程式碼的表示
對於居住在樹林中的人來說,幾乎每種樹都有它的聲音和它的特徵。湯瑪斯·哈代,綠蔭下的樹
在上一章中,我們將原始的原始碼視為一個字串,並將其轉換為稍微高階的表示形式:一系列的 token。在下一章中,我們將要撰寫的解析器將會取得這些 token,並再次將它們轉換為更豐富、更複雜的表示形式。
在我們可以產生該表示形式之前,我們需要先定義它。這就是本章的主題。在此過程中,我們將涵蓋一些關於形式文法的理論,感受函數式和物件導向程式設計之間的差異,複習幾個設計模式,並進行一些元程式設計。
在我們進行所有這些之前,讓我們先專注於主要目標—程式碼的表示形式。它應該讓解析器容易產生,並且讓直譯器容易使用。如果您還沒有撰寫過解析器或直譯器,那麼這些需求並不是很明確。也許您的直覺可以有所幫助。當您扮演人類直譯器的角色時,您的大腦在做什麼?您如何以心理方式評估像這樣的算術表達式
1 + 2 * 3 - 4
因為您了解運算順序—老舊的「請原諒我親愛的莎莉阿姨」之類的東西—您知道乘法是在加法或減法之前評估的。視覺化該優先順序的一種方式是使用樹狀結構。葉節點是數字,內部節點是運算子,每個運算子都有其運算元的的分支。
為了評估算術節點,您需要知道其子樹的數值,因此您必須先評估這些子樹。這意味著從葉節點到根節點—進行後序走訪
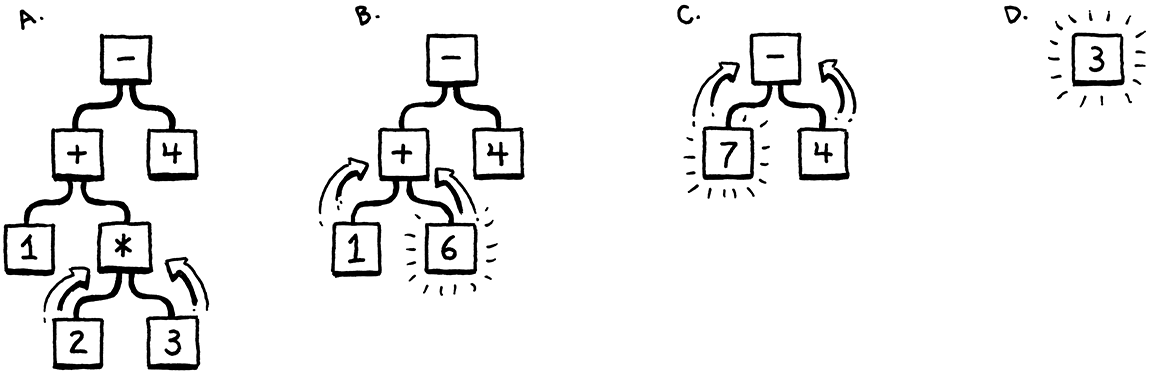
如果我給您一個算術表達式,您可以很容易地繪製出這些樹之一。給定一棵樹,您可以毫不費力地評估它。因此,直觀上來看,我們的程式碼的可行表示形式是一個符合文法結構—運算子巢狀結構—的樹狀結構。
然後,我們需要更精確地了解該文法是什麼。就像上一章中的詞法文法一樣,關於語法文法有很多理論。我們將比掃描時更深入地探討該理論,因為它在直譯器的許多部分中都證明是一個有用的工具。我們從將喬姆斯基層次結構向上移動一個層級開始 . . .
