剖析表達式
語法,連國王都懂得如何控制。莫里哀
本章標誌著本書的第一個主要里程碑。我們許多人都拼湊了正規表達式和子字串操作的混亂組合,以便從一堆文字中提取一些意義。程式碼可能充滿錯誤,而且難以維護。編寫一個真正的剖析器—具有良好的錯誤處理、連貫的內部結構以及能夠穩健地處理複雜語法的能力—被認為是一項罕見且令人印象深刻的技能。在本章中,你將獲得它。
它比你想像的要容易,部分原因是我們在上一章中預先處理了很多困難的工作。你已經熟悉了正式語法。你熟悉語法樹,而且我們有一些 Java 類別來表示它們。剩下的唯一部分就是剖析—將一連串的符記轉換為這些語法樹之一。
一些電腦科學教科書將剖析器視為大事。在 60 年代,電腦科學家—可以理解地厭倦了使用組合語言進行程式設計—開始設計更複雜、對人類友好的語言,如 Fortran 和 ALGOL。唉,對於當時的原始電腦來說,它們並不是非常對機器友好的。
這些先驅們設計的語言,他們甚至不確定如何編寫編譯器,然後進行了開創性的工作,發明了剖析和編譯技術,這些技術可以在那些舊的、微小的機器上處理這些新的、大型的語言。
經典的編譯器書籍讀起來像是對這些英雄及其工具的諂媚傳記。編譯器:原理、技術和工具的封面,上面有一條標有「編譯器設計的複雜性」的龍,被一位手持劍和盾牌,標有「LALR 剖析器產生器」和「語法導向翻譯」的騎士所斬殺。他們誇大了它。
一點點自我恭喜是當之無愧的,但事實是,你不需要了解大部分這些東西就可以為現代機器打造高品質的剖析器。一如既往,我鼓勵你擴展你的教育,並在以後接受它,但本書省略了獎盃櫃。
6 . 1歧義與剖析遊戲
在上一章中,我說你可以像玩遊戲一樣「玩」上下文無關文法,以便產生字串。剖析器反向玩那個遊戲。給定一個字串—一系列符記—我們將這些符記對應到文法中的終端符號,以找出哪些規則可以產生該字串。
「可以」部分很有趣。完全有可能建立一個歧義的文法,其中不同的產生式選擇會導致相同的字串。當你使用文法來產生字串時,這並不重要。一旦有了字串,誰在乎你是如何得到它的?
剖析時,歧義表示剖析器可能會誤解使用者的程式碼。當我們剖析時,我們不僅要確定字串是否是有效的 Lox 程式碼,還要追蹤哪些規則與程式碼的哪些部分匹配,以便我們知道每個符記屬於語言的哪個部分。這是我們在上一章中組裝的 Lox 表達式文法。
expression → literal | unary | binary | grouping ; literal → NUMBER | STRING | "true" | "false" | "nil" ; grouping → "(" expression ")" ; unary → ( "-" | "!" ) expression ; binary → expression operator expression ; operator → "==" | "!=" | "<" | "<=" | ">" | ">=" | "+" | "-" | "*" | "/" ;
這是在該文法中的有效字串

但是有兩種方法可以產生它。其中一種方法是
- 從
expression開始,選擇binary。 - 對於左邊的
expression,選擇NUMBER,並使用6。 - 對於運算符,選擇
"/"。 - 對於右邊的
expression,再次選擇binary。 - 在巢狀的
binary表達式中,選擇3 - 1。
另一種是
- 從
expression開始,選擇binary。 - 對於左邊的
expression,再次選擇binary。 - 在巢狀的
binary表達式中,選擇6 / 3。 - 回到外部的
binary,對於運算符,選擇"-"。 - 對於右邊的
expression,選擇NUMBER,並使用1。
這些會產生相同的字串,但不會產生相同的語法樹
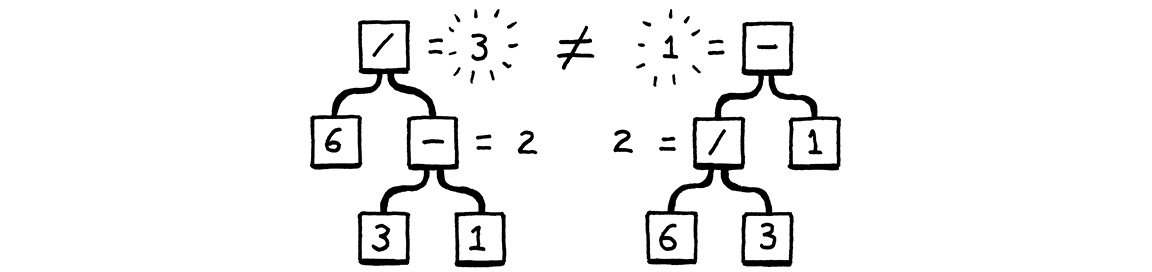
換句話說,文法允許將表達式視為 (6 / 3) - 1 或 6 / (3 - 1)。binary 規則允許運算元以你想要的任何方式巢狀。這反過來會影響評估剖析樹的結果。自從發明黑板以來,數學家解決這種歧義的方式是定義運算符的優先順序和結合性的規則。
-
