函式
人類心智的運作方式也是如此—透過將舊有的想法組合成新的結構,而這些新的結構又成為新的想法,進而能夠再次被組合成新的結構,不斷地循環,且距離每個語言的土壤,也就是基本的、實在的意象越來越遙遠。
道格拉斯·R·霍夫施塔特,《我是個怪圈》
本章標誌著許多辛勤工作的頂點。前幾章各自加入了實用的功能,但它們也都提供了謎題的一塊。我們將採用這些碎片—表達式、陳述式、變數、控制流程和詞法作用域—再加入一些,並將它們組合成對真正的使用者自訂函式和函式呼叫的支援。
10 . 1函式呼叫
你肯定很熟悉 C 語言風格的函式呼叫語法,但它的文法比你意識到的更微妙。呼叫通常是針對有名稱的函式,例如
average(1, 2);
但是,被呼叫函式的名稱實際上並不是呼叫語法的一部分。被呼叫的東西—也就是被呼叫者—可以是任何計算結果為函式的表達式。(好吧,它確實必須是一個相當高優先級的表達式,但括號可以處理這個問題。)例如
getCallback()();
這裡有兩個呼叫表達式。第一對括號的被呼叫者是 getCallback。但第二個呼叫的被呼叫者是整個 getCallback() 表達式。括號跟在表達式後面,表示函式呼叫。你可以將呼叫視為一種以前綴 ( 開始的後綴運算子。
這個「運算子」的優先級高於任何其他運算子,甚至是單元運算子。因此,我們將它放入文法中,讓 unary 規則向上冒泡到新的 call 規則。
unary → ( "!" | "-" ) unary | call ; call → primary ( "(" arguments? ")" )* ;
此規則會比對一個主要表達式,後跟零個或多個函式呼叫。如果沒有括號,則會解析為一個裸露的主要表達式。否則,每個呼叫都會由一對括號識別,括號內有一個可選的參數清單。參數清單文法是
arguments → expression ( "," expression )* ;
此規則需要至少一個參數表達式,後跟零個或多個其他表達式,每個表達式前面都有一個逗號。為了處理零參數呼叫,call 規則本身會將整個 arguments 產生式視為可選的。
我承認,對於極其常見的「零個或多個以逗號分隔的事物」模式來說,這似乎在語法上比你預期的要笨拙。有一些複雜的後設語法可以更好地處理這個問題,但在我們的 BNF 和我見過的許多語言規格中,它是如此繁瑣。
在我們的語法樹產生器中,我們新增一個新節點。
"Binary : Expr left, Token operator, Expr right",
在 main() 中
"Call : Expr callee, Token paren, List<Expr> arguments",
"Grouping : Expr expression",
它會儲存被呼叫者表達式和參數表達式清單。它也會儲存右括號的權杖。當我們報告函式呼叫導致的執行階段錯誤時,我們將使用該權杖的位置。
開啟剖析器。在 unary() 過去直接跳到 primary() 的地方,將其變更為呼叫,好的,call()。
return new Expr.Unary(operator, right);
}
在 unary() 中
取代 1 行
return call();
}
它的定義是
在 unary() 之後新增
private Expr call() { Expr expr = primary(); while (true) { if (match(LEFT_PAREN)) { expr = finishCall(expr); } else { break; } } return expr; }
這裡的程式碼與文法規則不太一致。我移動了一些東西來使程式碼更簡潔—這是我們手寫剖析器的優勢之一。但它與我們剖析中綴運算子的方式大致相似。首先,我們剖析一個主要表達式,即呼叫的「左運算元」。然後,每次我們看到 ( 時,我們都會呼叫 finishCall() 來使用先前剖析的表達式作為被呼叫者來剖析呼叫表達式。傳回的表達式會變成新的 expr,而我們迴圈以查看結果是否本身被呼叫。
剖析參數清單的程式碼在這個輔助程式中
在 unary() 之後新增
private Expr finishCall(Expr callee) { List<Expr> arguments = new ArrayList<>(); if (!check(RIGHT_PAREN)) { do { arguments.add(expression()); } while (match(COMMA)); } Token paren = consume(RIGHT_PAREN, "Expect ')' after arguments."); return new Expr.Call(callee, paren, arguments); }
這或多或少是轉換為程式碼的 arguments 文法規則,只是我們也處理了零參數的情況。我們先透過查看下一個權杖是否為 ) 來檢查這種情況。如果是,我們就不會嘗試剖析任何參數。
否則,我們會剖析一個表達式,然後尋找一個逗號,表示後面還有另一個參數。只要我們在每個表達式後面找到逗號,我們就會繼續執行此操作。當我們沒有找到逗號時,參數清單必須完成,而我們消耗預期的右括號。最後,我們將被呼叫者和這些參數封裝到一個呼叫 AST 節點中。
10 . 1 . 1最大參數計數
目前,我們剖析參數的迴圈沒有邊界。如果你想呼叫函式並傳遞一百萬個參數給它,剖析器也不會有任何問題。我們是否要限制這個?