5 . 1上下文無關文法
在上一章中,我們用來定義詞法文法—字元如何分組為 token 的規則—的形式主義被稱為正規語言。這對於我們的掃描器來說很好,它可以發出一連串扁平的 token。但是正規語言的功能不足以處理可以任意深度巢狀的表達式。
我們需要一個更大的錘子,而這個錘子是上下文無關文法 (CFG)。它是形式文法工具箱中次重的工具。形式文法會使用一組稱為「字母」的原子片段。然後,它會定義一組(通常是無限的)「字串」,這些字串「在」文法中。每個字串都是字母表中「字母」的序列。
我之所以使用所有這些引號,是因為當您從詞法文法移至語法文法時,這些術語會變得有些混淆。在我們掃描器的文法中,字母表由個別字元組成,字串是有效的詞素—大致是「單字」。在我們現在談論的語法文法中,我們處於不同的粒度級別。現在,字母表中的每個「字母」都是一個完整的 token,而「字串」是token的序列—一個完整的表達式。
喔。也許表格會有幫助
| 術語 | 詞法文法 | 語法文法 | |
| 「字母表」是 . . . | → | 字元 | Token |
| 「字串」是 . . . | → | 詞素或 token | 表達式 |
| 它由 . . .實作 | → | 掃描器 | 解析器 |
形式文法的工作是指定哪些字串有效,哪些無效。如果我們正在定義英語句子的文法,「雞蛋對早餐來說很好吃」會在文法中,但「好吃的早餐對雞蛋來說」可能不會。
5 . 1 . 1文法的規則
我們如何寫下包含無限多個有效字串的文法?我們顯然無法將它們全部列出。相反,我們會建立一組有限的規則。您可以將它們視為一個可以在兩個方向上「玩」的遊戲。
如果您從規則開始,則可以使用它們來產生文法中的字串。以這種方式建立的字串稱為推導,因為每個字串都是從文法的規則推導而來的。在遊戲的每個步驟中,您都會選擇一個規則並遵循它告訴您執行的操作。形式文法的周圍大部分行話都來自朝這個方向玩遊戲。規則稱為產生式,因為它們會在文法中產生字串。
上下文無關文法中的每個產生式都有一個頭—其名稱—和一個主體,該主體描述其產生的內容。在其純粹的形式中,主體只是一個符號列表。符號有兩種美味的風味
-
終端符號是文法字母中的一個字母。您可以將其視為文字值。在我們正在定義的語法文法中,終端符號是個別的詞素—來自掃描器的 token,例如
if或1234。這些稱為「終端符號」,在「終點」的意義上,因為它們不會導致遊戲中的任何進一步「移動」。您只需產生一個符號。
-
非終端符號是對文法中另一個規則的命名參考。它的意思是「執行該規則並在此處插入它產生的任何內容」。透過這種方式,文法會進行組合。
最後還有一個精修:您可能有多個具有相同名稱的規則。當您到達具有該名稱的非終端符號時,您可以為它選擇任何規則,無論您喜歡哪個。
為了使此具體化,我們需要一種方法來寫下這些產生式規則。人們一直在努力結晶化文法,一直可以追溯到帕尼尼的《Ashtadhyayi》,該書在幾千年前就編纂了梵語文法。在約翰·巴克斯(John Backus)及其公司需要一個用於指定 ALGOL 58 的表示法並提出 巴科斯-諾爾範式 (BNF) 之前,沒有太大的進展。從那時起,幾乎每個人都使用某種 BNF 變體,並根據自己的喜好進行調整。
我嘗試提出一些簡潔的東西。每個規則都是一個名稱,後跟一個箭頭 (→),後跟一個符號序列,最後以分號 (;) 結尾。終端符號是用引號括起來的字串,非終端符號是小寫單字。
使用該語法,這是早餐菜單的文法
breakfast → protein "with" breakfast "on the side" ; breakfast → protein ; breakfast → bread ; protein → crispiness "crispy" "bacon" ; protein → "sausage" ; protein → cooked "eggs" ; crispiness → "really" ; crispiness → "really" crispiness ; cooked → "scrambled" ; cooked → "poached" ; cooked → "fried" ; bread → "toast" ; bread → "biscuits" ; bread → "English muffin" ;
我們可以使用此文法來產生隨機早餐。讓我們玩一輪,看看它是如何運作的。按照歷史悠久的慣例,遊戲從文法中的第一個規則開始,這裡為 breakfast。該規則有三個產生式,我們隨機選擇第一個。我們產生的字串如下所示
protein "with" breakfast "on the side"
我們需要展開第一個非終端符號 protein,因此我們為它選擇一個產生式。讓我們選擇
protein → cooked "eggs" ;
接下來,我們需要一個 cooked 的產生式,因此我們選擇 "poached"。這是一個終端符號,因此我們將其加入。現在,我們的字串如下所示
"poached" "eggs" "with" breakfast "on the side"
