陳述式與狀態
我的一生,我的心一直渴望著一個我無法命名的東西。安德烈·布勒東,《瘋狂的愛》
我們目前為止的直譯器感覺比較像是在計算機上按按鈕,而不是在編寫真正的程式語言。對我來說,「程式設計」意味著從較小的部分構建一個系統。我們還不能這樣做,因為我們沒有辦法將名稱與某些資料或函式綁定。如果沒有方法引用這些部分,我們就無法組合軟體。
為了支援綁定,我們的直譯器需要內部狀態。當你在程式的開頭定義一個變數,並在結尾使用它時,直譯器必須在期間保留該變數的值。因此,在本章中,我們將為我們的直譯器一個不僅可以處理,還可以記住的頭腦。
狀態和陳述式是密不可分的。由於陳述式根據定義不會評估為值,它們需要做其他的事情才能有用。那件其他的事情被稱為副作用。它可能意味著產生用戶可見的輸出,或修改稍後可以檢測到的直譯器中的某些狀態。後者使它們非常適合定義變數或其他具名實體。
在本章中,我們將完成所有這些。我們將定義產生輸出的陳述式(print)和建立狀態的陳述式(var)。我們將新增運算式來存取和賦值給變數。最後,我們將新增區塊和本機作用域。這是在一章中要塞入的很多內容,但我們會一次一點地咀嚼它。
8 . 1陳述式
我們先擴展 Lox 的語法,加入陳述式。它們與運算式沒有太大的不同。我們先從兩種最簡單的開始
-
運算式陳述式 讓你可以在預期使用陳述式的地方放置運算式。它們的存在是為了評估具有副作用的運算式。你可能沒有注意到它們,但你一直在 C、Java 和其他語言中使用它們。任何時候你看到函式或方法呼叫後跟一個
;,你看到的都是運算式陳述式。 -
print陳述式 評估一個運算式並將結果顯示給使用者。我承認將列印直接放入語言中而不是將其作為函式庫函式是很奇怪的。這樣做是為了順應我們正在一章一章地建立這個直譯器,並且希望在它全部完成之前就能夠玩它。要使列印成為函式庫函式,我們必須等到我們擁有所有定義和呼叫函式的機制之後,我們才能見證任何副作用。
新語法意味著新的文法規則。在本章中,我們終於獲得了剖析整個 Lox 腳本的能力。由於 Lox 是一種命令式、動態型別的語言,腳本的「最上層」只是一個陳述式列表。新規則是
program → statement* EOF ; statement → exprStmt | printStmt ; exprStmt → expression ";" ; printStmt → "print" expression ";" ;
第一個規則現在是 program,它是文法的起點,代表一個完整的 Lox 腳本或 REPL 輸入。程式是一個陳述式列表,後跟特殊的「檔案結尾」符號。強制結束符號可確保剖析器消耗整個輸入,並且不會在腳本結尾靜默忽略錯誤的未消耗符號。
現在,statement 只有兩種情況,對應我們已描述的兩種陳述式。我們稍後會在本章和後續章節中填寫更多。下一步是將此文法轉換為我們可以儲存在記憶體中的東西—語法樹。
8 . 1 . 1陳述式語法樹
文法中沒有任何地方同時允許運算式和陳述式。例如,+ 的運算元始終是運算式,而不是陳述式。while 迴圈的主體始終是陳述式。
由於這兩種語法是不相交的,我們不需要它們都繼承自的單一基底類別。將運算式和陳述式分成不同的類別階層,可讓 Java 編譯器幫助我們找到愚蠢的錯誤,例如將陳述式傳遞給需要運算式的 Java 方法。
這意味著陳述式有一個新的基底類別。就像我們的前輩所做的那樣,我們將使用神秘的名稱「Stmt」。有了偉大的先見之明,我已經設計了我們的小型 AST 元程式設計腳本,以預期這一點。這就是為什麼我們將「Expr」作為參數傳遞給 defineAst() 的原因。現在,我們新增另一個呼叫來定義 Stmt 和其子類別。
"Unary : Token operator, Expr right"
));
在 main() 中
defineAst(outputDir, "Stmt", Arrays.asList(
"Expression : Expr expression",
"Print : Expr expression"
));
}
執行 AST 產生器腳本,並查看產生的「Stmt.java」檔案,其中包含我們需要的運算式和 print 陳述式的語法樹類別。不要忘記將檔案新增到你的 IDE 專案或 makefile 或任何東西中。
8 . 1 . 2剖析陳述式
剖析器中剖析並回傳單一運算式的 parse() 方法是一個臨時性的權宜之計,目的是使上一章順利運作。現在我們的文法具有正確的起始規則 program,我們可以將 parse() 變成真正的東西。
方法 parse()
取代 7 行
List<Stmt> parse() { List<Stmt> statements = new ArrayList<>(); while (!isAtEnd()) { statements.add(statement()); } return statements; }
這會剖析一系列陳述式,只要它能找到,直到它到達輸入結尾。這是將 program 規則直接轉換為遞迴下降風格的過程。由於我們現在使用 ArrayList,我們還必須向 Java 冗長的神明祈禱。
package com.craftinginterpreters.lox;
import java.util.ArrayList;
import java.util.List;
程式是一個陳述式列表,我們使用此方法剖析其中一個陳述式
在 expression() 之後新增
private Stmt statement() { if (match(PRINT)) return printStatement(); return expressionStatement(); }
有點簡陋,但我們稍後會填寫更多陳述式類型。我們透過查看目前的符號來判斷符合哪個特定的陳述式規則。print 符號表示它顯然是 print 陳述式。
如果下一個符號看起來不像任何已知的陳述式類型,我們會假設它必須是運算式陳述式。這是剖析陳述式時的典型最終回溯情況,因為很難從其第一個符號主動識別運算式。
每種陳述式類型都有自己的方法。首先是 print
在 statement() 之後新增
private Stmt printStatement() { Expr value = expression(); consume(SEMICOLON, "Expect ';' after value."); return new Stmt.Print(value); }
由於我們已經比對並消耗了 print 符號本身,因此我們不需要在此處執行此操作。我們剖析後續的運算式,消耗終止分號,並發出語法樹。
