控制流程
邏輯,就像威士忌一樣,過量服用會失去其有益的效果。
愛德華·約翰·莫頓·德拉克斯·普倫凱特,鄧薩尼勳爵
相較於上一章艱苦的馬拉松,今天是一場輕鬆愉快的漫步於雛菊草地。雖然工作很輕鬆,但回報卻出奇地豐厚。
現在,我們的直譯器只不過是一個計算器。一個 Lox 程式在完成之前只能執行固定量的工作。要讓它執行兩倍的時間,你必須讓原始碼的長度加倍。我們即將解決這個問題。在這一章中,我們的直譯器朝著程式語言的最高殿堂邁進了一大步:圖靈完備性。
9.1圖靈機 (簡述)
在上個世紀初,數學家們偶然發現了一系列令人困惑的 悖論,這使得他們懷疑他們所建立的基礎的穩定性。為了應對這種 危機,他們回到了原點。從少數的公理、邏輯和集合論開始,他們希望在堅不可摧的基礎上重建數學。
他們想嚴謹地回答諸如「所有真陳述都可以被證明嗎?」、「我們可以計算所有我們可以定義的函數嗎?」,甚至是更廣泛的問題,「當我們聲稱一個函數是『可計算的』時,我們的意思是甚麼?」
他們假設前兩個問題的答案是「是」。剩下的就是證明它。結果證明,這兩個問題的答案都是「否」,而且令人驚訝的是,這兩個問題之間存在著深刻的關聯。這是數學一個引人入勝的角落,觸及了大腦能夠做甚麼以及宇宙如何運作的基本問題。我無法在這裡公正地介紹它。
我想指出的是,在證明前兩個問題的答案是「否」的過程中,艾倫·圖靈和阿隆佐·邱奇為最後一個問題設計了一個精確的答案—一個關於哪種類型的函數是 可計算的 的定義。他們各自創建了一個微小的系統,其中包含一組最小的機制,但仍然強大到足以計算(非常)大類函數中的任何一個。
這些現在被認為是「可計算函數」。圖靈的系統被稱為 圖靈機。邱奇的系統是 λ 演算。兩者仍然被廣泛用作計算模型的基礎,事實上,許多現代函數式程式語言的核心都使用 λ 演算。
圖靈機有更好的知名度—目前還沒有關於阿隆佐·邱奇的好萊塢電影—但這兩種形式在能力上是等價的。事實上,任何具有一定最低程度表達能力的程式語言都足以計算任何可計算的函數。
你可以透過在你的語言中編寫一個圖靈機的模擬器來證明這一點。由於圖靈證明了他的機器可以計算任何可計算的函數,因此,這意味著你的語言也可以。你所需要做的就是將函數轉換為圖靈機,然後在你的模擬器上執行它。
如果你的語言有足夠的表達能力來做到這一點,它就被認為是圖靈完備的。圖靈機非常簡單,因此不需要太多的能力來做到這一點。你基本上需要算術、一點點控制流程,以及分配和使用(理論上)任意數量記憶體的能力。我們已經有了第一個。在本章結束時,我們將擁有第二個。
9.2條件執行
足夠的歷史,讓我們來提升一下我們的語言。我們可以將控制流程大致分為兩種類型
-
條件或分支控制流程用於不執行某段程式碼。在命令式程式設計中,你可以將其視為跳過程式碼區域。
-
迴圈控制流程會多次執行一段程式碼。它會跳回,以便你可以再次執行某些操作。由於你通常不想要無限迴圈,因此它通常具有一些條件邏輯,以便知道何時停止迴圈。
分支比較簡單,因此我們將從這裡開始。C 衍生語言有兩個主要的條件執行功能,if 陳述式和名稱精闢的「條件」運算子 (?:)。if 陳述式允許你有條件地執行陳述式,而條件運算子允許你有條件地執行運算式。
為了簡單起見,Lox 沒有條件運算子,所以讓我們開始使用我們的 if 陳述式。我們的陳述式語法得到了一個新的產生式。
statement → exprStmt | ifStmt | printStmt | block ; ifStmt → "if" "(" expression ")" statement ( "else" statement )? ;
if 陳述式有一個用於條件的運算式,然後是一個如果條件為真則要執行的陳述式。選擇性地,它也可能有一個 else 關鍵字和一個如果條件為假則要執行的陳述式。 語法樹節點包含這三個部分中的每一個的欄位。
"Expression : Expr expression",
在 main() 中
"If : Expr condition, Stmt thenBranch," + " Stmt elseBranch",
"Print : Expr expression",
與其他陳述式一樣,剖析器通過前導的 if 關鍵字識別 if 陳述式。
private Stmt statement() {
在 statement() 中
if (match(IF)) return ifStatement();
if (match(PRINT)) return printStatement();