其他語言有各種方法。C 標準規定一個符合標準的實作必須至少支援 127 個函式參數,但沒有說有任何上限。Java 規格規定一個方法最多只能接受 255 個參數。
我們的 Lox Java 直譯器實際上不需要限制,但具有最大參數數將簡化我們在 第三部分 中的位元組碼直譯器。我們希望我們的兩個直譯器彼此相容,即使在像這樣的奇怪邊角情況下也是如此,因此我們將相同的限制新增到 jlox 中。
do {
在 finishCall() 中
if (arguments.size() >= 255) { error(peek(), "Can't have more than 255 arguments."); }
arguments.add(expression());
請注意,如果程式碼遇到太多參數,則程式碼會在這裡報告錯誤,但它不會擲回錯誤。擲回是我們進入緊急模式的方式,如果剖析器處於混亂狀態且不知道它在文法中的位置,這就是我們想要的。但在這裡,剖析器仍然處於完全有效的狀態—它只是找到太多參數。因此,它報告錯誤並繼續執行。
10 . 1 . 2解譯函式呼叫
我們沒有任何可以呼叫的函式,因此先開始實作呼叫似乎很奇怪,但我們會在到達那裡時擔心。首先,我們的直譯器需要一個新的匯入。
import java.util.ArrayList;
import java.util.List;
與往常一樣,解譯從我們新的呼叫表達式節點的新訪問方法開始。
在 visitBinaryExpr() 之後新增
@Override public Object visitCallExpr(Expr.Call expr) { Object callee = evaluate(expr.callee); List<Object> arguments = new ArrayList<>(); for (Expr argument : expr.arguments) { arguments.add(evaluate(argument)); } LoxCallable function = (LoxCallable)callee; return function.call(this, arguments); }
首先,我們計算被呼叫者的表達式。通常,此表達式只是一個透過名稱查詢函式的識別碼,但它可以是任何東西。然後,我們依序計算每個參數表達式,並將產生的值儲存在清單中。
一旦我們準備好被呼叫者和參數,剩下的就是執行呼叫。我們透過將被呼叫者轉換為 LoxCallable,然後在它上叫用 call() 方法來完成此操作。任何可以像函式一樣呼叫的 Lox 物件的 Java 表示法都會實作此介面。這自然包括使用者自訂的函式,以及類別物件,因為類別會被「呼叫」以建構新的實例。我們稍後也會將它用於另一個目的。
這個新介面沒有太多東西。
建立新檔案
package com.craftinginterpreters.lox; import java.util.List; interface LoxCallable { Object call(Interpreter interpreter, List<Object> arguments); }
我們傳遞直譯器,以防實作 call() 的類別需要它。我們也會將已計算的參數值清單提供給它。然後,實作者的工作是傳回呼叫表達式產生的值。
10 . 1 . 3呼叫類型錯誤
在我們開始實作 LoxCallable 之前,我們需要讓訪問方法更健全一點。它目前忽略了幾個我們不能假裝不會發生的失敗模式。首先,如果被呼叫者實際上不是你可以呼叫的東西,會發生什麼事?如果你嘗試這樣做會怎麼樣?
"totally not a function"();
字串在 Lox 中是不可呼叫的。Lox 字串的執行階段表示是一個 Java 字串,因此當我們將其轉換為 LoxCallable 時,JVM 會擲回 ClassCastException。我們不希望我們的直譯器吐出一些令人討厭的 Java 堆疊追蹤並死掉。相反,我們需要先自行檢查類型。
}
在 visitCallExpr() 中
if (!(callee instanceof LoxCallable)) { throw new RuntimeError(expr.paren, "Can only call functions and classes."); }
LoxCallable function = (LoxCallable)callee;
我們仍然擲回例外,但現在我們擲回我們自己的例外類型,直譯器知道要捕獲並優雅地報告該類型。
10 . 1 . 4檢查arity
另一個問題與函式的 arity 有關。Arity 是函式或運算預期參數數的奇特術語。單元運算子具有 arity 一,二元運算子具有 arity 二,依此類推。對於函式,arity 由它宣告的參數數決定。
fun add(a, b, c) { print a + b + c; }
這個函數定義了三個參數,a、b 和 c,所以它的元數 (arity) 是 3,並且需要三個引數。那麼如果你嘗試這樣呼叫它會發生什麼事呢?
add(1, 2, 3, 4); // Too many. add(1, 2); // Too few.
不同的程式語言會用不同的方法來處理這個問題。當然,大多數靜態型別語言會在編譯時檢查這個問題,如果引數的數量與函數的元數不符,就會拒絕編譯程式碼。JavaScript 會捨棄任何你傳遞的多餘引數。如果你傳遞的引數不足,它會用一種神奇、有點像 null 但又不太一樣的值 undefined 來填補遺失的參數。Python 則比較嚴格。如果引數列表太短或太長,它會引發執行階段錯誤。
我認為後者是比較好的做法。傳遞錯誤數量的引數幾乎總是個錯誤,而且實際上我確實會犯這種錯。鑑於此,實作越早注意到這個問題並提醒我,就越好。所以對於 Lox,我們將採用 Python 的做法。在呼叫可呼叫物件之前,我們會檢查引數列表的長度是否與可呼叫物件的元數相符。
LoxCallable function = (LoxCallable)callee;
在 visitCallExpr() 中
if (arguments.size() != function.arity()) { throw new RuntimeError(expr.paren, "Expected " + function.arity() + " arguments but got " + arguments.size() + "."); }