如果我們沒有比對到 print 陳述式,我們必須有其中一個
在 printStatement() 之後新增
private Stmt expressionStatement() { Expr expr = expression(); consume(SEMICOLON, "Expect ';' after expression."); return new Stmt.Expression(expr); }
與先前的方法類似,我們剖析一個運算式,後跟一個分號。我們將該 Expr 包裝在正確類型的 Stmt 中並回傳它。
8 . 1 . 3執行陳述式
我們正在微觀地執行前幾章,逐步完成前端的工作。我們的剖析器現在可以產生陳述式語法樹,因此下一步也是最後一步是直譯它們。就像在運算式中一樣,我們使用 Visitor 模式,但我們有一個新的訪客介面 Stmt.Visitor 要實作,因為陳述式有自己的基底類別。
我們將其新增至 Interpreter 實作的介面列表中。
取代 1 行
class Interpreter implements Expr.Visitor<Object>, Stmt.Visitor<Void> {
void interpret(Expr expression) {
與運算式不同,陳述式不會產生任何值,因此 visit 方法的回傳型別為 Void,而不是 Object。我們有兩種陳述式類型,我們需要每種陳述式類型一個 visit 方法。最簡單的是運算式陳述式。
在 evaluate() 之後新增
@Override public Void visitExpressionStmt(Stmt.Expression stmt) { evaluate(stmt.expression); return null; }
我們使用現有的 evaluate() 方法評估內部運算式,並捨棄該值。然後我們回傳 null。Java 要求這樣做才能滿足特殊的大寫 Void 回傳型別。很奇怪,但你能做什麼呢?
print 陳述式的 visit 方法並沒有太大的不同。
在 visitExpressionStmt() 之後新增
@Override public Void visitPrintStmt(Stmt.Print stmt) { Object value = evaluate(stmt.expression); System.out.println(stringify(value)); return null; }
在捨棄運算式的值之前,我們使用我們在上一章中介紹的 stringify() 方法將其轉換為字串,然後將其轉儲到 stdout。
我們的直譯器現在可以訪問陳述式,但我們還有一些工作要做,才能將它們提供給它。首先,修改 Interpreter 類別中舊的 interpret() 方法以接受陳述式列表—換句話說,就是一個程式。
方法 interpret()
取代 8 行
void interpret(List<Stmt> statements) { try { for (Stmt statement : statements) { execute(statement); } } catch (RuntimeError error) { Lox.runtimeError(error); } }
這取代了舊的接收單一運算式的程式碼。新程式碼依賴這個小小的輔助方法
在 evaluate() 之後新增
private void execute(Stmt stmt) { stmt.accept(this); }
這就像是我們針對表達式所擁有的 evaluate() 方法的對應陳述。既然我們現在處理的是列表,我們需要讓 Java 知道。
package com.craftinginterpreters.lox;
import java.util.List;
class Interpreter implements Expr.Visitor<Object>,
主要的 Lox 類別仍然試圖解析單一表達式並將其傳遞給直譯器。我們像這樣修正解析行
Parser parser = new Parser(tokens);
在 run() 中
取代 1 行
List<Stmt> statements = parser.parse();
// Stop if there was a syntax error.
然後用這個替換對直譯器的呼叫
if (hadError) return;
在 run() 中
取代 1 行
interpreter.interpret(statements);
}
基本上只是將新的語法接通。好了,啟動直譯器並試試看。在這一點上,值得在文字檔案中草擬一個小的 Lox 程式來作為腳本執行。類似這樣
print "one"; print true; print 2 + 1;
它看起來幾乎像一個真正的程式!請注意,REPL 現在也需要您輸入完整的陳述,而不是簡單的表達式。別忘了您的分號。
8 . 2全域變數
現在我們有了陳述,我們可以開始處理狀態。在我們深入了解詞法作用域的所有複雜性之前,我們先從最簡單的變數開始—全域變數。我們需要兩個新的建構。
-
變數宣告陳述會將一個新的變數引入世界。
var beverage = "espresso";
這會建立一個新的綁定,將名稱(此處為 “beverage”)與值(此處為字串
"espresso")建立關聯。 -
一旦完成,變數表達式就會存取該綁定。當識別符號 “beverage” 作為表達式使用時,它會查找綁定到該名稱的值並傳回它。
print beverage; // "espresso".
稍後,我們會新增賦值和區塊作用域,但這足以讓我們繼續前進。
8 . 2 . 1變數語法
和以前一樣,我們將從前到後逐步完成實作,從語法開始。變數宣告是陳述,但它們與其他陳述不同,我們將把陳述語法分成兩部分來處理它們。這是因為語法限制了某些種類的陳述允許出現的位置。
控制流程陳述中的子句—想想 if 陳述的 then 和 else 分支或 while 的主體—每個都是單一陳述。但是該陳述不允許是宣告名稱的陳述。這樣可以
if (monday) print "Ugh, already?";
但是這樣不行
if (monday) var beverage = "espresso";
我們可以允許後者,但這會令人困惑。beverage 變數的作用域是什麼?它在 if 陳述之後是否仍然存在?如果是,那麼在星期一以外的日子它的值是什麼?該變數在那些日子是否存在?