下一個非終端符號再次為 breakfast。我們選擇的第一個 breakfast 產生式遞迴地指回 breakfast 規則。文法中的遞迴是一個很好的跡象,表示正在定義的語言是上下文無關的,而不是正規的。特別是,當遞迴非終端符號在兩側都有產生式時,暗示該語言不是正規的。
我們可以重複選擇 breakfast 的第一個產生式,產生各種各樣的早餐,例如「培根配香腸配炒蛋配培根 . . . 」。但我們不會這樣做。這次我們將選擇 bread。有三條關於它的規則,每條規則都只包含一個終端符號。我們將選擇「英式鬆餅」。
這樣一來,字串中的每個非終端符號都已被展開,直到它最終僅包含終端符號,而我們剩餘的內容是
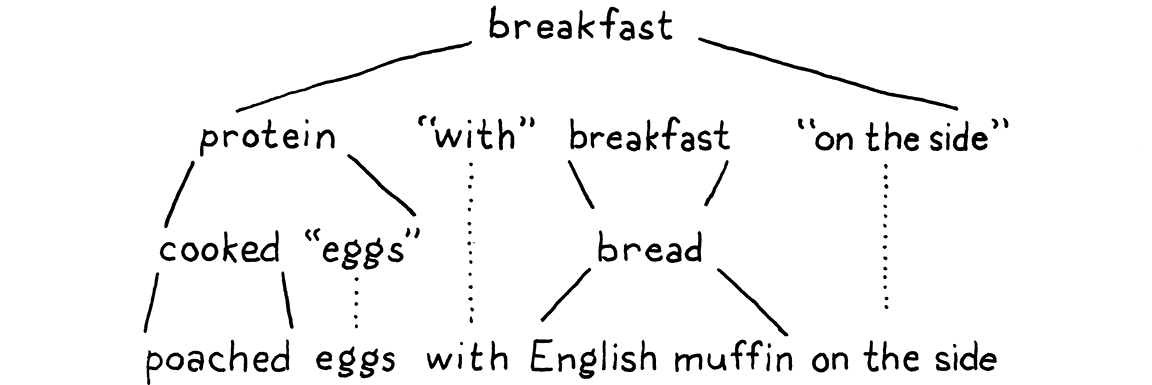
加入一些火腿和荷蘭醬,您就得到了班尼迪克蛋。
每當我們遇到具有多個產生式的規則時,我們都會隨意選擇一個。這種彈性讓少量的文法規則可以編碼組合更大的字串集合。一個規則可以參考自身—直接或間接—的事實使其更加強大,使我們能夠將無限數量的字串打包到有限的文法中。
5 . 1 . 2增強我們的表示法
將無限的字串集合塞入少量的規則中非常棒,但讓我們更進一步。我們的表示法有效,但很乏味。因此,像任何優秀的語言設計師一樣,我們將在頂部撒上一些語法糖—一些額外的便利表示法。除了終端符號和非終端符號之外,我們還將允許規則主體中使用其他幾種表達式
-
為了避免每次想為同一個規則新增產生式時都要重複規則名稱,我們會允許使用管道符號 (
|) 來分隔一系列的產生式。bread → "toast" | "biscuits" | "English muffin" ;
-
此外,我們也會允許使用括號來進行分組,並在括號內使用
|來從一個產生式中間的一系列選項中選擇一個。protein → ( "scrambled" | "poached" | "fried" ) "eggs" ;
-
使用遞迴來支援符號的重複序列具有某種吸引人的純粹性,但是每次想要迴圈時都建立一個獨立的命名子規則有點麻煩。因此,我們也使用後綴
*來允許前一個符號或群組重複零次或多次。crispiness → "really" "really"* ;
-
後綴
+類似,但要求前面的產生式至少出現一次。crispiness → "really"+ ;
-
後綴
?用於可選的產生式。它前面的項目可以出現零次或一次,但不能更多次。breakfast → protein ( "with" breakfast "on the side" )? ;
有了這些語法上的便利,我們的早餐文法可以簡化為
breakfast → protein ( "with" breakfast "on the side" )? | bread ; protein → "really"+ "crispy" "bacon" | "sausage" | ( "scrambled" | "poached" | "fried" ) "eggs" ; bread → "toast" | "biscuits" | "English muffin" ;
還不錯,我希望如此。如果您習慣使用 grep 或在文字編輯器中使用正規表示式,那麼大多數標點符號應該都很熟悉。主要的區別在於此處的符號代表整個符號(token),而不是單個字元。
在本書的其餘部分,我們將使用這種表示法來精確描述 Lox 的文法。當您從事程式語言的工作時,您會發現上下文無關文法(使用這種表示法或 EBNF 或其他表示法)有助於您具體化您的非正式語法設計概念。它們也是與其他語言駭客溝通語法的便捷媒介。
我們為 Lox 定義的規則和產生式也是我們將要實現的樹狀資料結構的指南,該資料結構用於表示記憶體中的程式碼。在我們可以做到這一點之前,我們需要 Lox 的實際文法,或者至少足以讓我們開始。
5. 1 . 3Lox 表達式的文法
在上一章中,我們一舉完成了 Lox 的整個詞彙文法。每個關鍵字和標點符號都在那裡。語法文法比較大,而且在我們實際啟動並執行直譯器之前,要逐步完成整個文法實在是太無聊了。
相反地,我們將在接下來的幾章中處理該語言的一個子集。一旦我們表示、解析和解釋了這個迷你語言,那麼後面的章節將逐步為其新增新的功能,包括新的語法。現在,我們將只關注少數幾個表達式
-
字面值。 數字、字串、布林值和
nil。 -
一元表達式。 前綴
!執行邏輯非運算,以及-否定數字。 -
二元表達式。 我們所熟悉並喜愛的算術中綴運算子(
+、-、*、/)和邏輯運算子(==、!=、<、<=、>、>=)。 -
括號。 一對
(和)包裹著一個表達式。
這為我們提供了足夠的表達式語法,例如
1 - (2 * 3) < 4 == false
使用我們方便的新表示法,以下是這些的文法
expression → literal | unary | binary | grouping ; literal → NUMBER | STRING | "true" | "false" | "nil" ; grouping → "(" expression ")" ; unary → ( "-" | "!" ) expression ; binary → expression operator expression ; operator → "==" | "!=" | "<" | "<=" | ">" | ">=" | "+" | "-" | "*" | "/" ;