優先順序決定了在包含不同運算符的表達式中,哪個運算符首先被評估。優先順序規則告訴我們,在上面的範例中,我們先評估
/,然後再評估-。優先順序較高的運算符會在優先順序較低的運算符之前被評估。同樣地,優先順序較高的運算符被認為「結合更緊密」。 -
結合性決定了在相同運算符的一系列運算符中,哪個運算符首先被評估。當運算符是左結合時(想想「從左到右」),左邊的運算符會比右邊的運算符先被評估。由於
-是左結合的,因此此表達式5 - 3 - 1
等同於
(5 - 3) - 1
另一方面,賦值是右結合的。此
a = b = c
等同於
a = (b = c)
如果沒有明確定義的優先順序和結合性,則使用多個運算符的表達式會產生歧義—它可以被剖析為不同的語法樹,這反過來可能會評估出不同的結果。我們將在 Lox 中透過應用與 C 相同的優先順序規則來修正此問題,從最低到最高。
| 名稱 | 運算符 | 結合性 |
| 相等 | == != |
左結合 |
| 比較 | > >=
< <= |
左結合 |
| 項 | - + |
左結合 |
| 因數 | / * |
左結合 |
| 一元 | ! - |
右結合 |
現在,文法將所有表達式類型塞進一個單一的 expression 規則中。相同的規則被用作運算元的非終端符號,這使得文法可以接受任何類型的表達式作為子表達式,無論優先順序規則是否允許。
我們透過分層文法來修正此問題。我們為每個優先順序層級定義一個單獨的規則。
expression → ... equality → ... comparison → ... term → ... factor → ... unary → ... primary → ...
此處的每個規則只會比對其優先順序層級或更高層級的表達式。例如,unary 會比對一元表達式(例如 !negated)或主要表達式(例如 1234)。而且 term 可以比對 1 + 2,也可以比對 3 * 4 / 5。最後的 primary 規則涵蓋了最高優先順序的形式—文字和括號表達式。
我們只需要填寫每個規則的產生式。我們先做簡單的。頂部的 expression 規則會比對任何優先順序層級的任何表達式。由於 equality 具有最低優先順序,如果我們比對該優先順序,則它會涵蓋所有內容。
expression → equality
在優先順序表的另一端,主要表達式包含所有文字和分組表達式。
primary → NUMBER | STRING | "true" | "false" | "nil" | "(" expression ")" ;
一元表達式以一元運算符開始,後接運算元。由於一元運算符可以巢狀—!!true 是一個有效的,如果很奇怪的表達式—運算元本身可以是一元運算符。遞迴規則可以很好地處理此問題。
unary → ( "!" | "-" ) unary ;
但是此規則存在問題。它永遠不會終止。
請記住,每個規則都需要比對該優先順序層級或更高層級的表達式,因此我們也需要允許它比對主要表達式。
unary → ( "!" | "-" ) unary | primary ;
這樣就可以了。
其餘的規則都是二元運算符。我們先從乘法和除法的規則開始
factor → factor ( "/" | "*" ) unary | unary ;
該規則會遞迴以比對左運算元。這使得該規則能夠比對一系列乘法和除法表達式,例如 1 * 2 / 3。將遞迴產生式放在左側,並將 unary 放在右側,可以使規則成為左結合且沒有歧義的。
以上都是正確的,但規則主體中的第一個符號與規則的頭部相同,這表示此產生式是左遞迴。有些剖析技術,包括我們將要使用的技術,在處理左遞迴時會遇到問題。(其他地方的遞迴,例如在 unary 中的遞迴以及 primary 中分組的間接遞迴則不是問題。)
你可以定義許多符合相同語言的文法。如何為特定語言建模的選擇,部分是個人品味問題,部分是實用性的考量。這個規則是正確的,但對於我們打算如何解析它來說並非最佳。我們將使用不同的規則,而不是左遞迴規則。
factor → unary ( ( "/" | "*" ) unary )* ;
我們將因數表達式定義為乘法和除法的扁平序列。這符合與先前規則相同的語法,但更好地反映了我們將編寫以剖析 Lox 的程式碼。我們對所有其他二元運算符優先級別使用相同的結構,從而獲得這個完整的表達式文法