像這樣的程式碼很奇怪,所以 C、Java 和其他類似的程式碼都禁止這樣做。這就好像陳述有兩個層次的「優先權」。某些允許陳述的地方—例如在區塊內或最上層—允許任何種類的陳述,包括宣告。其他則只允許不宣告名稱的「較高」優先權陳述。
為了適應這種區別,我們為宣告名稱的陳述種類新增另一個規則。
program → declaration* EOF ; declaration → varDecl | statement ; statement → exprStmt | printStmt ;
宣告陳述放在新的 declaration 規則下。目前,它只有變數,但稍後將包括函式和類別。任何允許宣告的地方也允許非宣告陳述,因此 declaration 規則會依序執行至 statement。顯然,您可以在腳本的最上層宣告內容,因此 program 會路由至新的規則。
宣告變數的規則看起來像這樣
varDecl → "var" IDENTIFIER ( "=" expression )? ";" ;
與大多數陳述一樣,它以開頭的關鍵字開始。在這個範例中,是 var。然後是正在宣告的變數名稱的識別符號權杖,接著是一個可選的初始化表達式。最後,我們用分號來總結。
若要存取變數,我們定義一種新的主要表達式。
primary → "true" | "false" | "nil" | NUMBER | STRING | "(" expression ")" | IDENTIFIER ;
IDENTIFIER 子句會比對單一識別符號權杖,該權杖被理解為正在存取的變數名稱。
這些新的語法規則會獲得其對應的語法樹。在 AST 產生器中,我們為變數宣告新增一個新的陳述節點。
"Expression : Expr expression",
"Print : Expr expression",
在 main() 中
在上一行新增 “,”
"Var : Token name, Expr initializer"
));
它會儲存名稱權杖,以便我們知道它宣告的是什麼,以及初始化表達式。(如果沒有初始化程式,則該欄位為 null。)
然後我們新增一個用於存取變數的表達式節點。
"Literal : Object value",
"Unary : Token operator, Expr right",
在 main() 中
在上一行新增 “,”
"Variable : Token name"
));
它只是變數名稱的權杖的包裝函式。就是這樣。一如既往,別忘了執行 AST 產生器腳本,以便您取得更新的「Expr.java」和「Stmt.java」檔案。
8 . 2 . 2解析變數
在我們解析變數陳述之前,我們需要移動一些程式碼,為語法中的新 declaration 規則騰出空間。程式的最上層現在是宣告的清單,因此剖析器的進入點方法會變更。
List<Stmt> parse() {
List<Stmt> statements = new ArrayList<>();
while (!isAtEnd()) {
在 parse() 中
取代 1 行
statements.add(declaration());
}
return statements;
}
這會呼叫這個新方法
在 expression() 之後新增
private Stmt declaration() { try { if (match(VAR)) return varDeclaration(); return statement(); } catch (ParseError error) { synchronize(); return null; } }
嘿,您還記得在較早的章節中,我們建立基礎架構來進行錯誤恢復嗎?我們終於準備好連接它了。
當剖析器進入恐慌模式時,這個 declaration() 方法是我們在剖析區塊或腳本中的一系列陳述時重複呼叫的方法,因此它是同步的正確位置。這個方法的整個主體都包裝在 try 區塊中,以捕捉剖析器開始錯誤恢復時擲出的例外狀況。這會使其回到嘗試剖析下一個陳述或宣告的開頭。
真正的剖析發生在 try 區塊內。首先,它會檢查我們是否處於變數宣告的位置,方法是查找開頭的 var 關鍵字。如果不是,它會依序執行至現有的 statement() 方法,該方法會剖析 print 和表達式陳述。
還記得如果沒有其他陳述符合,statement() 如何嘗試剖析表達式陳述嗎?如果它無法在目前權杖剖析表達式,expression() 會報告語法錯誤嗎?這個呼叫鏈可確保如果未剖析有效的宣告或陳述,我們會報告錯誤。
當剖析器符合 var 權杖時,它會分支到
在 printStatement() 之後新增
private Stmt varDeclaration() { Token name = consume(IDENTIFIER, "Expect variable name."); Expr initializer = null; if (match(EQUAL)) { initializer = expression(); } consume(SEMICOLON, "Expect ';' after variable declaration."); return new Stmt.Var(name, initializer); }
與往常一樣,遞迴下降程式碼會遵循語法規則。剖析器已經符合 var 權杖,因此接下來需要並使用變數名稱的識別符號權杖。
然後,如果它看到 = 權杖,它就知道存在初始化表達式並剖析它。否則,它會將初始化程式保留為 null。最後,它會在陳述結尾使用必要的分號。所有這些都包裝在 Stmt.Var 語法樹節點中,我們就很順利了。
剖析變數表達式甚至更容易。在 primary() 中,我們尋找識別符號權杖。
return new Expr.Literal(previous().literal);
}
在 primary() 中
if (match(IDENTIFIER)) {
return new Expr.Variable(previous());
}
if (match(LEFT_PAREN)) {
這為我們提供了宣告和使用變數的可運作前端。剩下的就是將其饋入直譯器。在我們開始之前,我們需要討論變數在記憶體中的位置。
8 . 3環境
將變數與值建立關聯的綁定需要儲存在某個地方。自從 Lisp 的人們發明括號以來,這種資料結構就被稱為環境。
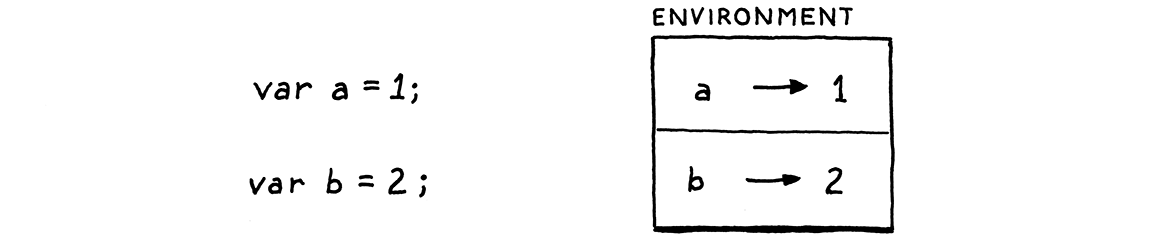
您可以將其視為一個對應,其中鍵是變數名稱,而值是變數的值。事實上,這就是我們在 Java 中實作它的方式。我們可以將該對應和管理它的程式碼塞入 Interpreter 中,但由於它形成一個清楚描述的概念,我們將其提取到它自己的類別中。
啟動新檔案並新增
建立新檔案
package com.craftinginterpreters.lox; import java.util.HashMap; import java.util.Map; class Environment { private final Map<String, Object> values = new HashMap<>(); }
其中有一個 Java Map 用於儲存綁定。它使用裸字串作為鍵,而不是權杖。權杖表示來源文字中特定位置的程式碼單位,但在查找變數時,所有具有相同名稱的識別符號權杖都應參照相同的變數(暫時忽略作用域)。使用原始字串可確保所有這些權杖都參照相同的對應鍵。
我們需要支援兩個操作。首先,變數定義會將新名稱綁定到值。
在類別 Environment 中
void define(String name, Object value) { values.put(name, value); }
這並不是什麼難事,但我們已經做出一個有趣的語意選擇。當我們將鍵新增到對應時,我們不會檢查它是否已存在。這表示此程式可以運作
var a = "before"; print a; // "before". var a = "after"; print a; // "after".