這裡有一點額外的元語法。除了用於匹配確切語素的引號字串之外,我們還將單個語素的終端符號 CAPITALIZE,其文本表示可能會有所不同。NUMBER 是任何數字字面值,STRING 是任何字串字面值。稍後,我們將對 IDENTIFIER 執行相同的操作。
這個文法實際上是模稜兩可的,當我們開始解析它時就會看到。但它現在夠用了。
5. 2實作語法樹
最後,我們要開始編寫一些程式碼了。這個小的表達式文法是我們的骨架。由於文法是遞迴的—請注意 grouping、unary 和 binary 如何都回指 expression—我們的資料結構將形成一棵樹。由於此結構表示我們語言的語法,因此它被稱為語法樹。
我們的掃描器使用單個 Token 類來表示各種語素。為了區分不同的種類—想想數字 123 與字串 "123"—我們包含了一個簡單的 TokenType 列舉。語法樹不是那麼同質的。一元表達式有一個運算元,二元表達式有兩個,而字面值沒有。
我們可以將所有內容合併到一個具有任意子清單的單個 Expression 類中。有些編譯器會這樣做。但我喜歡充分利用 Java 的型別系統。因此,我們將為表達式定義一個基底類別。然後,對於每一種表達式—expression 下的每個產生式—我們建立一個子類別,該子類別具有特定於該規則的非終端欄位。這樣,如果我們嘗試存取一元表達式的第二個運算元,就會收到編譯錯誤。
像這樣
package com.craftinginterpreters.lox; abstract class Expr { static class Binary extends Expr { Binary(Expr left, Token operator, Expr right) { this.left = left; this.operator = operator; this.right = right; } final Expr left; final Token operator; final Expr right; } // Other expressions... }
Expr 是所有表達式類別繼承的基底類別。正如您從 Binary 中看到的那樣,子類別是巢狀在其中的。這在技術上沒有必要,但它讓我們可以將所有類別塞進單個 Java 檔案中。
5. 2 . 1迷失方向的物件
您會注意到,與 Token 類別非常相似,這裡沒有任何方法。這是一個啞巴結構。型別良好,但僅僅是一袋數據。這在像 Java 這樣的物件導向語言中感覺很奇怪。類別不應該做事嗎?
問題是這些樹類別不屬於任何單一網域。它們應該具有用於建立樹的解析方法嗎?還是應該具有用於消耗樹的直譯方法?樹橫跨這些領域之間的邊界,這意味著它們實際上不屬於任何一個。
事實上,這些型別的存在是為了使剖析器和直譯器能夠溝通。這適用於那些只是資料而沒有相關行為的型別。這種風格在 Lisp 和 ML 等函數式語言中非常自然,在這些語言中,所有資料都與行為分開,但在 Java 中感覺很奇怪。
函數式程式設計愛好者現在正跳起來大喊「看!物件導向語言不適合直譯器!」我不會走那麼遠。您會記得掃描器本身非常適合物件導向。它具有所有可變的狀態來追蹤它在原始碼中的位置、一組定義完善的公開方法和一些私有輔助函式。
我的感覺是,直譯器的每個階段或部分都可以在物件導向風格中很好地工作。在它們之間流動的資料結構是剝奪了行為的。
5. 2 . 2元程式設計樹
Java 可以表達無行為的類別,但我不會說它特別擅長這方面。將三個欄位塞入物件的 11 行程式碼相當乏味,當我們全部完成時,我們將會有 21 個這樣的類別。
我不想浪費您的時間或我的筆墨來寫下所有這些。實際上,每個子類別的本質是什麼?一個名稱和一個型別化欄位的清單。就這樣。我們是聰明的語言駭客,對吧?讓我們自動化。
我們不會費力地手寫每個類別定義、欄位宣告、建構函式和初始化器,而是會組合一個腳本來為我們完成這項工作。它具有每個樹型別的描述—其名稱和欄位—並且它會印出定義具有該名稱和狀態的類別所需的 Java 程式碼。
此腳本是一個小型 Java 命令列應用程式,會產生一個名為「Expr.java」的檔案
建立新檔案
package com.craftinginterpreters.tool; import java.io.IOException; import java.io.PrintWriter; import java.util.Arrays; import java.util.List; public class GenerateAst { public static void main(String[] args) throws IOException { if (args.length != 1) { System.err.println("Usage: generate_ast <output directory>"); System.exit(64); } String outputDir = args[0]; } }