當它找到一個時,它會呼叫這個新的方法來剖析其餘部分
在 statement() 之後添加
private Stmt ifStatement() { consume(LEFT_PAREN, "Expect '(' after 'if'."); Expr condition = expression(); consume(RIGHT_PAREN, "Expect ')' after if condition."); Stmt thenBranch = statement(); Stmt elseBranch = null; if (match(ELSE)) { elseBranch = statement(); } return new Stmt.If(condition, thenBranch, elseBranch); }
像往常一樣,剖析程式碼緊貼著語法。它通過尋找前面的 else 關鍵字來偵測 else 子句。如果沒有,則語法樹中的 elseBranch 欄位為 null。
這個看似無害的可選 else 實際上已經在我們的語法中開啟了一個歧義。請考慮
if (first) if (second) whenTrue(); else whenFalse();
這裡有一個謎題:這個 else 子句屬於哪個 if 陳述式?這不僅僅是一個關於我們如何表示語法的理論問題。它實際上影響程式碼的執行方式
-
如果我們將 else 附加到第一個
if陳述式,那麼如果first為假,則會呼叫whenFalse(),而與second的值無關。 -
如果我們將它附加到第二個
if陳述式,那麼只有當first為真且second為假時,才會呼叫whenFalse()。
由於 else 子句是可選的,並且沒有明確的分隔符號標記 if 陳述式的結束,因此當你以這種方式嵌套 if 時,語法會產生歧義。這種經典的語法陷阱稱為 懸空 else 問題。
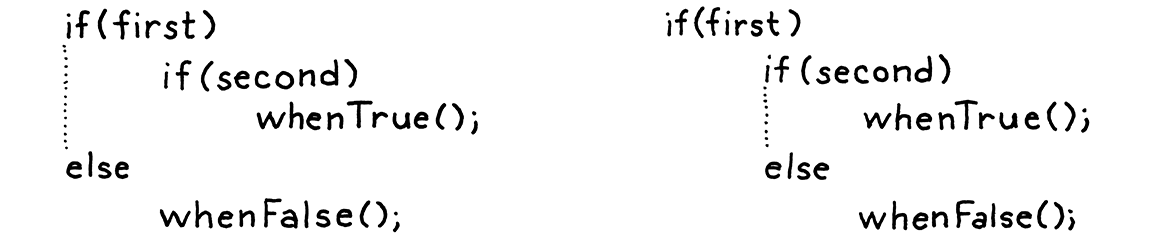
可以定義一個直接避免歧義的上下文無關語法,但它需要將大多數陳述式規則拆分為成對,一個允許帶有 else 的 if,另一個不允許。這很煩人。
相反,大多數語言和剖析器以特別的方式避免這個問題。無論他們使用甚麼技巧來擺脫困境,他們總是選擇相同的解釋—else 與其前面的最近的 if 綁定。
我們的剖析器已經很方便地這樣做了。由於 ifStatement() 會在返回之前急切地尋找 else,因此對嵌套系列的內部呼叫將在返回到外部 if 陳述式之前為自己聲明 else 子句。
掌握了語法,我們就可以開始進行直譯了。
在 visitExpressionStmt() 後面新增
@Override public Void visitIfStmt(Stmt.If stmt) { if (isTruthy(evaluate(stmt.condition))) { execute(stmt.thenBranch); } else if (stmt.elseBranch != null) { execute(stmt.elseBranch); } return null; }
直譯器的實作是圍繞著相同的 Java 程式碼的薄包裝。它會評估條件。如果為真值,則執行 then 分支。否則,如果有 else 分支,則執行該分支。
如果您將此程式碼與直譯器處理我們已實作的其他語法的方式進行比較,會發現使控制流程特殊的部分是 Java 的 if 敘述。大多數其他語法樹都會始終評估其子樹。在這裡,我們可能不會評估 then 或 else 敘述。如果其中任何一個有副作用,則選擇不評估它會變成使用者可見的。
9 . 3邏輯運算子
由於我們沒有條件運算子,您可能會認為我們已經完成了分支,但事實並非如此。即使沒有三元運算子,仍有兩個在技術上屬於控制流程結構的運算子—邏輯運算子 and 和 or。
這些與其他二元運算子不同,因為它們會短路。如果在評估左運算元後,我們知道邏輯表達式的結果必須是什麼,我們就不會評估右運算元。例如
false and sideEffect();
對於 and 表達式要評估為真值,兩個運算元都必須是真值。我們在評估左運算元 false 時,可以立即看到情況並非如此,因此無需評估 sideEffect(),它會被略過。