return function.call(this, arguments);
這需要在 LoxCallable 介面上新增一個方法,以詢問它的元數。
interface LoxCallable {
在介面 LoxCallable 中
int arity();
Object call(Interpreter interpreter, List<Object> arguments);
我們可以將元數檢查推入 call() 的具體實作中。但是,由於我們會有許多類別實作 LoxCallable,這將導致重複的驗證分散在幾個類別中。將其提升到 visit 方法中,讓我們可以在一個地方完成它。
10 . 2原生函式
理論上我們可以呼叫函式,但是我們還沒有任何函式可以呼叫。在我們開始使用使用者定義的函式之前,現在是介紹語言實作中一個重要但經常被忽略的面向的好時機—原生函式。這些是直譯器公開給使用者程式碼使用的函式,但它們是在主機語言(在我們的例子中是 Java)中實作的,而不是在被實作的語言(Lox)中實作的。
有時這些函式被稱為 primitives、外部函式或 foreign functions。由於這些函式可以在使用者程式執行時被呼叫,它們構成了實作的執行階段的一部分。許多程式語言的書籍都忽略了這些函式,因為它們在概念上並不有趣。它們大多是繁瑣的工作。
但是,當談到如何使你的語言真正擅長執行有用的事情時,實作提供的原生函式至關重要。它們提供對所有程式定義所依據的基本服務的存取權。如果你不提供存取檔案系統的原生函式,使用者將很難編寫讀取和顯示檔案的程式。
許多語言也允許使用者提供自己的原生函式。這樣做的機制稱為 外部函式介面 (foreign function interface, FFI)、原生擴充、原生介面或類似的名稱。這些機制很好,因為它們讓語言實作者不必提供對底層平台支援的每一項功能的存取權。我們不會為 jlox 定義 FFI,但我們會新增一個原生函式,讓你了解它的樣子。
10 . 2 . 1計時
當我們進入第三部分並開始研究 Lox 更有效率的實作時,我們將非常關注效能。效能工作需要測量,而測量又意味著需要使用 基準測試 (benchmarks)。這些程式會測量執行直譯器某些部分所需的時間。
我們可以測量啟動直譯器、執行基準測試和退出的時間,但是這會增加很多額外開銷—JVM 啟動時間、作業系統的干擾等等。當然,這些東西確實很重要,但是如果你只是想驗證對直譯器某個部分的最佳化,你就不希望這些額外開銷模糊了你的結果。
一個更好的解決方案是讓基準測試腳本本身測量程式碼中兩個點之間經過的時間。為此,Lox 程式需要能夠知道時間。現在沒有辦法做到這一點—如果不存取電腦上的底層時鐘,就無法「從頭開始」實作有用的時鐘。
因此,我們將新增 clock() 這個原生函式,它會傳回自某個固定時間點以來經過的秒數。兩次連續呼叫之間的差異會告訴你兩次呼叫之間經過的時間。此函式定義在全域範圍內,因此讓我們確保直譯器可以存取它。
class Interpreter implements Expr.Visitor<Object>,
Stmt.Visitor<Void> {
在類別 Interpreter 中
取代 1 行
final Environment globals = new Environment(); private Environment environment = globals;
void interpret(List<Stmt> statements) {
當我們進入和退出本機範圍時,直譯器中的 environment 欄位會跟著改變。它會追蹤目前的環境。這個新的 globals 欄位則持有對最外層全域環境的固定參考。
當我們實例化 Interpreter 時,我們會將原生函式放入該全域範圍中。
private Environment environment = globals;
在類別 Interpreter 中
Interpreter() { globals.define("clock", new LoxCallable() { @Override public int arity() { return 0; } @Override public Object call(Interpreter interpreter, List<Object> arguments) { return (double)System.currentTimeMillis() / 1000.0; } @Override public String toString() { return "<native fn>"; } }); }
void interpret(List<Stmt> statements) {
這會定義一個名為「clock」的變數。它的值是一個實作 LoxCallable 的 Java 匿名類別。clock() 函式不接受任何引數,所以它的元數是零。call() 的實作會呼叫對應的 Java 函式,並將結果轉換為以秒為單位的雙精度浮點數值。
如果我們想要新增其他原生函式—從使用者讀取輸入、處理檔案等等—我們可以將它們各自新增為自己的匿名類別,這些類別實作 LoxCallable。但是對於本書來說,這個函式實際上是我們唯一需要的。
讓我們擺脫定義函式的困境,讓使用者接管 . . .
10 . 3函式宣告
我們終於可以將新的產生式新增到我們在新增變數時引入的 declaration 規則中。函式宣告(如變數)會繫結新的名稱。這表示它們只能在允許宣告的地方使用。
declaration → funDecl | varDecl | statement ;
更新後的 declaration 規則會參考這個新的規則
funDecl → "fun" function ; function → IDENTIFIER "(" parameters? ")" block ;
主要的 funDecl 規則會使用單獨的輔助規則 function。函式宣告陳述式是 fun 關鍵字,後面接著實際的函式相關內容。當我們處理類別時,我們將重複使用該 function 規則來宣告方法。這些方法看起來與函式宣告相似,但前面沒有 fun。