請注意,此檔案位於不同的套件中,.tool 而不是 .lox。此腳本不是直譯器本身的一部分。這是一個工具,我們,也就是在直譯器上工作的開發人員,自己執行它以產生語法樹類別。完成後,我們將「Expr.java」視為實作中的任何其他檔案。我們只是在自動化該檔案的撰寫方式。
為了產生類別,它需要具有每個型別及其欄位的一些描述。
String outputDir = args[0];
在 main() 中
defineAst(outputDir, "Expr", Arrays.asList( "Binary : Expr left, Token operator, Expr right", "Grouping : Expr expression", "Literal : Object value", "Unary : Token operator, Expr right" ));
}
為了簡潔起見,我將表達式型別的描述塞進字串中。每個字串都是類別的名稱,後接 : 和欄位的清單,以逗號分隔。每個欄位都有一個型別和一個名稱。
defineAst() 需要做的第一件事是輸出基礎 Expr 類別。
在 main() 之後新增
private static void defineAst( String outputDir, String baseName, List<String> types) throws IOException { String path = outputDir + "/" + baseName + ".java"; PrintWriter writer = new PrintWriter(path, "UTF-8"); writer.println("package com.craftinginterpreters.lox;"); writer.println(); writer.println("import java.util.List;"); writer.println(); writer.println("abstract class " + baseName + " {"); writer.println("}"); writer.close(); }
當我們呼叫此方法時,baseName 是「Expr」,它既是類別的名稱,也是其輸出的檔案的名稱。我們將其作為引數傳遞,而不是對名稱進行硬式編碼,因為稍後我們將為語句新增一個獨立的類別系列。
在基底類別內部,我們定義每個子類別。
writer.println("abstract class " + baseName + " {");
在 defineAst() 中
// The AST classes. for (String type : types) { String className = type.split(":")[0].trim(); String fields = type.split(":")[1].trim(); defineType(writer, baseName, className, fields); }
writer.println("}");
該程式碼反過來呼叫
在 defineAst() 之後新增
private static void defineType( PrintWriter writer, String baseName, String className, String fieldList) { writer.println(" static class " + className + " extends " + baseName + " {"); // Constructor. writer.println(" " + className + "(" + fieldList + ") {"); // Store parameters in fields. String[] fields = fieldList.split(", "); for (String field : fields) { String name = field.split(" ")[1]; writer.println(" this." + name + " = " + name + ";"); } writer.println(" }"); // Fields. writer.println(); for (String field : fields) { writer.println(" final " + field + ";"); } writer.println(" }"); }
好了。所有冗長的 Java 樣板程式碼都完成了。它在類別主體中宣告每個欄位。它為類別定義了一個建構子,其參數對應每個欄位,並在主體中初始化它們。
現在編譯並執行這個 Java 程式,它會噴出一個新的「.java」檔案,其中包含幾十行程式碼。這個檔案很快就會變得更長。
5 . 3處理樹狀結構