這就是我們沒有使用其他二元運算子來實作邏輯運算子的原因。現在我們準備好了。這兩個新運算子在優先順序表中很低。與 C 中的 || 和 && 類似,它們各自有自己的優先順序,or 低於 and。我們將它們放在 assignment 和 equality 之間。
expression → assignment ; assignment → IDENTIFIER "=" assignment | logic_or ; logic_or → logic_and ( "or" logic_and )* ; logic_and → equality ( "and" equality )* ;
assignment 現在不會回退到 equality,而是會連鎖到 logic_or。兩個新規則 logic_or 和 logic_and 與其他二元運算子相似。然後 logic_and 會呼叫 equality 來處理其運算元,而我們會連鎖回到其餘的表達式規則。
我們可以為這兩個新表達式重複使用現有的 Expr.Binary 類別,因為它們具有相同的欄位。但是,這樣 visitBinaryExpr() 就必須檢查運算子是否為邏輯運算子之一,並使用不同的程式碼路徑來處理短路。我認為為這些運算子定義一個新的類別會更清楚,這樣它們就會有自己的 visit 方法。
"Literal : Object value",
在 main() 中
"Logical : Expr left, Token operator, Expr right",
"Unary : Token operator, Expr right",
為了將新表達式編織到剖析器中,我們首先變更指派的剖析程式碼以呼叫 or()。
private Expr assignment() {
在 assignment() 中
取代 1 行
Expr expr = or();
if (match(EQUAL)) {
剖析一系列 or 表達式的程式碼會反映其他二元運算子。
在 assignment() 後面新增
private Expr or() { Expr expr = and(); while (match(OR)) { Token operator = previous(); Expr right = and(); expr = new Expr.Logical(expr, operator, right); } return expr; }
其運算元是下一個較高優先順序的層級,即新的 and 表達式。
在 or() 後面新增
private Expr and() { Expr expr = equality(); while (match(AND)) { Token operator = previous(); Expr right = equality(); expr = new Expr.Logical(expr, operator, right); } return expr; }
它會呼叫 equality() 來處理其運算元,這樣一來,表達式剖析器就會再次全部連結在一起。我們準備好進行直譯了。
在 visitLiteralExpr() 後面新增
@Override public Object visitLogicalExpr(Expr.Logical expr) { Object left = evaluate(expr.left); if (expr.operator.type == TokenType.OR) { if (isTruthy(left)) return left; } else { if (!isTruthy(left)) return left; } return evaluate(expr.right); }
如果您將此程式碼與前面章節的 visitBinaryExpr() 方法進行比較,您可以看到差異。在這裡,我們會先評估左運算元。我們會查看它的值,以判斷是否可以短路。如果不能,且只有在不能的情況下,我們才會評估右運算元。
另一個有趣的環節是決定要傳回的實際值。由於 Lox 是動態型別的,我們允許任何型別的運算元,並使用真值來判斷每個運算元代表什麼。我們會將類似的推理應用於結果。邏輯運算子不會保證會明確傳回 true 或 false,而只是保證它會傳回一個具有適當真值的值。
幸運的是,我們手邊就有具有適當真值的值—運算元本身的結果。因此,我們會使用這些值。例如
print "hi" or 2; // "hi". print nil or "yes"; // "yes".