函式本身是一個名稱,後面接著括號中的參數列表和主體。主體始終是一個大括號區塊,使用與區塊陳述式相同的文法規則。參數列表使用此規則
parameters → IDENTIFIER ( "," IDENTIFIER )* ;
它與之前的 arguments 規則相似,不同之處在於每個參數都是識別符號,而不是運算式。對於解析器來說,這是一個很大的新語法要處理,但是產生的 AST 節點並不算太糟糕。
"Expression : Expr expression",
在 main() 中
"Function : Token name, List<Token> params," + " List<Stmt> body",
"If : Expr condition, Stmt thenBranch," +
函式節點具有名稱、參數列表(它們的名稱)以及主體。我們將主體儲存為大括號內包含的陳述式列表。
在解析器中,我們加入新的宣告。
try {
在 declaration() 中
if (match(FUN)) return function("function");
if (match(VAR)) return varDeclaration();
像其他陳述式一樣,函式透過前導關鍵字來辨識。當我們遇到 fun 時,我們會呼叫 function。這對應於 function 文法規則,因為我們已經比對並使用了 fun 關鍵字。我們將逐步建構此方法,從這裡開始
在 expressionStatement() 之後新增
private Stmt.Function function(String kind) { Token name = consume(IDENTIFIER, "Expect " + kind + " name."); }
現在,它只使用函式名稱的識別符號 token。你可能想知道那個有趣的小 kind 參數。就像我們重複使用文法規則一樣,我們稍後會重複使用 function() 方法來解析類別內的方法。當我們這樣做時,我們會傳遞「method」作為 kind,以便錯誤訊息針對正在解析的宣告類型。
接下來,我們解析參數列表和括在它周圍的括號對。
Token name = consume(IDENTIFIER, "Expect " + kind + " name.");
在 function() 中
consume(LEFT_PAREN, "Expect '(' after " + kind + " name."); List<Token> parameters = new ArrayList<>(); if (!check(RIGHT_PAREN)) { do { if (parameters.size() >= 255) { error(peek(), "Can't have more than 255 parameters."); } parameters.add( consume(IDENTIFIER, "Expect parameter name.")); } while (match(COMMA)); } consume(RIGHT_PAREN, "Expect ')' after parameters.");
}
這就像處理呼叫中參數的程式碼,只是沒有拆分成輔助方法。外層的 if 語句處理零參數的情況,而內層的 while 迴圈會解析參數,只要找到逗號來分隔它們。結果是每個參數名稱的標記列表。
就像我們處理函式呼叫的參數一樣,我們在解析時驗證您沒有超過函式允許的最大參數數量。
最後,我們解析函式主體,並將所有內容包裝在函式節點中。
consume(RIGHT_PAREN, "Expect ')' after parameters.");
在 function() 中
consume(LEFT_BRACE, "Expect '{' before " + kind + " body.");
List<Stmt> body = block();
return new Stmt.Function(name, parameters, body);
}
請注意,我們在呼叫 block() 之前,會在這裡先消耗主體開頭的 {。這是因為 block() 假設大括號標記已經匹配。在這裡消耗它,如果找不到 {,我們就能回報更精確的錯誤訊息,因為我們知道它是在函式宣告的上下文中。
10 . 4函式物件
我們已經解析了一些語法,通常可以準備好進行直譯,但首先我們需要思考如何在 Java 中表示 Lox 函式。我們需要追蹤參數,以便在函式被呼叫時將它們繫結到引數值。當然,我們需要保留函式主體的程式碼,以便可以執行它。
這基本上就是 Stmt.Function 類別的作用。我們可以直接使用它嗎?幾乎可以,但不完全是。我們還需要一個實作 LoxCallable 的類別,以便我們可以呼叫它。我們不希望直譯器的執行階段階段滲透到前端的語法類別中,因此我們不希望 Stmt.Function 本身實作該介面。相反地,我們將它包裝在一個新的類別中。
建立新檔案
package com.craftinginterpreters.lox; import java.util.List; class LoxFunction implements LoxCallable { private final Stmt.Function declaration; LoxFunction(Stmt.Function declaration) { this.declaration = declaration; } }
我們像這樣實作 LoxCallable 的 call()
在 LoxFunction() 之後新增
@Override public Object call(Interpreter interpreter, List<Object> arguments) { Environment environment = new Environment(interpreter.globals); for (int i = 0; i < declaration.params.size(); i++) { environment.define(declaration.params.get(i).lexeme, arguments.get(i)); } interpreter.executeBlock(declaration.body, environment); return null; }