變數陳述不僅會定義新的變數,還可以用於重新定義現有的變數。我們可以選擇將此設為錯誤。使用者可能無意重新定義現有的變數。(如果他們是故意的,他們可能會使用賦值,而不是 var。)將重新定義設為錯誤有助於他們找到該錯誤。
但是,這樣做與 REPL 的互動效果不佳。在 REPL 會話的中間,不必在腦海中追蹤您已定義的變數會很好。我們可以允許在 REPL 中重新定義,但不允許在腳本中重新定義,但是這樣一來,使用者就必須學習兩組規則,並且從一種形式複製並貼到另一種形式的程式碼可能無法運作。
因此,為了保持兩種模式一致,我們將允許它—至少對於全域變數是如此。一旦變數存在,我們就需要一種方法來查找它。
class Environment {
private final Map<String, Object> values = new HashMap<>();
在類別 Environment 中
Object get(Token name) { if (values.containsKey(name.lexeme)) { return values.get(name.lexeme); } throw new RuntimeError(name, "Undefined variable '" + name.lexeme + "'."); }
void define(String name, Object value) {
這在語意上更有趣一點。如果找到變數,它只會傳回綁定到它的值。但是,如果沒有找到怎麼辦?同樣,我們有選擇
-
使其成為語法錯誤。
-
使其成為執行階段錯誤。
-
允許它並傳回一些預設值,例如
nil。
Lox 語言相當寬鬆,但最後一個選項對我來說有點過於寬鬆了。將其設為語法錯誤—編譯時錯誤—似乎是個明智的選擇。使用未定義的變數是個錯誤,而且你越早偵測到錯誤,就越好。
問題在於使用變數和參照變數並不相同。如果程式碼片段被包在函式中,你可以在程式碼片段中參照變數,而無需立即對其求值。如果我們在變數宣告之前就提到該變數時將其設為靜態錯誤,那麼定義遞迴函式就會變得更加困難。
我們可以通過在檢查函式主體之前宣告函式自身的名稱來處理單一遞迴—呼叫自身的函式—。但這對於相互呼叫的相互遞迴程序沒有幫助。考慮以下情況:
fun isOdd(n) { if (n == 0) return false; return isEven(n - 1); } fun isEven(n) { if (n == 0) return true; return isOdd(n - 1); }
當我們查看呼叫 isEven() 的 isOdd() 函式主體時,isEven() 函式尚未定義。如果我們交換這兩個函式的順序,那麼當我們查看 isEven() 的主體時,isOdd() 函式就尚未定義。
由於將其設為靜態錯誤會使遞迴宣告過於困難,我們將錯誤延遲到執行階段。在變數定義之前參照它是可以的,只要你沒有求值該參照即可。這可以讓判斷偶數和奇數的程式運作,但你會在以下情況中收到執行階段錯誤:
print a; var a = "too late!";
如同在表達式求值程式碼中的型別錯誤一樣,我們通過拋出例外狀況來回報執行階段錯誤。例外狀況包含變數的符號,因此我們可以告訴使用者他們的程式碼在哪裡出錯。
8 . 3 . 1解譯全域變數
Interpreter 類別會取得新 Environment 類別的實例。
class Interpreter implements Expr.Visitor<Object>,
Stmt.Visitor<Void> {
在 Interpreter 類別中
private Environment environment = new Environment();
void interpret(List<Stmt> statements) {
我們將其作為欄位直接儲存在 Interpreter 中,以便在解譯器仍在執行時將變數保留在記憶體中。
我們有兩個新的語法樹,因此有兩個新的訪問方法。第一個用於宣告語句。
在 visitPrintStmt() 之後新增
@Override public Void visitVarStmt(Stmt.Var stmt) { Object value = null; if (stmt.initializer != null) { value = evaluate(stmt.initializer); } environment.define(stmt.name.lexeme, value); return null; }
如果變數有初始化值,我們會對其求值。如果沒有,我們還有另一個選擇要做。我們可以通過要求初始化值在剖析器中將其設為語法錯誤。但是,大多數語言都不是這樣,因此在 Lox 中這樣做感覺有點苛刻。
我們可以將其設為執行階段錯誤。我們會讓你定義未初始化的變數,但是如果你在賦值之前存取它,就會發生執行階段錯誤。這不是個壞主意,但是大多數動態型別語言都不會這樣做。相反,我們會讓它保持簡單,並說 Lox 會將變數設為 nil,如果它沒有明確初始化。
var a; print a; // "nil".