expression → equality ; equality → comparison ( ( "!=" | "==" ) comparison )* ; comparison → term ( ( ">" | ">=" | "<" | "<=" ) term )* ; term → factor ( ( "-" | "+" ) factor )* ; factor → unary ( ( "/" | "*" ) unary )* ; unary → ( "!" | "-" ) unary | primary ; primary → NUMBER | STRING | "true" | "false" | "nil" | "(" expression ")" ;
這個文法比我們之前的文法更複雜,但作為回報,我們消除了先前文法的歧義。這正是我們製作剖析器所需要的。
6. 2遞迴下降剖析
有一整套剖析技術,其名稱大多是「L」和「R」的組合—LL(k)、LR(1)、LALR—以及更多奇特的類型,例如剖析器組合器、Earley 剖析器、調車場演算法和Packrat 剖析。對於我們的第一個直譯器,一種技術就綽綽有餘:遞迴下降。
遞迴下降是建構剖析器最簡單的方法,不需要使用像 Yacc、Bison 或 ANTLR 等複雜的剖析器產生器工具。你只需要簡單的手寫程式碼。不過,不要被它的簡單性所迷惑。遞迴下降剖析器速度快、穩健,並且可以支援複雜的錯誤處理。事實上,GCC、V8(Chrome 中的 JavaScript VM)、Roslyn(以 C# 撰寫的 C# 編譯器)和許多其他重量級的生產語言實作都使用遞迴下降。它很棒。
遞迴下降被認為是由上而下的剖析器,因為它從頂部或最外層的文法規則(這裡的 expression)開始,然後向下進入巢狀子表達式,最後到達語法樹的葉子。這與由下而上的剖析器(如 LR)形成對比,後者從主要表達式開始,將它們組合成越來越大的語法區塊。
遞迴下降剖析器是將文法的規則直接轉換為命令式程式碼的文字翻譯。每個規則都會變成一個函式。規則的主體會轉換為大致如下的程式碼
| 文法符號 | 程式碼表示法 |
| 終端符號 | 用於匹配和消耗 Token 的程式碼 |
| 非終端符號 | 呼叫該規則的函式 |
| | if 或 switch 語句 |
* 或 + | while 或 for 迴圈 |
? | if 語句 |
下降被描述為「遞迴」,因為當文法規則參考自身時—直接或間接—這會轉換為遞迴函式呼叫。
6. 2. 1剖析器類別
每個文法規則都會變成這個新類別內的方法
建立新檔案
package com.craftinginterpreters.lox; import java.util.List; import static com.craftinginterpreters.lox.TokenType.*; class Parser { private final List<Token> tokens; private int current = 0; Parser(List<Token> tokens) { this.tokens = tokens; } }
與掃描器一樣,剖析器消耗扁平的輸入序列,只是現在我們讀取的是 Token 而不是字元。我們儲存 Token 列表,並使用 current 指向急切等待剖析的下一個 Token。
我們現在將直接執行表達式文法,並將每個規則轉換為 Java 程式碼。第一個規則 expression 只是擴展到 equality 規則,因此這很簡單。
在 Parser() 之後新增
private Expr expression() { return equality(); }
每個用於剖析文法規則的方法都會產生該規則的語法樹,並將其傳回給呼叫者。當規則的主體包含非終端符號時—對另一個規則的參考—我們呼叫另一個規則的方法。
等式的規則稍微複雜一點。
equality → comparison ( ( "!=" | "==" ) comparison )* ;
在 Java 中,它變為
在 expression() 之後新增