這幾行程式碼是我們直譯器中最基本、最強大的部分之一。正如我們在關於語句和狀態的章節中所看到的,管理名稱環境是語言實作的核心部分。函式與此密切相關。
參數是函式的核心,尤其是函式封裝其參數的事實—函式外部的其他程式碼無法看到它們。這表示每個函式都有自己的環境,在其中儲存這些變數。
此外,這個環境必須動態建立。每個函式呼叫都有自己的環境。否則,遞迴將會中斷。如果同時有多個對同一個函式的呼叫正在進行,則每個呼叫都需要其自己的環境,即使它們都是對同一個函式的呼叫。
例如,以下是一種複雜的計數到三的方法
fun count(n) { if (n > 1) count(n - 1); print n; } count(3);
假設我們在直譯器即將在最內層的巢狀呼叫中列印 1 的那一刻暫停。外部呼叫列印 2 和 3 尚未列印它們的值,因此記憶體中必須存在一些環境,仍然儲存著 n 在一個上下文中繫結到 3、在另一個上下文中繫結到 2,以及在最內層的上下文中繫結到 1 的事實,就像
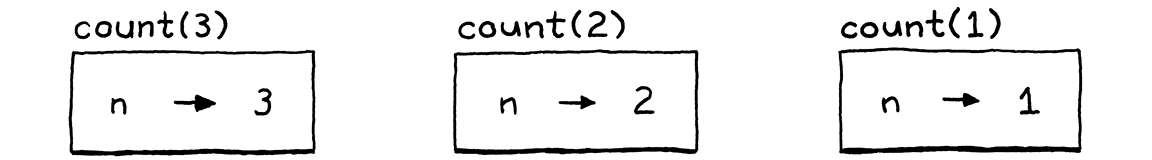
這就是為什麼我們在每次呼叫時,而不是在函式宣告時建立新環境的原因。我們稍早看到的 call() 方法會執行此操作。在呼叫開始時,它會建立一個新環境。然後,它會以鎖步方式走訪參數和引數列表。對於每一對,它會建立一個具有參數名稱的新變數,並將其繫結到引數的值。
因此,對於像這樣的程式
fun add(a, b, c) { print a + b + c; } add(1, 2, 3);
在呼叫 add() 的點上,直譯器會建立類似這樣的內容
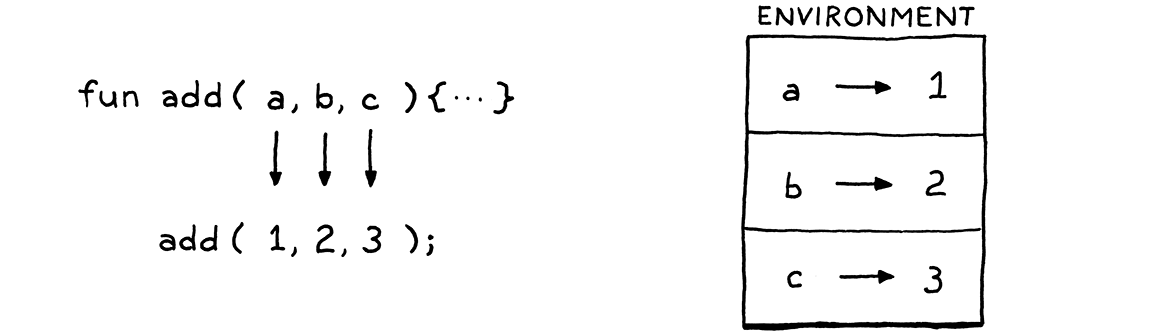
然後,call() 會告知直譯器在這個新的函式本機環境中執行函式的主體。到目前為止,目前的環境是呼叫函式的環境。現在,我們從那裡傳送到我們為函式建立的新參數空間內。
這就是將資料傳遞到函式中所需的一切。藉由在執行主體時使用不同的環境,以相同程式碼呼叫同一個函式可以產生不同的結果。
一旦函式的主體執行完成,executeBlock() 會捨棄該函式本機環境,並還原呼叫點上先前作用中的環境。最後,call() 會傳回 null,這會將 nil 傳回給呼叫者。(我們稍後會新增傳回值。)
在機制上,程式碼非常簡單。走訪幾個列表。繫結一些新變數。呼叫一個方法。但是,在這裡,函式宣告的清晰程式碼變成了一個活生生的調用。這是我整本書中最喜歡的程式碼片段之一。如果您有興趣,可以花點時間來思考一下。
完成?好的。請注意,當我們繫結參數時,我們假設參數和引數列表具有相同的長度。這很安全,因為 visitCallExpr() 會在呼叫 call() 之前檢查arity。它依賴函式回報其arity來執行此操作。
在 LoxFunction() 之後新增
@Override public int arity() { return declaration.params.size(); }
這就是我們大部分的物件表示。既然我們在這裡,我們不妨實作 toString()。
在 LoxFunction() 之後新增
@Override public String toString() { return "<fn " + declaration.name.lexeme + ">"; }
如果使用者決定列印函式值,這會產生更佳的輸出。
fun add(a, b) { print a + b; } print add; // "<fn add>".
10 . 4 . 1直譯函式宣告
我們很快就會回來並改進 LoxFunction,但這足以開始使用。現在我們可以走訪函式宣告。
在 visitExpressionStmt() 之後新增
@Override public Void visitFunctionStmt(Stmt.Function stmt) { LoxFunction function = new LoxFunction(stmt); environment.define(stmt.name.lexeme, function); return null; }
這與我們直譯其他常值運算式的方式類似。我們採用函式語法節點—函式的編譯時期表示—並將其轉換為其執行階段表示。在這裡,它是包裝語法節點的 LoxFunction。
函式宣告與其他常值節點的不同之處在於,宣告也會將產生的物件繫結到新變數。因此,在建立 LoxFunction 之後,我們會在目前環境中建立新的繫結,並將其參考儲存在那裡。
有了這個,我們就可以在 Lox 中定義和呼叫自己的函式了。試試看
fun sayHi(first, last) { print "Hi, " + first + " " + last + "!"; } sayHi("Dear", "Reader");
我不知道你們怎麼想,但我認為這看起來像是一種真正的程式語言。
10 . 5Return 語句
我們可以藉由傳遞參數將資料傳入函式,但我們沒有辦法將結果傳回外部。如果 Lox 像 Ruby 或 Scheme 這樣的面向運算式的語言,主體將是一個運算式,其值隱式地是函式的結果。但是在 Lox 中,函式的主體是一個不產生值的語句列表,因此我們需要專用的語法來發出結果。換句話說,需要 return 語句。我確信您已經猜到語法了。
statement → exprStmt | forStmt | ifStmt | printStmt | returnStmt | whileStmt | block ; returnStmt → "return" expression? ";" ;
我們還有一個—實際上是最後一個—在值得尊敬的 statement 規則下的產生式。return 語句是 return 關鍵字,後面接著一個選用的運算式,並以分號終止。
傳回值是選用的,用於支援從不傳回有用值的函式提前退出。在靜態類型語言中,「void」函式不傳回值,而非 void 函式則傳回值。由於 Lox 是動態類型的,因此沒有真正的 void 函式。編譯器無法阻止您採用呼叫不包含 return 語句的函式的結果值。
fun procedure() { print "don't return anything"; } var result = procedure(); print result; // ?