在第一行中,"hi" 為真值,因此 or 會短路並傳回該值。在第二行中,nil 為假值,因此它會評估並傳回第二個運算元 "yes"。
這涵蓋了 Lox 中的所有分支基本類型。我們準備好跳到迴圈了。您看到我做了什麼嗎?跳。向前。懂了嗎?你看,它就像在參考 . . .喔,算了。
9 . 4While 迴圈
Lox 具有兩個迴圈控制流程敘述,while 和 for。while 迴圈比較簡單,所以我們先從這裡開始。它的文法與 C 中的文法相同。
statement → exprStmt | ifStmt | printStmt | whileStmt | block ; whileStmt → "while" "(" expression ")" statement ;
我們會將另一個子句新增到敘述規則中,該子句會指向 while 的新規則。它會採用 while 關鍵字,後面接著括號中的條件表達式,然後是迴圈主體的敘述。該新的文法規則會取得語法樹節點。
"Print : Expr expression",
"Var : Token name, Expr initializer",
在 main() 中
在上一行中新增 “,”
"While : Expr condition, Stmt body"
));
節點會儲存條件和主體。在這裡,您可以看到為什麼為表達式和敘述建立單獨的基底類別會很好。欄位宣告清楚地表明條件是表達式,而主體是敘述。
在剖析器中,我們遵循與 if 敘述相同的方法。首先,我們在 statement() 中新增另一個案例,以偵測和比對開頭的關鍵字。
if (match(PRINT)) return printStatement();
在 statement() 中
if (match(WHILE)) return whileStatement();
if (match(LEFT_BRACE)) return new Stmt.Block(block());
這會將實際的工作委派給這個方法
在 varDeclaration() 後面新增
private Stmt whileStatement() { consume(LEFT_PAREN, "Expect '(' after 'while'."); Expr condition = expression(); consume(RIGHT_PAREN, "Expect ')' after condition."); Stmt body = statement(); return new Stmt.While(condition, body); }
文法非常簡單,這只是直接將它翻譯成 Java。說到直接翻譯成 Java,以下是我們如何執行新語法
在 visitVarStmt() 後面新增
@Override public Void visitWhileStmt(Stmt.While stmt) { while (isTruthy(evaluate(stmt.condition))) { execute(stmt.body); } return null; }
與 if 的 visit 方法類似,此訪客會使用對應的 Java 功能。此方法並不複雜,但它使 Lox 更強大。我們終於可以編寫執行時間不受原始程式碼長度嚴格限制的程式了。
9 . 5For 迴圈
我們來到最後一個控制流程結構,古老的 C 樣式 for 迴圈。我可能不需要提醒您,但它的樣子如下
for (var i = 0; i < 10; i = i + 1) print i;
以文法表示,即
statement → exprStmt | forStmt | ifStmt | printStmt | whileStmt | block ; forStmt → "for" "(" ( varDecl | exprStmt | ";" ) expression? ";" expression? ")" statement ;
在括號內,您有三個以分號分隔的子句
-
第一個子句是初始化器。它只執行一次,在任何其他動作之前。它通常是表達式,但為了方便起見,我們也允許變數宣告。在這種情況下,變數的範圍限定於
for迴圈的其餘部分—其他兩個子句和主體。 -
接下來是條件。與
while迴圈一樣,這個表達式會控制何時結束迴圈。它在每次反覆運算開始時會評估一次,包括第一次。如果結果為真值,它會執行迴圈主體。否則,它會結束。 -
最後一個子句是增量。它是一個任意表達式,會在每次迴圈反覆運算結束時執行一些工作。表達式的結果會被捨棄,因此它必須具有副作用才有用。在實務上,它通常會遞增一個變數。
這些子句中的任何一個都可以省略。右括號後面是迴圈主體的敘述,通常是一個區塊。
9 . 5 . 1語法糖
這是一個龐大的機制,但請注意,它沒有任何動作是您無法使用我們已有的敘述來完成的。如果 for 迴圈不支援初始化器子句,您可以將初始化器表達式放在 for 敘述之前。如果沒有增量子句,您可以自己將增量表達式放在主體末尾。