private Expr equality() { Expr expr = comparison(); while (match(BANG_EQUAL, EQUAL_EQUAL)) { Token operator = previous(); Expr right = comparison(); expr = new Expr.Binary(expr, operator, right); } return expr; }
讓我們逐步執行它。主體中的第一個 comparison 非終端符號會轉換為方法中的第一個 comparison() 呼叫。我們取得該結果並將其儲存在區域變數中。
然後,規則中的 ( ... )* 迴圈會對應到 while 迴圈。我們需要知道何時退出該迴圈。我們可以發現在規則內部,我們必須首先找到 != 或 == Token。因此,如果我們沒有看到其中一個,我們必須完成等式運算符序列。我們使用方便的 match() 方法表達該檢查。
在 equality() 之後新增
private boolean match(TokenType... types) { for (TokenType type : types) { if (check(type)) { advance(); return true; } } return false; }
這會檢查目前的 Token 是否具有任何給定的類型。如果有,它會消耗該 Token 並傳回 true。否則,它會傳回 false 並保持目前的 Token 不變。match() 方法是根據兩個更基本的操作定義的。
如果目前的 Token 是給定的類型,check() 方法會傳回 true。與 match() 不同,它永遠不會消耗 Token,它只會查看它。
在 match() 之後新增
private boolean check(TokenType type) { if (isAtEnd()) return false; return peek().type == type; }
advance() 方法會消耗目前的 Token 並傳回它,類似於我們的掃描器對應的方法如何爬過字元。
在 check() 之後新增
private Token advance() { if (!isAtEnd()) current++; return previous(); }
這些方法會在最後幾個基本操作上停止。
在 advance() 之後新增
private boolean isAtEnd() { return peek().type == EOF; } private Token peek() { return tokens.get(current); } private Token previous() { return tokens.get(current - 1); }
isAtEnd() 會檢查我們是否已用盡要剖析的 Token。peek() 會傳回我們尚未消耗的目前 Token,而 previous() 會傳回最近消耗的 Token。後者更容易使用 match(),然後存取剛匹配的 Token。
這就是我們需要的大部分剖析基礎架構。我們在哪裡?沒錯,所以如果我們在 equality() 中的 while 迴圈內,那麼我們知道我們找到了一個 != 或 == 運算符,並且必須剖析一個等式表達式。
我們取得匹配的運算符 Token,以便我們可以追蹤我們有哪些類型的等式表達式。然後,我們再次呼叫 comparison() 以剖析右側運算元。我們將運算符及其兩個運算元合併到新的 Expr.Binary 語法樹節點中,然後迴圈。對於每次迭代,我們將產生的表達式儲存回相同的 expr 區域變數中。當我們遍歷一系列等式表達式時,這會建立一個二元運算符節點的左關聯巢狀樹。
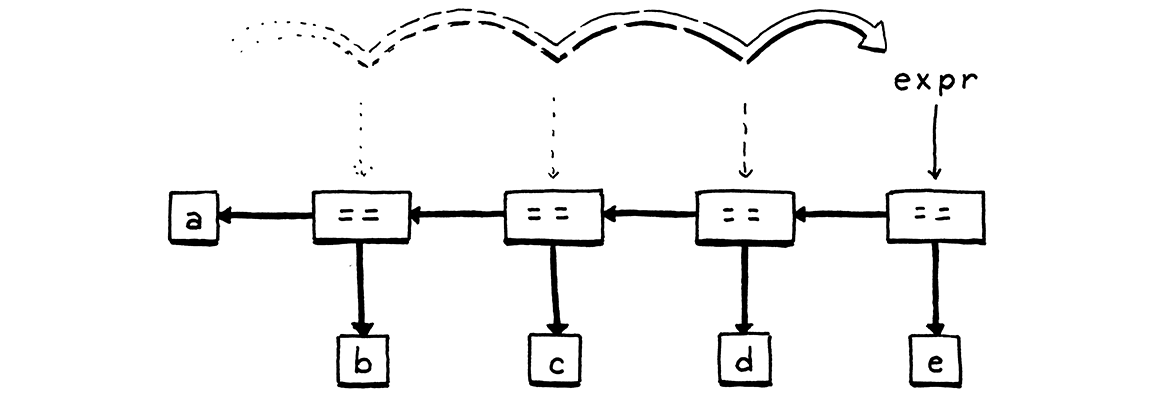
一旦剖析器遇到不是等式運算符的 Token,它就會跳出迴圈。最後,它會傳回表達式。請注意,如果剖析器從未遇到等式運算符,那麼它永遠不會進入迴圈。在這種情況下,equality() 方法會有效地呼叫並傳回 comparison()。透過這種方式,此方法會匹配等式運算符或任何更高優先順序的運算符。
繼續下一個規則 . . .