這表示每個 Lox 函式都必須傳回某些內容,即使它根本不包含 return 語句。我們對此使用 nil,這就是為什麼 LoxFunction 的 call() 實作在結尾傳回 null 的原因。同樣地,如果您省略 return 語句中的值,我們只會將其視為等同於
return nil;
在我們的 AST 產生器中,我們新增一個新節點。
"Print : Expr expression",
在 main() 中
"Return : Token keyword, Expr value",
"Var : Token name, Expr initializer",
它會保留 return 關鍵字標記,以便我們可以使用其位置來回報錯誤,以及正在傳回的值(如果有的話)。我們像其他語句一樣解析它,首先是識別初始關鍵字。
if (match(PRINT)) return printStatement();
在 statement() 中
if (match(RETURN)) return returnStatement();
if (match(WHILE)) return whileStatement();
該分支會到
在 printStatement() 之後新增
private Stmt returnStatement() { Token keyword = previous(); Expr value = null; if (!check(SEMICOLON)) { value = expression(); } consume(SEMICOLON, "Expect ';' after return value."); return new Stmt.Return(keyword, value); }
在擷取先前消耗的 return 關鍵字之後,我們會尋找值運算式。由於許多不同的標記都有可能開始運算式,因此很難判斷是否有傳回值存在。相反地,我們會檢查它是否不存在。由於分號無法開始運算式,如果下一個標記是分號,我們就知道一定沒有值。
10 . 5 . 1從呼叫中傳回
直譯 return 語句很棘手。您可以從函式主體內的任何位置傳回,甚至是深層巢狀在其他語句內。當執行傳回時,直譯器需要從目前所在的任何內容中跳出來,並導致函式呼叫完成,就像某種加強型的控制流程結構一樣。
例如,假設我們正在執行這個程式,並且我們即將執行 return 語句
fun count(n) { while (n < 100) { if (n == 3) return n; // <-- print n; n = n + 1; } } count(1);
Java 呼叫堆疊目前看起來大致如下
Interpreter.visitReturnStmt() Interpreter.visitIfStmt() Interpreter.executeBlock() Interpreter.visitBlockStmt() Interpreter.visitWhileStmt() Interpreter.executeBlock() LoxFunction.call() Interpreter.visitCallExpr()
我們需要從堆疊的頂端一路回到 call()。我不知道你們怎麼想,但對我來說這聽起來像例外狀況。當我們執行 return 語句時,我們將使用例外狀況來解除直譯器,跳過所有包含語句的 visit 方法,回到開始執行主體的程式碼。
我們新 AST 節點的 visit 方法如下所示
在 visitPrintStmt() 之後新增
@Override public Void visitReturnStmt(Stmt.Return stmt) { Object value = null; if (stmt.value != null) value = evaluate(stmt.value); throw new Return(value); }
如果我們有傳回值,我們會評估它,否則,我們會使用 nil。然後,我們取得該值並將其包裝在自訂的例外狀況類別中並擲出它。
建立新檔案
package com.craftinginterpreters.lox; class Return extends RuntimeException { final Object value; Return(Object value) { super(null, null, false, false); this.value = value; } }
這個類別會使用 Java 執行階段例外狀況類別所需的所有裝飾,來包裝傳回值。具有那些 null 和 false 引數的奇怪超級建構函式呼叫會停用我們不需要的一些 JVM 機制。由於我們將例外狀況類別用於控制流程,而不是實際的錯誤處理,因此我們不需要像堆疊追蹤這樣的額外負荷。
我們希望它能一路回溯到函式呼叫開始的地方,也就是 LoxFunction 中的 call() 方法。
arguments.get(i));
}
在 call() 中
取代 1 行
try { interpreter.executeBlock(declaration.body, environment); } catch (Return returnValue) { return returnValue.value; }
return null;
我們將對 executeBlock() 的呼叫包裝在 try-catch 區塊中。當它捕獲到返回例外時,會取出值並將其設為 call() 的返回值。如果它永遠沒有捕獲到這些例外之一,則表示該函式在沒有遇到 return 語句的情況下到達了主體的結尾。在這種情況下,它會隱式返回 nil。
讓我們試試看。我們終於有足夠的能力來支援這個經典範例—一個計算費波那契數的遞迴函式
fun fib(n) { if (n <= 1) return n; return fib(n - 2) + fib(n - 1); } for (var i = 0; i < 20; i = i + 1) { print fib(i); }
這個小程式運用了我們在過去幾個章節中實作的幾乎所有語言功能—表達式、算術、分支、迴圈、變數、函式、函式呼叫、參數綁定和返回。
10.6區域函式和閉包
我們的函式功能相當完整,但還有一個漏洞需要修補。事實上,這個漏洞大到我們需要花費大部分的下一章來封堵它,但我們可以從這裡開始。
LoxFunction 的 call() 實作建立了一個新的環境,在其中繫結函式的參數。當我向您展示該程式碼時,我忽略了一個重點:該環境的父層是什麼?
現在,它始終是 globals,也就是最上層的全域環境。這樣,如果函式主體本身沒有定義識別符,直譯器就可以在全域範圍內尋找它。在費波那契範例中,這就是直譯器如何在函式本身的主體內查詢對 fib 的遞迴呼叫的方式—fib 是一個全域變數。
但請回想一下,在 Lox 中,函式宣告允許在可以繫結名稱的任何位置。這包括 Lox 腳本的最上層,也包括區塊或其他函式的內部。Lox 支援在另一個函式內定義或巢狀於區塊內的區域函式。
考慮這個經典範例
fun makeCounter() { var i = 0; fun count() { i = i + 1; print i; } return count; } var counter = makeCounter(); counter(); // "1". counter(); // "2".