因此,如果沒有初始化值,我們會將該值設為 null,這是 Lox 的 nil 值的 Java 表示法。然後我們告訴環境將變數繫結到該值。
接下來,我們對變數表達式求值。
在 visitUnaryExpr() 之後新增
@Override public Object visitVariableExpr(Expr.Variable expr) { return environment.get(expr.name); }
這只會轉發到環境,而環境會進行繁重的工作以確保變數已定義。這樣,我們就可以使基本的變數運作。試試這個
var a = 1; var b = 2; print a + b;
我們還不能重複使用程式碼,但我們可以開始建立重複使用資料的程式。
8 . 4賦值
有可能建立一個具有變數但不允許你重新賦值—或修改—它們的語言。Haskell 就是一個例子。SML 僅支援可修改的參照和陣列—變數無法重新賦值。Rust 要求使用 mut 修飾符來啟用賦值,從而引導你遠離修改。
修改變數是一種副作用,顧名思義,一些語言使用者認為副作用是不乾淨或不優雅的。程式碼應該是產生值的純數學—像神聖創造行為一樣,是晶瑩剔透、永恆不變的值—而不是一些將資料塊塑造成形、一次一聲命令式咕噥的骯髒自動機。
Lox 並不那麼嚴苛。Lox 是一種命令式語言,而修改是不可避免的。新增對賦值的支援不需要太多工作。全域變數已經支援重新定義,因此大部分機制現在都在這裡了。主要來說,我們缺少明確的賦值標記法。
8 . 4 . 1賦值語法
這個小的 = 語法比看起來更複雜。與大多數衍生自 C 的語言一樣,賦值是一個表達式而不是語句。與 C 中一樣,它是優先順序最低的表達式形式。這表示規則會插入到 expression 和 equality(下一個優先順序最低的表達式)之間。
expression → assignment ; assignment → IDENTIFIER "=" assignment | equality ;
這表示 assignment 要嘛是一個識別碼,後接一個 = 和一個值的表達式,要嘛是一個 equality(以及任何其他)表達式。稍後,當我們在物件上新增屬性 setter 時,assignment 會變得更加複雜,例如
instance.field = "value";
簡單的部分是新增新的語法樹節點。
defineAst(outputDir, "Expr", Arrays.asList(
在 main() 中
"Assign : Token name, Expr value",
"Binary : Expr left, Token operator, Expr right",
它具有要賦值的變數的符號,以及新值的表達式。在執行 AstGenerator 取得新的 Expr.Assign 類別後,請將剖析器現有的 expression() 方法主體替換為符合更新後的規則。
private Expr expression() {
在 expression() 中
取代 1 行
return assignment();
}
這裡是它變得棘手的地方。單符號先行遞迴下降剖析器無法看到足夠遠,以判斷它是否在剖析賦值,直到它經過左側並偶然碰到 = 之後。你可能會想知道為什麼它甚至需要這樣做。畢竟,我們不會知道我們是否在剖析 + 表達式,直到我們完成剖析左運算元之後。
不同之處在於,賦值的左側不是求值為值的表達式。它是一種偽表達式,求值為你可以賦值的「事物」。考慮以下情況:
var a = "before"; a = "value";
在第二行中,我們不會求值 a(這會傳回字串「before」)。我們找出變數 a 指向哪個變數,以便我們知道在哪裡儲存右側表達式的值。這些兩個建構的經典術語是 l-value 和 r-value。我們到目前為止看到的所有產生值的表達式都是 r-value。l-value「求值」為你可以賦值的儲存位置。
我們希望語法樹反映出 l-value 並不像一般表達式那樣求值。這就是為什麼 Expr.Assign 節點的左側具有 Token,而不是 Expr。問題在於,剖析器直到遇到 = 時才知道它在剖析 l-value。在複雜的 l-value 中,這可能發生在許多符號之後。
makeList().head.next = node;
我們只有一個符號的先行,那麼我們該怎麼辦?我們使用一個小技巧,它看起來像這樣
在 expressionStatement() 之後新增
private Expr assignment() { Expr expr = equality(); if (match(EQUAL)) { Token equals = previous(); Expr value = assignment(); if (expr instanceof Expr.Variable) { Token name = ((Expr.Variable)expr).name; return new Expr.Assign(name, value); } error(equals, "Invalid assignment target."); } return expr; }
剖析賦值表達式的大部分程式碼看起來與其他二元運算子(如 +)相似。我們剖析左側,它可以是任何優先順序較高的表達式。如果我們找到一個 =,我們會剖析右側,然後將它們全部包裝在賦值表達式樹節點中。
與二元運算子的略微不同之處在於,我們不會循環建立相同運算子的序列。由於賦值是右結合的,我們改為遞迴呼叫 assignment() 以剖析右側。
技巧在於,就在我們建立賦值表達式節點之前,我們會查看左側表達式,並找出它是哪種類型的賦值目標。我們將 r-value 表達式節點轉換為 l-value 表示法。
這種轉換之所以有效,是因為事實證明,每個有效的賦值目標恰好也是作為正常表達式的有效語法。考慮一個複雜的欄位賦值,例如
newPoint(x + 2, 0).y = 3;
該賦值的左側也可能作為一個有效的表達式。
newPoint(x + 2, 0).y;
第一個範例設定欄位,第二個範例取得它。
這表示我們可以先將左側解析為好像它是一個表達式,然後在事後產生一個語法樹,將其轉換為賦值目標。如果左側的表達式不是一個有效的賦值目標,我們將以語法錯誤失敗。這確保我們在像這樣的程式碼上回報錯誤
a + b = c;
目前,唯一有效的目標是一個簡單的變數表達式,但我們稍後會新增欄位。這個技巧的最終結果是一個賦值表達式樹節點,它知道它正在賦值給什麼,並且有一個表示被賦予值的表達式子樹。所有這些都只需要一個前瞻符號,而不需要回溯。
8 . 4 . 2賦值語義
我們有一個新的語法樹節點,所以我們的直譯器獲得一個新的訪問方法。
在 visitVarStmt() 之後新增
@Override public Object visitAssignExpr(Expr.Assign expr) { Object value = evaluate(expr.value); environment.assign(expr.name, value); return value; }
由於顯而易見的原因,它與變數宣告類似。它計算右側以取得值,然後將其儲存在具名的變數中。它不是在 Environment 上使用 define(),而是呼叫這個新的方法
在 get() 之後新增
void assign(Token name, Object value) { if (values.containsKey(name.lexeme)) { values.put(name.lexeme, value); return; } throw new RuntimeError(name, "Undefined variable '" + name.lexeme + "'."); }
賦值和定義之間的關鍵區別在於,賦值不允許建立一個新的變數。就我們的實作而言,這表示如果環境的變數映射中已不存在該鍵,則會發生執行階段錯誤。
visit() 方法最後做的事情是傳回被賦予的值。這是因為賦值是一個可以嵌套在其他表達式中的表達式,就像這樣
var a = 1; print a = 2; // "2".