換句話說,Lox 並不需要 for 迴圈,它們只是讓一些常見的程式碼模式更易於撰寫。這些類型的功能稱為語法糖。例如,前面的 for 迴圈可以改寫如下
{
var i = 0;
while (i < 10) {
print i;
i = i + 1;
}
}
此指令碼具有與前一個指令碼完全相同的語義,儘管它並不那麼賞心悅目。像 Lox 的 for 迴圈這樣的語法糖功能使語言更易於使用並提高工作效率。但是,尤其是在複雜的語言實作中,每一個需要後端支援和最佳化的語言功能都很昂貴。
我們可以「魚與熊掌兼得」,透過去糖化的方式。這個有趣的詞彙描述了一個過程,前端會將使用語法糖的程式碼轉換成後端已經知道如何執行的更原始的形式。
我們將會把 for 迴圈去糖化為 while 迴圈和直譯器已經可以處理的其他陳述式。在我們這個簡單的直譯器中,去糖化實際上並沒有為我們省下太多工作,但它確實讓我有一個藉口向你介紹這個技巧。因此,與之前的陳述式不同,我們不會新增一個新的語法樹節點。相反地,我們會直接進入解析。首先,加入我們很快就會需要的一個引入。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
像每個陳述式一樣,我們從匹配它的關鍵字開始解析一個 for 迴圈。
private Stmt statement() {
在 statement() 中
if (match(FOR)) return forStatement();
if (match(IF)) return ifStatement();
這裡開始變得有趣了。去糖化將會在這裡發生,所以我們會一點一點地建立這個方法,從子句前的左括號開始。
在 statement() 之後添加
private Stmt forStatement() { consume(LEFT_PAREN, "Expect '(' after 'for'."); // More here... }
第一個子句是初始化器。
consume(LEFT_PAREN, "Expect '(' after 'for'.");
在 forStatement() 中
取代 1 行
Stmt initializer; if (match(SEMICOLON)) { initializer = null; } else if (match(VAR)) { initializer = varDeclaration(); } else { initializer = expressionStatement(); }
}
如果 ( 後面的符號是一個分號,則表示初始化器已被省略。否則,我們檢查是否有 var 關鍵字,看看它是否是一個變數宣告。如果兩者都不匹配,那它一定是一個表達式。我們解析該表達式並將其包裝在一個表達式陳述式中,以便初始化器始終為 Stmt 類型。
接下來是條件。
initializer = expressionStatement();
}
在 forStatement() 中
Expr condition = null;
if (!check(SEMICOLON)) {
condition = expression();
}
consume(SEMICOLON, "Expect ';' after loop condition.");
}
同樣地,我們尋找分號來判斷子句是否已被省略。最後一個子句是遞增。
consume(SEMICOLON, "Expect ';' after loop condition.");
在 forStatement() 中
Expr increment = null;
if (!check(RIGHT_PAREN)) {
increment = expression();
}
consume(RIGHT_PAREN, "Expect ')' after for clauses.");
}
它與條件子句類似,只是這個子句以右括號終止。剩下的就是主體。
consume(RIGHT_PAREN, "Expect ')' after for clauses.");
在 forStatement() 中
Stmt body = statement(); return body;
}
我們已經解析了 for 迴圈的各種部分,並且產生的 AST 節點都存在一些 Java 區域變數中。這就是去糖化發生的地方。我們取出這些節點,並使用它們來合成表達 for 迴圈語義的語法樹節點,就像我之前向你展示的手動去糖化範例一樣。
如果我們反向操作,程式碼會稍微簡單一點,所以我們先從遞增子句開始。
Stmt body = statement();
在 forStatement() 中
if (increment != null) { body = new Stmt.Block( Arrays.asList( body, new Stmt.Expression(increment))); }