在這裡,count() 使用了 i,它是在包含函式 makeCounter() 的外部宣告的。makeCounter() 返回對 count() 函式的引用,然後它自己的主體完全執行完畢。
同時,最上層的程式碼會調用返回的 count() 函式。這會執行 count() 的主體,該主體會賦值給 i 並讀取 i,即使定義 i 的函式已經退出。
如果您以前從未遇到過具有巢狀函式的語言,這可能看起來很瘋狂,但使用者確實希望它能運作。唉,如果您現在執行它,當 count() 的主體嘗試查詢 i 時,您會在對 counter() 的呼叫中收到未定義變數錯誤。那是因為有效的環境鏈如下所示
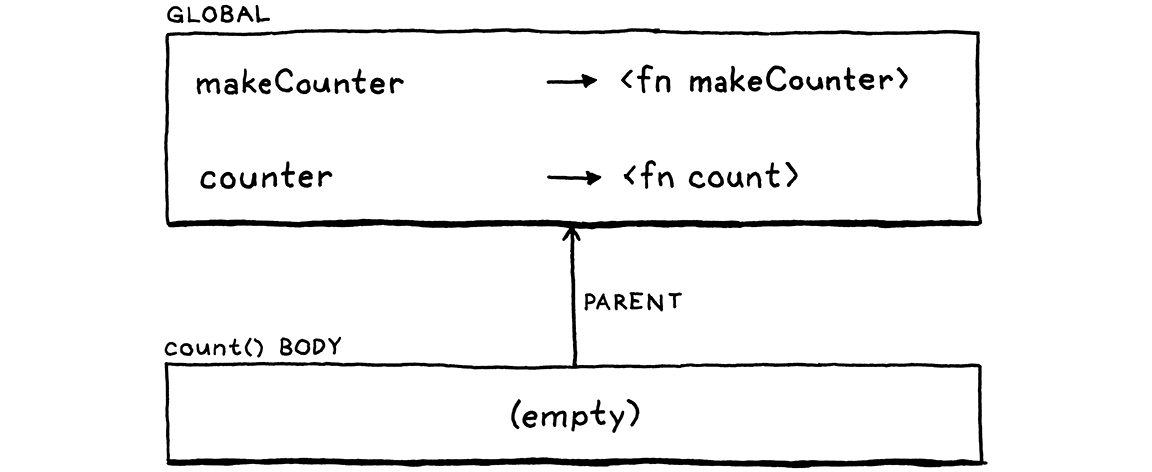
當我們呼叫 count()(透過儲存在 counter 中的引用)時,我們會為函式主體建立一個新的空環境。其父層是全域環境。我們失去了 makeCounter() 的環境,而 i 在其中繫結。
讓我們稍微回到過去。以下是在我們於 makeCounter() 主體內宣告 count() 時的環境鏈
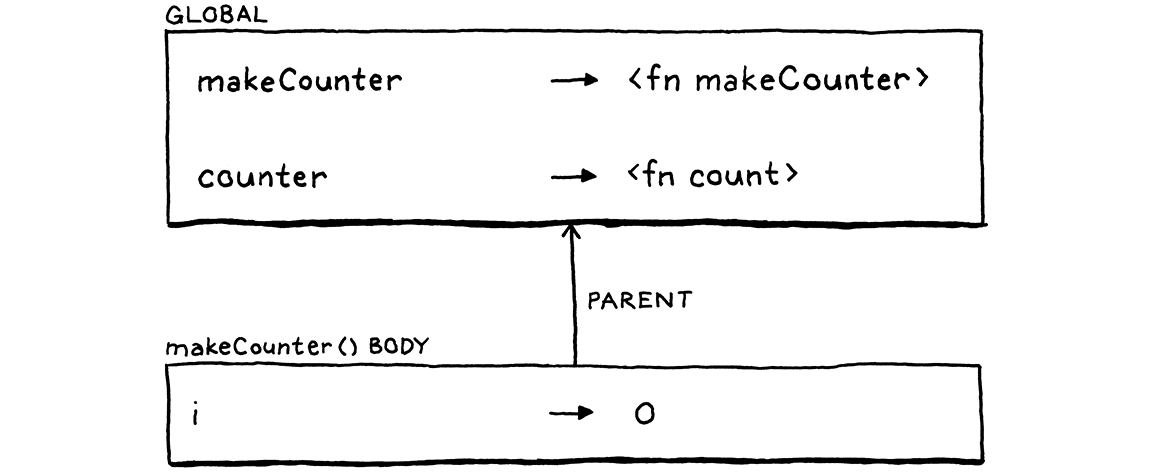
因此,在宣告函式的地方,我們可以看見 i。但當我們從 makeCounter() 返回並退出其主體時,直譯器會捨棄該環境。由於直譯器不會保留 count() 周圍的環境,因此由函式物件本身來保留它。
這個資料結構稱為閉包,因為它「封閉」並保留宣告函式時的周圍變數。自早期的 Lisp 時代以來,閉包就已經存在,而語言駭客已經想出了各種實作它們的方法。對於 jlox,我們將做最簡單且有效的方法。在 LoxFunction 中,我們新增一個欄位來儲存環境。
private final Stmt.Function declaration;
在 class LoxFunction 中
private final Environment closure;
LoxFunction(Stmt.Function declaration) {
我們在建構子中初始化它。
建構子 LoxFunction()
取代 1 行
LoxFunction(Stmt.Function declaration, Environment closure) { this.closure = closure;
this.declaration = declaration;
當我們建立 LoxFunction 時,我們會捕獲目前環境。
public Void visitFunctionStmt(Stmt.Function stmt) {
在 visitFunctionStmt() 中
取代 1 行
LoxFunction function = new LoxFunction(stmt, environment);