我們的直譯器現在可以建立、讀取和修改變數。它與早期的 BASIC 一樣複雜。全域變數很簡單,但當任何兩個程式碼區塊都可能意外地踩到彼此的狀態時,編寫大型程式會很乏味。我們想要區域變數,這表示該是範圍的時候了。
8 . 5範圍
範圍定義一個名稱映射到特定實體的區域。多個範圍允許相同的名稱在不同的上下文中引用不同的事物。在我的房子裡,「Bob」通常指的是我。但也許在你的城鎮裡,你認識另一個 Bob。相同的名稱,但基於你說出它的地點而不同的傢伙。
詞法範圍(或較少聽到的靜態範圍)是一種特定的範圍樣式,程式本身的文字顯示範圍的開始和結束位置。在 Lox 中,如同大多數現代語言一樣,變數是詞法範圍的。當你看到一個使用某些變數的表達式時,你可以僅透過靜態讀取程式碼來找出它指的是哪個變數宣告。
例如
{
var a = "first";
print a; // "first".
}
{
var a = "second";
print a; // "second".
}
在這裡,我們有兩個區塊,每個區塊中都宣告了一個變數 a。你和我可以僅從觀察程式碼中得知,第一個 print 陳述式中 a 的使用指的是第一個 a,而第二個指的是第二個。

這與動態範圍形成對比,在動態範圍中,你必須執行程式碼才能知道名稱指的是什麼。Lox 沒有動態範圍的變數,但是物件上的方法和欄位是動態範圍的。
class Saxophone { play() { print "Careless Whisper"; } } class GolfClub { play() { print "Fore!"; } } fun playIt(thing) { thing.play(); }
當 playIt() 呼叫 thing.play() 時,我們不知道我們即將聽到「Careless Whisper」還是「Fore!」。這取決於你傳遞給該函式的樂器是薩克斯風還是高爾夫球桿,而我們在執行階段之前都不知道。
範圍和環境是近親。前者是理論概念,後者是實現它的機制。當我們的直譯器逐步執行程式碼時,會影響範圍的語法樹節點將會變更環境。在像 Lox 這樣類似 C 的語法中,範圍由大括號括起來的區塊控制。(這就是為什麼我們稱之為區塊範圍。)
{
var a = "in block";
}
print a; // Error! No more "a".
區塊的開始引入新的區域範圍,當執行通過結尾的 } 時,該範圍結束。在區塊內部宣告的任何變數都會消失。
8 . 5 . 1巢狀和遮蔽
實現區塊範圍的第一步可能如下所示
-
當我們訪問區塊內的每個陳述式時,追蹤任何宣告的變數。
-
在執行最後一個陳述式之後,告訴環境刪除所有這些變數。
這對於先前的範例有效。但請記住,區域範圍的一個動機是封裝—程式碼的一個角落中的程式碼區塊不應干擾其他區塊。看看這個
// How loud? var volume = 11; // Silence. volume = 0; // Calculate size of 3x4x5 cuboid. { var volume = 3 * 4 * 5; print volume; }
看看我們使用 volume 的區域宣告計算長方體體積的區塊。在區塊結束後,直譯器將刪除全域 volume 變數。那不對。當我們退出區塊時,我們應該刪除在區塊內宣告的任何變數,但如果存在一個在區塊外宣告的同名變數,那是一個不同的變數。不應碰觸到它。
當區域變數與封閉範圍中的變數具有相同的名稱時,它會遮蔽外部變數。區塊內的程式碼再也看不到它了—它隱藏在內部變數的「陰影」中—但它仍然在那裡。
當我們進入新的區塊範圍時,我們需要保留外部範圍中定義的變數,以便它們在我們退出內部區塊時仍然存在。我們透過為每個區塊定義一個僅包含該範圍中定義的變數的全新環境來做到這一點。當我們退出區塊時,我們會捨棄其環境並還原先前的環境。
我們還需要處理沒有被遮蔽的封閉變數。
var global = "outside"; { var local = "inside"; print global + local; }
在這裡,global 存在於外部全域環境中,而 local 定義在區塊的環境中。在該 print 陳述式中,這兩個變數都在範圍內。為了找到它們,直譯器不僅必須搜尋當前最內部的環境,還必須搜尋任何封閉的環境。
我們透過連結環境來實現這一點。每個環境都有一個對其直接封閉範圍的環境的參考。當我們查找變數時,我們會從最內部到最外部走過該鏈,直到找到變數為止。從內部範圍開始是我們使區域變數遮蔽外部變數的方式。
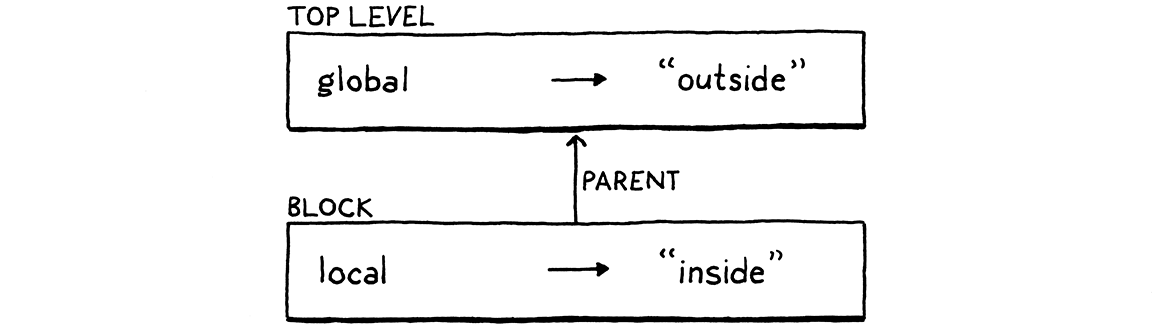
在將區塊語法新增到文法之前,我們將加強我們的 Environment 類別,以支援這種巢狀結構。首先,我們給每個環境一個對其封閉環境的參考。
class Environment {
在類別 Environment 中
final Environment enclosing;
private final Map<String, Object> values = new HashMap<>();
此欄位需要初始化,因此我們新增幾個建構子。
在類別 Environment 中
Environment() { enclosing = null; } Environment(Environment enclosing) { this.enclosing = enclosing; }
無引數建構子用於結束鏈的全域範圍的環境。另一個建構子建立一個嵌套在給定的外部範圍內的新區域範圍。
我們不必碰觸 define() 方法—新的變數總是宣告在當前最內部的範圍中。但是變數查找和賦值使用現有的變數,它們需要走過鏈才能找到它們。首先,查找
return values.get(name.lexeme);
}
在 get() 中
if (enclosing != null) return enclosing.get(name);
throw new RuntimeError(name,