comparison → term ( ( ">" | ">=" | "<" | "<=" ) term )* ;
翻譯成 Java
在 equality() 之後新增
private Expr comparison() { Expr expr = term(); while (match(GREATER, GREATER_EQUAL, LESS, LESS_EQUAL)) { Token operator = previous(); Expr right = term(); expr = new Expr.Binary(expr, operator, right); } return expr; }
文法規則幾乎與 equality 相同,對應的程式碼也是如此。唯一的差異是我們匹配的運算符的 Token 類型,以及我們呼叫運算元的方法—現在是 term() 而不是 comparison()。其餘兩個二元運算符規則遵循相同的模式。
按優先順序排列,首先是加法和減法
在 comparison() 之後新增
private Expr term() { Expr expr = factor(); while (match(MINUS, PLUS)) { Token operator = previous(); Expr right = factor(); expr = new Expr.Binary(expr, operator, right); } return expr; }
最後,是乘法和除法
在 term() 之後新增
private Expr factor() { Expr expr = unary(); while (match(SLASH, STAR)) { Token operator = previous(); Expr right = unary(); expr = new Expr.Binary(expr, operator, right); } return expr; }
這就是所有二元運算符,使用正確的優先順序和關聯性進行剖析。我們正在向上爬升優先順序層次結構,現在我們已經到達一元運算符。
unary → ( "!" | "-" ) unary | primary ;
此程式碼略有不同。
在 factor() 之後新增
private Expr unary() { if (match(BANG, MINUS)) { Token operator = previous(); Expr right = unary(); return new Expr.Unary(operator, right); } return primary(); }
同樣,我們查看目前的 Token,以了解如何剖析。如果它是 ! 或 -,我們必須有一個一元表達式。在這種情況下,我們取得 Token,然後再次遞迴呼叫 unary() 以剖析運算元。將所有這些封裝到一元表達式語法樹中,我們就完成了。
否則,我們必須已達到最高優先順序層級,主要表達式。
primary → NUMBER | STRING | "true" | "false" | "nil" | "(" expression ")" ;
規則的大多數情況都是單個終端符號,因此剖析很簡單。
在 unary() 之後新增
private Expr primary() { if (match(FALSE)) return new Expr.Literal(false); if (match(TRUE)) return new Expr.Literal(true); if (match(NIL)) return new Expr.Literal(null); if (match(NUMBER, STRING)) { return new Expr.Literal(previous().literal); } if (match(LEFT_PAREN)) { Expr expr = expression(); consume(RIGHT_PAREN, "Expect ')' after expression."); return new Expr.Grouping(expr); } }
有趣的區分支是處理括號的區分支。在我們匹配開頭的 ( 並剖析其中的表達式之後,我們必須找到 ) Token。如果我們沒有找到,那就是錯誤。
6. 3語法錯誤
剖析器實際上具有兩個職責
-
給定一個有效的 Token 序列,產生對應的語法樹。
-
給定一個無效的 Token 序列,偵測任何錯誤並告知使用者他們的錯誤。
別小看第二個任務的重要性!在現代的 IDE 和編輯器中,剖析器會不斷地重新剖析程式碼—通常在使用者還在編輯時就會進行—以便提供語法高亮和自動完成等功能。這表示它會一直遇到不完整、半對半錯的程式碼狀態。
當使用者沒有意識到語法錯誤時,剖析器的責任就是引導他們回到正確的道路上。它回報錯誤的方式是你的語言使用者介面的重要組成部分。良好的語法錯誤處理非常困難。根據定義,程式碼並非處於定義完善的狀態,因此沒有絕對可靠的方法知道使用者真正想寫什麼。剖析器無法讀取你的心靈感應。
當剖析器遇到語法錯誤時,有幾個硬性要求。剖析器必須:
-
偵測並回報錯誤。如果它沒有偵測到錯誤,並將產生的錯誤語法樹傳遞給解譯器,可能會召喚出各種恐怖的東西。
-
避免崩潰或掛起。語法錯誤是生活中不可避免的事實,語言工具必須能夠穩健地面對它們。發生區段錯誤或陷入無限迴圈是不允許的。雖然原始碼可能不是有效的程式碼,但它仍然是剖析器的有效輸入,因為使用者會使用剖析器來學習允許哪些語法。