請暫時發揮一下想像力。即使我們還沒到那一步,也請思考一下直譯器將如何處理語法樹。Lox 中的每一種表達式在執行時的行為都不同。這表示直譯器需要選擇不同的程式碼區塊來處理每種表達式類型。使用詞法符號時,我們可以簡單地根據 TokenType 進行切換。但是,我們沒有語法樹的「類型」列舉,只有每個語法樹各自的 Java 類別。
我們可以編寫一個很長的類型測試鏈
if (expr instanceof Expr.Binary) { // ... } else if (expr instanceof Expr.Grouping) { // ... } else // ...
但是所有這些循序類型測試都很慢。名稱按字母順序靠後的表達式類型,執行時間會更長,因為它們會在找到正確的類型之前,經過更多的 if 條件判斷。這不是我認為優雅的解決方案。
我們有一系列的類別,而且我們需要將一段行為與每個類別關聯起來。在 Java 這樣的物件導向語言中,自然的解決方案是將這些行為放入類別本身的方法中。我們可以在 Expr 上新增一個抽象的 interpret() 方法,然後每個子類別都會實作該方法來解釋自己。
對於小型專案來說,這沒問題,但它難以擴展。就像我之前提到的,這些樹狀類別跨越了多個領域。至少,剖析器和直譯器都會使用它們。正如你稍後會看到的,我們需要對它們進行名稱解析。如果我們的語言是靜態型別的,我們還會有一個型別檢查階段。
如果我們在表達式類別中為每個這些操作新增實例方法,那就會將許多不同的領域混在一起。這違反了關注點分離原則,並導致難以維護的程式碼。
5 . 3 . 1表達式問題
這個問題比乍看之下更為基本。我們有一些類型,以及一些高階操作,例如「解釋」。對於每對類型和操作,我們都需要一個特定的實作。想像一個表格
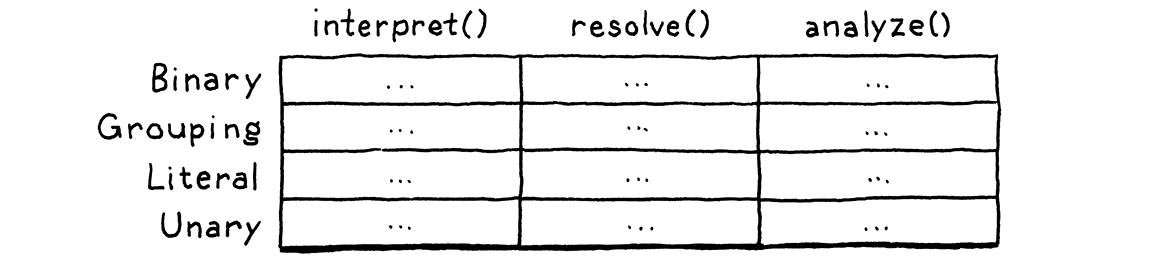
列是類型,而行是操作。每個單元格代表在該類型上實作該操作的獨特程式碼。
像 Java 這樣的物件導向語言假設同一列中的所有程式碼自然地結合在一起。它認為你對某個類型所做的所有事情可能彼此相關,並且該語言可以讓你輕鬆地將它們定義為同一類別內的方法。
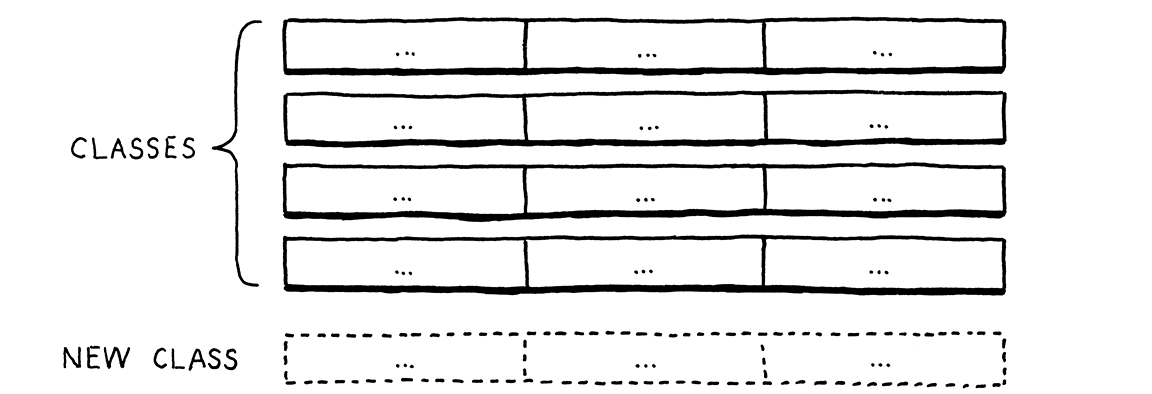
這使得新增新列來擴展表格變得很容易。只需定義一個新的類別。不需要修改現有的程式碼。但是,想像一下,如果你想要新增一個新的操作—一個新的行。在 Java 中,這表示要打開每個現有的類別並在其中新增一個方法。
在 ML 系列中的函數式程式設計範式語言則將其反轉。在那裡,你沒有帶方法的類別。類型和函數完全不同。要為許多不同的類型實作操作,你可以定義一個單一的函數。在該函數的主體中,你會使用模式匹配—一種基於類型的進階 switch 語法—在一個地方實作每種類型的操作。
這使得新增新操作變得微不足道—只需定義另一個對所有類型進行模式匹配的函數。
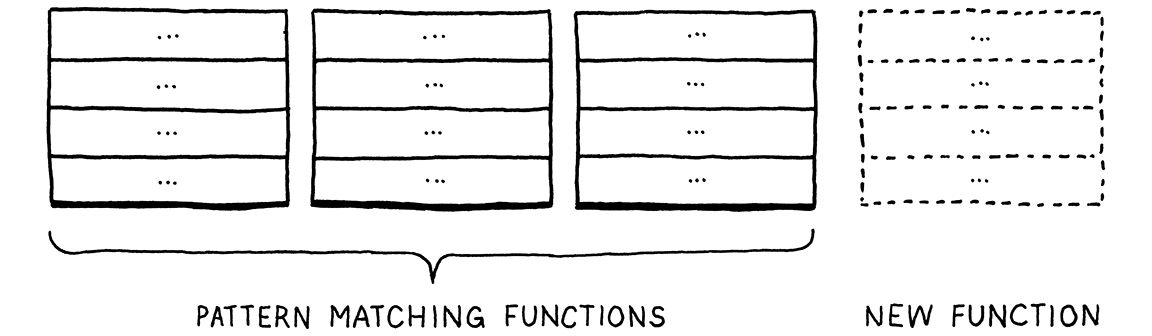
但是,反過來說,新增一個新類型就很困難。你必須返回並在所有現有函數中的所有模式匹配中新增一個新的 case。
每種風格都有一定的「粒度」。這就是範式名稱的字面意思—物件導向語言希望你沿著類型的列定位程式碼。函數式語言則鼓勵你將每行的程式碼匯集到一個函數中。
許多聰明的語言專家注意到,這兩種風格都無法輕鬆地將行和列新增到表格中。他們將這個困難稱為「表達式問題」,因為—就像我們現在一樣—他們第一次遇到這個問題是在試圖找出在編譯器中對表達式語法樹節點進行建模的最佳方法時。
人們已經使用各種語言特性、設計模式和程式設計技巧來嘗試解決這個問題,但還沒有完美的語言能夠徹底解決它。同時,我們能做的最好的事情是嘗試選擇一種語言,其定位符合我們正在編寫的程式中的自然架構接縫。
物件導向對於我們直譯器的許多部分來說都很好用,但是這些樹狀類別與 Java 的風格格格不入。幸運的是,我們可以運用一種設計模式來解決它。
5 . 3 . 2訪問者模式
訪問者模式是《設計模式》中最容易被誤解的模式,當你看到過去幾十年軟體架構的過度發展時,這真的說明了一些問題。
問題始於術語。該模式不是關於「訪問」,而且其中的「accept」方法也沒有喚起任何有用的圖像。許多人認為該模式與遍歷樹有關,但事實並非如此。我們將在一組類似樹狀的類別上使用它,但這是一個巧合。正如你將看到的,該模式也可以在單一物件上運作。
訪問者模式實際上是關於在物件導向程式設計語言中近似函數式程式設計風格。它讓我們可以輕鬆地向該表格新增新的行。我們可以在一個地方定義一組類型上新操作的所有行為,而無需修改類型本身。它透過添加一個間接層來解決我們在電腦科學中幾乎所有問題的方式來做到這一點。
在將其應用於自動產生的 Expr 類別之前,我們先來看一個更簡單的範例。假設我們有兩種糕點:法式甜甜圈和 cruller。
abstract class Pastry { } class Beignet extends Pastry { } class Cruller extends Pastry { }
我們希望能夠定義新的糕點操作—烹飪它們、食用它們、裝飾它們等等—而無需每次都在每個類別中新增一個新的方法。以下是我們的做法。首先,我們定義一個單獨的介面。