"Undefined variable '" + name.lexeme + "'.");
如果在此環境中找不到變數,我們就嘗試封閉環境。這反過來也會做同樣的事情,遞迴地,因此最終將走完整個鏈。如果我們到達沒有封閉環境的環境,並且仍然找不到變數,那麼我們就會放棄並像以前一樣報告錯誤。
賦值的工作方式相同。
values.put(name.lexeme, value);
return;
}
在 assign() 中
if (enclosing != null) { enclosing.assign(name, value); return; }
throw new RuntimeError(name,
同樣,如果此環境中沒有變數,它會遞迴地檢查外部環境。
8 . 5 . 2區塊語法和語義
現在環境可以嵌套了,我們準備好將區塊新增到語言中。看文法
statement → exprStmt | printStmt | block ; block → "{" declaration* "}" ;
區塊是由大括號包圍的一系列(可能為空的)陳述式或宣告。區塊本身是一個陳述式,並且可以出現在允許陳述式的任何位置。語法樹節點如下所示
defineAst(outputDir, "Stmt", Arrays.asList(
在 main() 中
"Block : List<Stmt> statements",
"Expression : Expr expression",
它包含區塊內的陳述式列表。解析很簡單。與其他陳述式一樣,我們透過其前導符號—在本例中為 { 來偵測區塊的開頭。在 statement() 方法中,我們新增
if (match(PRINT)) return printStatement();
在 statement() 中
if (match(LEFT_BRACE)) return new Stmt.Block(block());
return expressionStatement();
所有真正的工作都在這裡完成
在 expressionStatement() 之後新增
private List<Stmt> block() { List<Stmt> statements = new ArrayList<>(); while (!check(RIGHT_BRACE) && !isAtEnd()) { statements.add(declaration()); } consume(RIGHT_BRACE, "Expect '}' after block."); return statements; }
我們建立一個空列表,然後解析陳述式並將它們新增到列表中,直到我們到達區塊的結尾,並以結尾的 } 作為標記。請注意,迴圈也有針對 isAtEnd() 的明確檢查。我們必須小心避免無限迴圈,即使在解析無效的程式碼時也是如此。如果使用者忘記了結尾的 },解析器需要避免陷入困境。
這就是語法部分。對於語義,我們將另一個訪問方法新增到 Interpreter。
在 execute() 之後新增
@Override public Void visitBlockStmt(Stmt.Block stmt) { executeBlock(stmt.statements, new Environment(environment)); return null; }
要執行區塊,我們會為區塊的範圍建立一個新的環境,並將其傳遞給這個其他方法
在 execute() 之後新增
void executeBlock(List<Stmt> statements, Environment environment) { Environment previous = this.environment; try { this.environment = environment; for (Stmt statement : statements) { execute(statement); } } finally { this.environment = previous; } }
這個新方法在給定的環境的上下文中執行陳述式列表。到目前為止,Interpreter 中的 environment 欄位總是指向相同的環境—全域環境。現在,該欄位表示當前環境。這是對應於包含要執行的程式碼的最內部範圍的環境。
為了在給定的作用域內執行程式碼,此方法會更新直譯器的 environment 欄位,走訪所有陳述式,然後還原先前的值。如同 Java 中良好的實踐,它會使用 finally 子句還原先前的環境。如此一來,即使拋出例外,也能確保環境被還原。
令人驚訝的是,這就是我們為了完全支援區域變數、巢狀結構和遮蔽所需要做的全部工作。請試試看。
var a = "global a"; var b = "global b"; var c = "global c"; { var a = "outer a"; var b = "outer b"; { var a = "inner a"; print a; print b; print c; } print a; print b; print c; } print a; print b; print c;
我們的小型直譯器現在可以記住東西了。我們正逐漸接近一個類似完整功能的程式語言。
挑戰
-
REPL 不再支援輸入單一表達式並自動列印其結果值。這很麻煩。為 REPL 新增支援,讓使用者可以輸入陳述式和表達式。如果他們輸入陳述式,則執行它。如果他們輸入表達式,則評估它並顯示結果值。
-
也許您希望 Lox 在變數初始化方面更明確一些。不要隱式地將變數初始化為
nil,而是讓存取尚未初始化或賦值的變數成為執行階段錯誤,如下所示:// No initializers. var a; var b; a = "assigned"; print a; // OK, was assigned first. print b; // Error!