這些是你想要進入剖析器遊戲的基本條件,但你真正想要的不僅僅於此。一個像樣的剖析器應該:
-
速度快。電腦的速度比剖析器技術剛發明時快了數千倍。需要最佳化剖析器,使其在休息時間內可以處理整個原始碼檔案的日子已經過去了。但程式設計師的期望也同樣快速地提高了,甚至更快。他們期望編輯器在每次按下按鍵後,都能在幾毫秒內重新剖析檔案。
-
回報所有不同的錯誤。在第一個錯誤之後就中止很容易實作,但是如果每次使用者修正他們認為檔案中的一個錯誤時,就會出現一個新的錯誤,這對使用者來說是很惱人的。他們希望看到所有錯誤。
-
最小化連鎖錯誤。一旦找到單一錯誤,剖析器就不再真正知道發生了什麼。它會試圖回到正軌並繼續執行,但如果它感到困惑,可能會回報一連串的幽靈錯誤,這些錯誤並沒有指出程式碼中的其他實際問題。當第一個錯誤被修正後,這些幽靈就會消失,因為它們只反映了剖析器自身的困惑。連鎖錯誤很惱人,因為它們可能會讓使用者以為他們的程式碼處於比實際更糟糕的狀態。
最後兩點之間存在衝突。我們希望回報盡可能多的獨立錯誤,但我們不希望回報那些僅僅是早期錯誤的副作用的錯誤。
剖析器回應錯誤並繼續尋找後續錯誤的方式稱為錯誤復原。這是 60 年代熱門的研究主題。當時,你會將一疊穿孔卡片交給秘書,然後隔天再回來看看編譯器是否成功。在迭代迴圈如此緩慢的情況下,你真的希望一次找到程式碼中的所有錯誤。
如今,當剖析器在你完成輸入之前就已完成時,這就不是什麼問題了。簡單、快速的錯誤復原就可以了。
6 . 3 . 1恐慌模式錯誤復原
在過去所設計的所有復原技術中,最經得起時間考驗的一種叫做—有點令人擔憂—恐慌模式。一旦剖析器偵測到錯誤,它就會進入恐慌模式。它知道至少有一個 token 在某些文法產生式堆疊的中間,其目前狀態下沒有意義。
在它可以回到剖析之前,它需要使它的狀態和即將到來的 token 序列對齊,以便下一個 token 與正在剖析的規則匹配。這個過程稱為同步。
要做到這一點,我們在文法中選擇一些規則來標記同步點。剖析器會跳出任何巢狀產生式,直到回到該規則,以修正其剖析狀態。然後,它會丟棄 token,直到遇到可以在該規則中出現的 token,以此同步 token 流。
在這些丟棄的 token 中隱藏的任何其他實際語法錯誤都不會被回報,但這也表示,任何由於初始錯誤而產生的錯誤連鎖副作用也不會被錯誤地回報,這是一個不錯的權衡。
文法中傳統的同步位置是在語句之間。我們還沒有這些,因此我們在本章中不會實際同步,但我們會為以後做好準備。
6 . 3 . 2進入恐慌模式
在我們開始這次錯誤復原的支線旅行之前,我們正在編寫程式碼來剖析括號中的運算式。在剖析運算式後,剖析器會呼叫 consume() 來尋找右括號 )。最後,這是該方法
在 match() 之後新增
private Token consume(TokenType type, String message) { if (check(type)) return advance(); throw error(peek(), message); }
它類似於 match(),因為它會檢查下一個 token 是否為預期類型。如果是,則它會消耗 token,一切都很順利。如果有其他 token,那麼我們就遇到錯誤了。我們透過呼叫這個來回報它
在 previous() 之後加入
private ParseError error(Token token, String message) { Lox.error(token, message); return new ParseError(); }
首先,這會透過呼叫向使用者顯示錯誤
在 report() 之後加入
static void error(Token token, String message) { if (token.type == TokenType.EOF) { report(token.line, " at end", message); } else { report(token.line, " at '" + token.lexeme + "'", message); } }
這會在給定的 token 上回報錯誤。它會顯示 token 的位置和 token 本身。這在稍後會派上用場,因為我們會在整個解譯器中使用 token 來追蹤程式碼中的位置。
在我們回報錯誤後,使用者知道了他們的錯誤,但剖析器接下來會做什麼?回到 error(),我們建立並回傳 ParseError,這是這個新類別的實例
class Parser {
巢狀於 Parser 類別內
private static class ParseError extends RuntimeException {}
private final List<Token> tokens;
這是一個簡單的哨兵類別,我們用它來展開剖析器。error() 方法回傳錯誤,而不是拋出錯誤,因為我們希望讓剖析器中的呼叫方法決定是否要展開。有些剖析錯誤發生在剖析器不太可能進入奇怪狀態的地方,我們不需要同步。在這些地方,我們只是回報錯誤並繼續前進。
例如,Lox 限制了你可以傳遞給函式的引數數量。如果你傳遞了太多引數,剖析器需要回報該錯誤,但它應該而且可以繼續剖析額外的引數,而不是嚇壞並進入恐慌模式。
但在我們的案例中,語法錯誤夠糟了,我們想要恐慌並同步。丟棄 token 非常容易,但是我們如何同步剖析器自身的狀態呢?