environment.define(stmt.name.lexeme, function);
這是宣告函式時作用中的環境,而不是呼叫函式時的環境,這正是我們想要的。它代表函式宣告周圍的詞法範圍。最後,當我們呼叫函式時,我們會使用該環境作為呼叫的父層,而不是直接跳到 globals。
List<Object> arguments) {
在 call() 中
取代 1 行
Environment environment = new Environment(closure);
for (int i = 0; i < declaration.params.size(); i++) {
這會建立一個環境鏈,該環境鏈會從函式的主體通過宣告函式的環境一直延伸到全域範圍。執行階段環境鏈會像我們希望的那樣,與原始程式碼的文字巢狀結構相符。當我們呼叫該函式時,最終結果如下所示
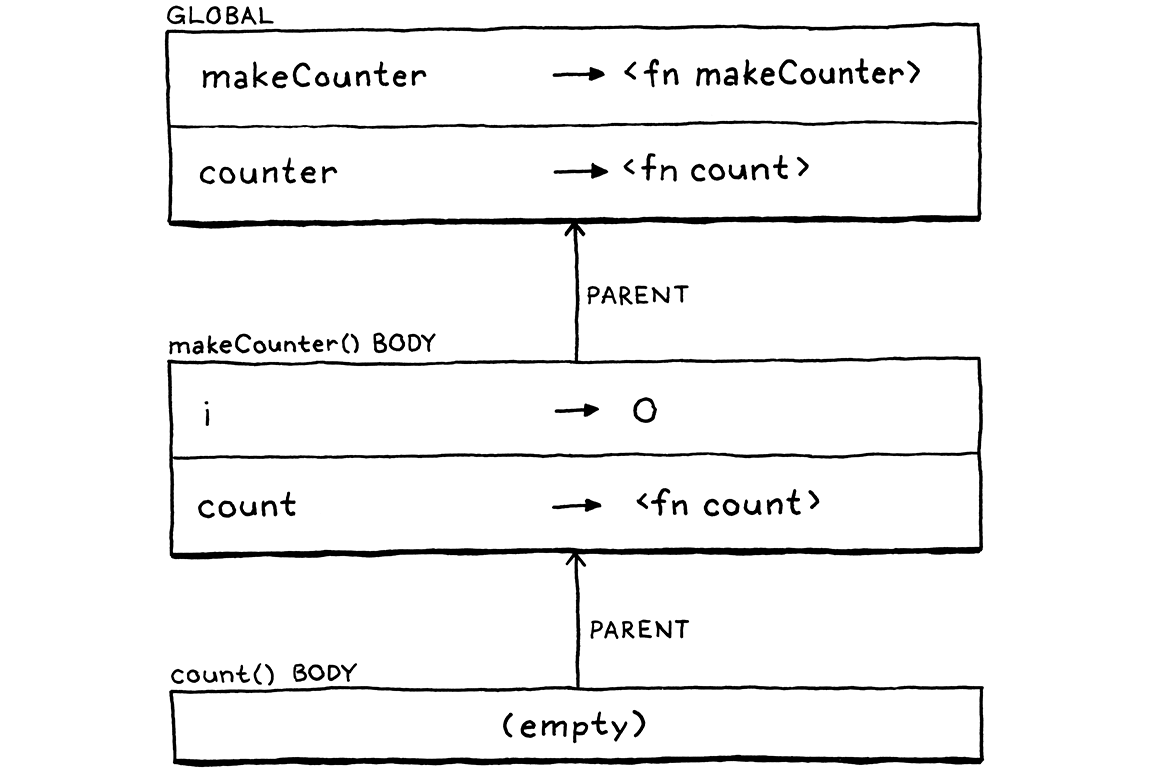
現在,正如您所看到的,直譯器仍然可以在需要時找到 i,因為它位於環境鏈的中間。現在嘗試執行 makeCounter() 範例。它運作了!
函式讓我們可以抽象化、重複使用和組合程式碼。Lox 比以前的初級算術計算器強大得多。唉,在我們急著塞入閉包的過程中,我們讓一點點動態範圍洩漏到直譯器中。在下一章中,我們將更深入地探討詞法範圍,並封堵該漏洞。
挑戰
-
我們的直譯器會仔細檢查傳遞給函式的引數數量是否與其預期的參數數量相符。由於此檢查是在每次呼叫時在執行階段進行的,因此它會產生效能成本。Smalltalk 實作沒有這個問題。為什麼沒有?
-
Lox 的函式宣告語法會執行兩個獨立的操作。它會建立一個函式,並將其繫結到一個名稱。這提高了您確實想要將名稱與函式關聯的常見情況下的可用性。但在函數式風格的程式碼中,您通常想要建立一個函式,以便立即將其傳遞給其他函式或返回它。在這種情況下,它不需要名稱。
鼓勵函數式風格的語言通常支援匿名函式或 lambda—一種在不將其繫結到名稱的情況下建立函式的表達式語法。將匿名函式語法新增至 Lox,以便使其運作
fun thrice(fn) { for (var i = 1; i <= 3; i = i + 1) { fn(i); } } thrice(fun (a) { print a; }); // "1". // "2". // "3".
您如何處理在表達式陳述式中出現的匿名函式表達式的棘手情況
fun () {}; -
這個程式有效嗎?
fun scope(a) { var a = "local"; }
換句話說,函式的參數與其區域變數位於相同範圍內,還是位於外部範圍內?Lox 怎麼做?您熟悉的其他語言呢?您認為語言應該怎麼做?