-
以下程式碼會做什麼?
var a = 1; { var a = a + 2; print a; }
您預期它會做什麼?它是否符合您認為它應該做的事情?您熟悉的其他語言中的類似程式碼會做什麼?您認為使用者會預期它會做什麼?
設計筆記:隱式變數宣告
Lox 對於宣告新變數和賦值給現有變數有不同的語法。某些語言將這兩者合併為僅賦值語法。賦值給不存在的變數會自動使其產生。這稱為隱式變數宣告,存在於 Python、Ruby 和 CoffeeScript 等語言中。JavaScript 有明確的語法來宣告變數,但也可以在賦值時建立新變數。Visual Basic 有一個選項可以啟用或停用隱式變數。
當相同的語法可以賦值或建立變數時,每種語言都必須決定當使用者意圖不明確時會發生什麼。特別是,每種語言都必須選擇隱式宣告如何與遮蔽互動,以及隱式宣告的變數會進入哪個作用域。
-
在 Python 中,賦值始終會在目前函數的作用域中建立變數,即使在函數外部宣告了具有相同名稱的變數也是如此。
-
Ruby 透過對區域和全域變數使用不同的命名規則來避免一些歧義。但是,Ruby 中的區塊(更像是閉包,而不是 C 中的「區塊」)有自己的作用域,所以它仍然存在這個問題。如果存在具有相同名稱的變數,則 Ruby 中的賦值會賦值給目前區塊外的現有變數。否則,它會在目前區塊的作用域中建立新變數。
-
CoffeeScript 在許多方面都效仿 Ruby,也很類似。它明確禁止遮蔽,表示賦值始終賦值給外部作用域中的變數(如果存在),一直到最外層的全域作用域。否則,它會在目前函數的作用域中建立變數。
-
在 JavaScript 中,如果找到,賦值會修改任何封閉作用域中的現有變數。如果沒有,它會隱式地在全域作用域中建立新變數。
隱式宣告的主要優點是簡單。語法較少,也沒有「宣告」的概念需要學習。使用者可以直接開始賦值,而語言會自行處理。
較舊的靜態類型語言(如 C)受益於明確宣告,因為它們為使用者提供了一個地方來告訴編譯器每個變數的類型以及要為其分配多少儲存空間。在動態類型、垃圾回收的語言中,這並不是真的必要,因此您可以採用隱式宣告。感覺更「腳本化」,更「你知道我的意思」。
但這是一個好主意嗎?隱式宣告存在一些問題。
-
使用者可能打算賦值給現有變數,但可能拼寫錯誤了。直譯器不知道這一點,因此它會默默地建立一些新變數,而使用者想要賦值的變數仍然具有其舊值。這在 JavaScript 中尤其惡劣,因為錯字會建立全域變數,進而可能會干擾其他程式碼。
-
JS、Ruby 和 CoffeeScript 使用具有相同名稱的現有變數(即使在外部作用域中)的存在—來判斷賦值是建立新變數還是賦值給現有變數。這表示在周圍的作用域中新增新變數可能會變更現有程式碼的含義。原本是區域變數可能會默默地變成對該新的外部變數的賦值。
-
在 Python 中,您可能想要賦值給目前函數外部的某些變數,而不是在目前函數中建立新變數,但您不能這樣做。
隨著時間的推移,我所知道的具有隱式變數宣告的語言最終新增了更多功能和複雜性來處理這些問題。
-
今天,普遍認為 JavaScript 中隱式宣告全域變數是一個錯誤。「嚴格模式」會停用它並使其成為編譯錯誤。
-
Python 新增了
global陳述式,讓您可以從函數內部明確地賦值給全域變數。後來,隨著函數式程式設計和巢狀函數變得越來越流行,它們新增了類似的nonlocal陳述式來賦值給封閉函數中的變數。 -
Ruby 擴展了它的區塊語法,允許將某些變數明確宣告為區塊的局部變數,即使外部作用域中存在相同的名稱。
鑑於這些,我認為簡單性論證大多已失效。有一種說法認為隱式宣告是正確的預設值,但我個人覺得這不太有說服力。
我的看法是,隱式宣告在過去的幾年中是有道理的,當時大多數腳本語言都是高度命令式的,並且程式碼相當扁平。隨著程式設計師越來越習慣於深層巢狀結構、函數式程式設計和閉包,人們越來越常想要存取外部作用域中的變數。這使得使用者更有可能遇到複雜的情況,在這些情況下,不清楚他們是打算讓賦值建立新變數還是重用周圍的變數。
因此,我更喜歡明確宣告變數,這就是 Lox 要求這樣做的原因。