6 . 3 . 3同步遞迴下降剖析器
使用遞迴下降時,剖析器的狀態—它正在識別中間的規則—不會明確地儲存在欄位中。相反,我們使用 Java 自身的呼叫堆疊來追蹤剖析器正在做什麼。每個正在剖析的中間規則都是堆疊上的呼叫框架。為了重設該狀態,我們需要清除這些呼叫框架。
在 Java 中執行此操作的自然方法是例外。當我們想要同步時,我們會拋出該 ParseError 物件。在我們要同步的文法規則的方法中,較高層級會捕捉它。由於我們在語句邊界上同步,我們會在該處捕捉例外。捕捉例外後,剖析器就處於正確的狀態。剩下的就是同步 token 了。
我們想要丟棄 token,直到我們位於下一個語句的開頭。該邊界很容易發現—這是我們選擇它的主要原因之一。在分號之後,我們可能完成了一個語句。大多數語句都以關鍵字開頭—for、if、return、var 等。當下一個 token 是其中任何一個時,我們可能即將開始一個語句。
此方法封裝了該邏輯
在 error() 之後加入
private void synchronize() { advance(); while (!isAtEnd()) { if (previous().type == SEMICOLON) return; switch (peek().type) { case CLASS: case FUN: case VAR: case FOR: case IF: case WHILE: case PRINT: case RETURN: return; } advance(); } }
它會丟棄 token,直到它認為找到了語句邊界。捕捉到 ParseError 後,我們會呼叫它,然後我們希望回到同步狀態。當它運作良好時,我們就會丟棄那些無論如何都可能會導致連鎖錯誤的 token,而現在我們可以從下一個語句開始剖析檔案的其餘部分。
唉,我們看不到此方法的實際運作,因為我們還沒有語句。我們將在接下來的幾章中介紹。目前,如果發生錯誤,我們會恐慌並一路展開到頂端並停止剖析。由於無論如何我們只能剖析單一運算式,因此這沒有太大的損失。
6 . 4連接剖析器
我們現在大致完成了運算式的剖析。我們還需要在另一個地方加入一些錯誤處理。當剖析器逐步執行每個文法規則的剖析方法時,它最終會到達 primary()。如果其中的任何情況都不匹配,則表示我們正在處理一個無法啟動運算式的 token。我們也需要處理該錯誤。
if (match(LEFT_PAREN)) {
Expr expr = expression();
consume(RIGHT_PAREN, "Expect ')' after expression.");
return new Expr.Grouping(expr);
}
在 primary() 中
throw error(peek(), "Expect expression.");
}
這樣一來,剖析器中剩下的就是定義一個初始方法來啟動它。該方法自然就稱為 parse()。
在 Parser() 之後新增
Expr parse() { try { return expression(); } catch (ParseError error) { return null; } }
當我們將語句加入語言時,我們稍後會重新檢視這個方法。目前,它會剖析單一運算式並將其回傳。我們還有一些暫時的程式碼可以退出恐慌模式。語法錯誤復原是剖析器的工作,因此我們不希望 ParseError 例外逸出到解譯器的其餘部分。
當發生語法錯誤時,此方法會回傳 null。這沒關係。剖析器保證不會因為無效語法而崩潰或掛起,但它不保證如果找到錯誤,會回傳一個可用的語法樹。一旦剖析器回報錯誤,就會設定 hadError,並且會跳過後續階段。
最後,我們可以將我們全新的剖析器連結到主要的 Lox 類別並試試看。我們仍然沒有解譯器,因此目前,我們會剖析為語法樹,然後使用上一章的 AstPrinter 類別來顯示它。
刪除舊的程式碼,該程式碼會印出掃描過的詞彙,並用這個取代它
List<Token> tokens = scanner.scanTokens();
在 run() 中
替換 5 行