return body;
遞增子句(如果存在)會在迴圈的每次迭代中的主體之後執行。我們透過將主體替換為一個小程式碼區塊來做到這一點,該區塊包含原始主體,後跟一個計算遞增的表達式陳述式。
}
在 forStatement() 中
if (condition == null) condition = new Expr.Literal(true); body = new Stmt.While(condition, body);
return body;
接下來,我們取得條件和主體,並使用原始的 while 迴圈來建立迴圈。如果省略了條件,我們會塞入 true 以建立無限迴圈。
body = new Stmt.While(condition, body);
在 forStatement() 中
if (initializer != null) { body = new Stmt.Block(Arrays.asList(initializer, body)); }
return body;
最後,如果存在初始化器,它會在整個迴圈之前執行一次。我們再次透過將整個陳述式替換為一個程式碼區塊來做到這一點,該程式碼區塊會執行初始化器,然後執行迴圈。
就這樣。我們的直譯器現在支援 C 風格的 for 迴圈,而且我們根本不必觸碰 Interpreter 類別。由於我們已經去糖化為直譯器已經知道如何走訪的節點,所以沒有更多工作需要完成。
最後,Lox 已經足夠強大可以娛樂我們,至少幾分鐘。這是一個小程式,可以列印費波那契數列的前 21 個元素
var a = 0; var temp; for (var b = 1; a < 10000; b = temp + b) { print a; temp = a; a = b; }
挑戰
-
幾章之後,當 Lox 支援一級函式和動態分派時,我們技術上將不需要內建於語言中的分支陳述式。展示如何根據這些來實現條件執行。說出一種使用這種技術來實現控制流程的語言。
-
同樣地,迴圈可以使用相同的工具來實現,前提是我們的直譯器支援重要的最佳化。那是什麼,為什麼是必要的?說出一種使用這種技術來實現迭代的語言。
-
與 Lox 不同,大多數其他 C 風格的語言也支援迴圈內的
break和continue陳述式。新增對break陳述式的支援。語法是一個
break關鍵字,後跟一個分號。在任何封閉迴圈之外出現break陳述式都應該是語法錯誤。在執行期間,break陳述式會導致執行跳轉到最近的封閉迴圈的末尾,並從那裡繼續執行。請注意,break可能會巢狀在其他區塊和也需要退出的if陳述式中。
設計筆記:一匙匙的語法糖
當你設計自己的語言時,你會選擇要在語法中加入多少語法糖。你要製作一個不加糖的健康食品,其中每個語義操作都對應到一個單一的語法單元,還是一個頹廢的甜點,其中每個行為都可以用十種不同的方式來表達?成功的語言存在於這個連續體的所有點上。
在極端酸澀的末端,是一些具有非常簡潔語法的語言,如 Lisp、Forth 和 Smalltalk。Lisp 的使用者聲稱他們的語言「沒有語法」,而 Smalltalk 的使用者則自豪地展示你可以將整個語法寫在一張索引卡上。這個族群的哲學是,語言不需要語法糖。相反地,它提供的最簡語法和語義足夠強大,可以讓函式庫程式碼像語言本身的一部分一樣具有表達力。
接近這些的是像 C、Lua 和 Go 這樣的語言。它們旨在追求簡潔和清晰,而不是極簡主義。有些,如 Go,刻意避開語法糖和先前類別的語法擴充性。它們希望語法不會妨礙語義,因此它們專注於保持語法和函式庫的簡單性。程式碼應該是顯而易見的,而不是美麗的。
在中間的某處,你會找到像 Java、C# 和 Python 這樣的語言。最終你會接觸到 Ruby、C++、Perl 和 D—這些語言已經在其語法中塞入了太多的語法,以至於它們快要用完鍵盤上的標點符號了。
在某種程度上,在光譜上的位置與年齡相關。在後續版本中加入一些語法糖相對容易。新的語法會讓人喜歡,而且與修改語義相比,它不太可能破壞現有的程式。一旦加入,你就永遠無法將其移除,因此語言往往會隨著時間而變得更甜。從頭開始建立新語言的主要好處之一是,它讓你能夠有機會刮掉那些累積的糖霜層,並重新開始。
語法糖在 PL (程式語言) 知識分子中名聲不好。在那群人中,對於極簡主義有一種真正的迷戀。這是有道理的。設計不良、不需要的語法會增加認知負擔,而沒有添加足夠的表達能力來承載其重量。由於總是存在將新功能塞入語言的壓力,因此需要紀律和對簡單性的關注才能避免膨脹。一旦你加入一些語法,你就被它困住了,因此謹慎行事是明智的。
同時,大多數成功的語言都具有相當複雜的語法,至少在它們被廣泛使用時是這樣。程式設計師會在他們選擇的語言中花費大量的時間,而這裡和那裡的一些便利確實可以提高他們工作的舒適度和效率。
達到適當的平衡—為你的語言選擇適當的甜度—取決於你自己的品味。