interface PastryVisitor { void visitBeignet(Beignet beignet); void visitCruller(Cruller cruller); }
可以在糕點上執行的每個操作都是一個新的類別,它實作該介面。它具有每種類型糕點的具體方法。這使得對兩種型別的操作程式碼都緊密地放在一個類別中。
給定一些糕點,我們如何根據其類型將其路由到訪問者上的正確方法?多型性來解救!我們將此方法新增到 Pastry 中
abstract class Pastry {
abstract void accept(PastryVisitor visitor);
}
每個子類別都會實作它。
class Beignet extends Pastry {
@Override void accept(PastryVisitor visitor) { visitor.visitBeignet(this); }
}
還有
class Cruller extends Pastry {
@Override void accept(PastryVisitor visitor) { visitor.visitCruller(this); }
}
要在糕點上執行操作,我們呼叫其 accept() 方法,並傳入我們要執行的操作的訪問者。糕點—特定子類別覆寫的 accept() 實作—會反過來呼叫訪問者上的適當的 visit 方法,並將自己傳遞給它。
這就是這個技巧的核心所在。它讓我們可以使用糕點類別上的多型分派,以選擇訪問者類別上的適當方法。在表格中,每個糕點類別是一列,但是如果你查看單一訪問者的所有方法,它們會形成一行。
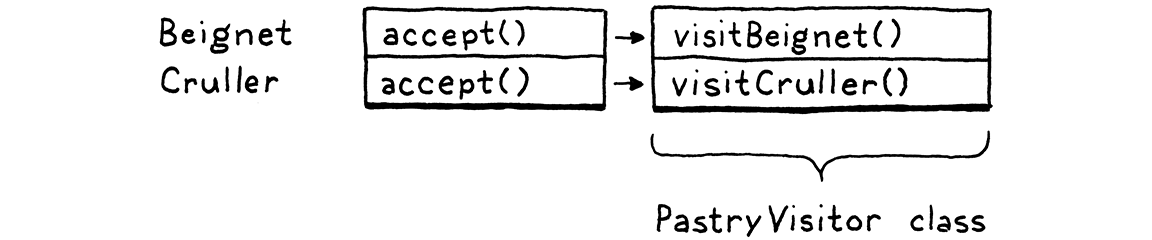
我們為每個類別新增了一個 accept() 方法,並且我們可以使用它來處理任意數量的訪問者,而無需再次修改糕點類別。這是一個聰明的模式。
5 . 3 . 3表達式的訪問者
好的,讓我們將其融入我們的表達式類別中。我們也會稍微改進該模式。在糕點範例中,visit 和 accept() 方法不返回任何值。實際上,訪問者通常希望定義產生值的操作。但是 accept() 的返回類型應該是什麼?我們不能假設每個訪問者類別都希望產生相同的類型,因此我們將使用泛型來讓每個實作填入返回類型。
首先,我們定義訪問者介面。同樣,我們將其巢狀於基礎類別中,以便將所有內容放在一個檔案中。
writer.println("abstract class " + baseName + " {");
在 defineAst() 中
defineVisitor(writer, baseName, types);
// The AST classes.
該函式會產生訪問者介面。
在 defineAst() 之後新增
private static void defineVisitor( PrintWriter writer, String baseName, List<String> types) { writer.println(" interface Visitor<R> {"); for (String type : types) { String typeName = type.split(":")[0].trim(); writer.println(" R visit" + typeName + baseName + "(" + typeName + " " + baseName.toLowerCase() + ");"); } writer.println(" }"); }
在這裡,我們迭代所有子類別,並為每個子類別宣告一個 visit 方法。當我們稍後定義新的表達式類型時,這將自動包含它們。
在基礎類別內部,我們定義抽象的 accept() 方法。
defineType(writer, baseName, className, fields);
}
在 defineAst() 中
// The base accept() method.
writer.println();
writer.println(" abstract <R> R accept(Visitor<R> visitor);");
writer.println("}");
最後,每個子類別都會實作該方法,並針對其自身的類型呼叫正確的 visit 方法。
writer.println(" }");
在 defineType() 中
// Visitor pattern.
writer.println();
writer.println(" @Override");
writer.println(" <R> R accept(Visitor<R> visitor) {");
writer.println(" return visitor.visit" +
className + baseName + "(this);");
writer.println(" }");
// Fields.
