的顯式堆疊來實現這一點,但相反地,我們將利用 JVM。我們將先前的值儲存在 Java 堆疊上的局部變數中。當我們完成解析函式主體時,我們將欄位還原為該值。
endScope();
在 resolveFunction() 中
currentFunction = enclosingFunction;
}
既然我們始終可以判斷我們是否在函式宣告內部,我們會在解析 return 語句時檢查這一點。
public Void visitReturnStmt(Stmt.Return stmt) {
在 visitReturnStmt() 中
if (currentFunction == FunctionType.NONE) { Lox.error(stmt.keyword, "Can't return from top-level code."); }
if (stmt.value != null) {
很棒,對吧?
還有最後一部分。回到將所有內容拼湊在一起的 Lox 主類別中,我們會謹慎地避免在遇到任何解析錯誤時執行直譯器。該檢查在解析器之前執行,因此我們不會嘗試解析語法無效的程式碼。
但是,如果存在解析錯誤,我們也需要跳過直譯器,因此我們添加另一個檢查。
resolver.resolve(statements);
在 run() 中
// Stop if there was a resolution error.
if (hadError) return;
interpreter.interpret(statements);
您可以想像在這裡進行許多其他分析。例如,如果我們在 Lox 中添加了 break 語句,我們可能希望確保它們僅在迴圈內部使用。
我們可以更進一步,針對不一定錯誤但可能沒有用的程式碼報告警告。例如,許多 IDE 會在 return 語句之後有無法到達的程式碼時,或是在從未讀取值的局部變數時發出警告。所有這些都非常容易添加到我們的靜態訪問遍歷中,或作為單獨的遍歷。
但是,就目前而言,我們將堅持使用有限的分析量。重要的是,我們修復了一個奇怪且令人惱火的邊緣案例錯誤,儘管它可能需要這麼多的工作才能完成,這可能會令人驚訝。
挑戰
-
當其他變數必須等到初始化後才能使用時,為什麼可以安全地及早定義綁定到函式名稱的變數?
-
您所知道的其他語言如何處理初始化程式中參考相同名稱的局部變數,例如
var a = "outer"; { var a = a; }
它是執行階段錯誤嗎?編譯錯誤?允許的嗎?它們對全域變數的處理方式是否不同?您是否同意它們的選擇?請證明您的答案。
-
擴展解析器以報告從未使用過局部變數的錯誤。
-
我們的解析器會計算變數所在的哪個環境,但它仍然透過該地圖中的名稱來查找。更有效率的環境表示法會將局部變數儲存在陣列中,並透過索引來查找它們。
擴展解析器以關聯在作用域中宣告的每個局部變數的唯一索引。當解析變數存取時,查找變數所在的作用域及其索引並儲存它。在直譯器中,使用它透過索引快速存取變數,而不是使用地圖。