Parser parser = new Parser(tokens); Expr expression = parser.parse(); // Stop if there was a syntax error. if (hadError) return; System.out.println(new AstPrinter().print(expression));
}
恭喜,你已經跨過門檻了!手寫一個剖析器就真的只有這樣而已。我們會在後面的章節中擴展語法,加入賦值、陳述式和其他東西,但沒有任何一個會比我們這裡處理的二元運算子更複雜。
啟動直譯器並輸入一些表達式。看看它如何正確地處理優先順序和關聯性?用不到 200 行程式碼就能做到,還不錯吧。
挑戰
-
在 C 語言中,程式碼區塊是一種陳述式形式,允許你在預期為單個陳述式的地方打包一系列陳述式。逗號運算子是表達式的類似語法。在預期為單個表達式的地方(函數呼叫的參數列表內除外),可以使用以逗號分隔的一系列表達式。在執行時期,逗號運算子會評估左運算元並捨棄結果。然後它會評估並返回右運算元。
加入對逗號表達式的支援。給它們與 C 語言相同的優先順序和關聯性。寫下語法,然後實作必要的剖析程式碼。
-
同樣地,加入對 C 風格的條件或「三元」運算子
?:的支援。在?和:之間允許什麼優先順序?整個運算子是左關聯還是右關聯? -
加入錯誤產生式以處理每個沒有左運算元的二元運算子。換句話說,偵測出現在表達式開頭的二元運算子。將其回報為錯誤,但也剖析並捨棄具有適當優先順序的右運算元。
設計筆記:邏輯與歷史
假設我們決定在 Lox 中加入位元運算子 & 和 |。我們應該把它們放在優先順序層次的哪個位置?C 語言—以及大多數追隨 C 語言腳步的語言—將它們放在 == 的下面。這被廣泛認為是一個錯誤,因為這意味著像測試標誌這樣的常見操作需要使用括號。
if (flags & FLAG_MASK == SOME_FLAG) { ... } // Wrong. if ((flags & FLAG_MASK) == SOME_FLAG) { ... } // Right.
我們應該為 Lox 修正這個問題,並將位元運算子放在比 C 語言更高的優先順序表中嗎?我們可以採取兩種策略。
你幾乎永遠不會希望將 == 表達式的結果用作位元運算子的運算元。透過使位元綁定更緊密,使用者不需要經常使用括號。因此,如果我們這樣做,並且使用者假設選擇優先順序是為了盡量減少括號,他們很可能會正確地推斷出來。
這種內在一致性使得語言更容易學習,因為使用者必須偶然發現然後糾正的邊緣案例和例外情況更少。這很好,因為在使用者可以使用我們的語言之前,他們必須將所有語法和語意載入他們的腦海中。一種更簡單、更合理的語言是有意義的。
但是,對於許多使用者來說,將我們語言的概念放入他們的大腦中有一個更快的方法—使用他們已經知道的概念。我們語言的許多新使用者會來自其他一種或多種語言。如果我們的語言使用與這些語言相同的語法或語意,使用者需要學習(和取消學習)的東西就會少得多。
這對於語法特別有幫助。你今天可能不記得它了,但在你學習你的第一種程式語言時,程式碼看起來可能是陌生且難以接近的。只有透過艱苦的努力,你才能學會閱讀並接受它。如果你為你的新語言設計一種新穎的語法,你會強迫使用者重新開始這個過程。
利用使用者已經知道的東西是你可以用來簡化語言採用的最強大工具之一。無論如何高估它都無法過分。但這會讓你面臨一個棘手的問題:當使用者都知道的東西有點糟糕時會發生什麼?C 語言的位元運算子優先順序是一個沒有道理的錯誤。但這是一個熟悉的錯誤,數百萬人已經習慣並學會與之共處。
你是要忠於自己語言的內部邏輯而忽略歷史嗎?你是要從一張白紙和基本原則開始嗎?還是要將你的語言編織到豐富的程式設計歷史中,並從他們已經知道的東西開始,讓你的使用者有一個立足點?
這裡沒有完美的答案,只有權衡。你和我顯然偏愛新穎的語言,所以我們自然傾向於燒毀歷史書並開始我們自己的故事。
實際上,最好是充分利用使用者已經知道的東西。讓他們來使用你的語言需要一個很大的躍進。你越能縮小這個鴻溝,就越多人願意跨越它。但你不能總是堅持歷史,否則你的語言不會有任何新的、引人注目的東西來給人們一個跳過去的理由。