完成了。現在我們可以在表達式上定義操作,而無需修改類別或我們的產生器腳本。編譯並執行此產生器腳本以輸出更新後的「Expr.java」檔案。它包含一個產生的 Visitor 介面和一組支援使用它的 Visitor 模式的表達式節點類別。
在結束這冗長的章節之前,讓我們實作該 Visitor 介面,並看看該模式的實際運作。
5.4一個(不太)美觀的印表機
當我們偵錯我們的剖析器和直譯器時,查看已剖析的語法樹並確保其具有我們期望的結構通常很有用。我們可以在偵錯工具中檢查它,但這可能很麻煩。
相反,我們希望有一些程式碼,在給定語法樹的情況下,產生一個明確的字串表示。將樹轉換為字串有點像是剖析器的相反操作,並且當目標是產生原始語言中有效的語法字串時,通常稱為「美觀列印」。
這不是我們在這裡的目標。我們希望字串非常明確地顯示樹的巢狀結構。如果我們嘗試偵錯的是運算子優先順序是否正確處理,則傳回 1 + 2 * 3 的印表機並不是很有幫助。我們想知道 + 或 * 是否位於樹的頂部。
為此,我們產生的字串表示不會是 Lox 語法。相反,它看起來很像 Lisp。每個表達式都明確地用括號括起來,並且所有子表達式和符號都包含在其中。
給定像這樣的語法樹
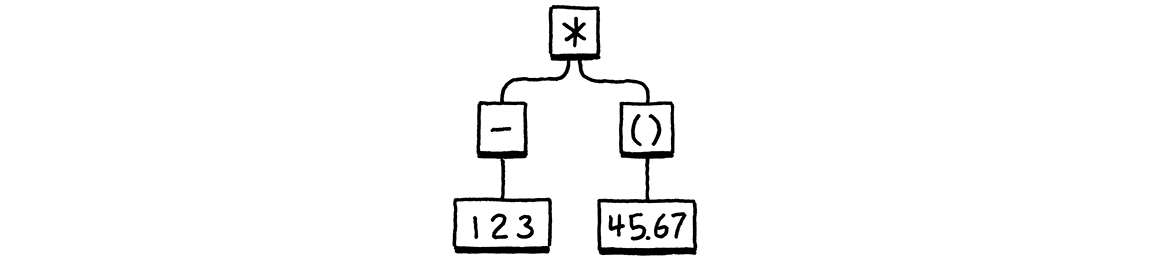
它會產生
(* (- 123) (group 45.67))
並非完全「美觀」,但它確實明確地顯示了巢狀結構和分組。為了實作此功能,我們定義一個新的類別。
建立新檔案
package com.craftinginterpreters.lox; class AstPrinter implements Expr.Visitor<String> { String print(Expr expr) { return expr.accept(this); } }
如您所見,它實作了訪問者介面。這表示我們需要為目前擁有的每個表達式類型提供 visit 方法。
return expr.accept(this); }
在 print() 之後新增
@Override public String visitBinaryExpr(Expr.Binary expr) { return parenthesize(expr.operator.lexeme, expr.left, expr.right); } @Override public String visitGroupingExpr(Expr.Grouping expr) { return parenthesize("group", expr.expression); } @Override public String visitLiteralExpr(Expr.Literal expr) { if (expr.value == null) return "nil"; return expr.value.toString(); } @Override public String visitUnaryExpr(Expr.Unary expr) { return parenthesize(expr.operator.lexeme, expr.right); }
}
字面表達式很容易—它們將值轉換為字串,並進行少量檢查以處理 Java 的 null 代表 Lox 的 nil。其他表達式具有子表達式,因此它們使用此 parenthesize() 輔助方法
在 visitUnaryExpr() 之後新增
private String parenthesize(String name, Expr... exprs) { StringBuilder builder = new StringBuilder(); builder.append("(").append(name); for (Expr expr : exprs) { builder.append(" "); builder.append(expr.accept(this)); } builder.append(")"); return builder.toString(); }
它接受名稱和子表達式的清單,並將它們全部包在括號中,產生像這樣的字串
(+ 1 2)
請注意,它會對每個子表達式呼叫 accept() 並傳入它自己。這是 遞迴步驟,讓我們可以列印整個樹。
我們還沒有剖析器,所以很難看到它的實際運作。目前,我們將湊合一個小的 main() 方法,手動實例化一個樹並列印它。
在 parenthesize() 之後新增
public static void main(String[] args) { Expr expression = new Expr.Binary( new Expr.Unary( new Token(TokenType.MINUS, "-", null, 1), new Expr.Literal(123)), new Token(TokenType.STAR, "*", null, 1), new Expr.Grouping( new Expr.Literal(45.67))); System.out.println(new AstPrinter().print(expression)); }
如果我們做的一切都正確,它會列印
(* (- 123) (group 45.67))
您可以繼續刪除此方法。我們不需要它。此外,當我們新增新的語法樹類型時,我不會費心在 AstPrinter 中顯示必要的 visit 方法。如果您想(並且您希望 Java 編譯器不要對您大喊大叫),請自行新增它們。當我們在下一章開始將 Lox 程式碼剖析為語法樹時,它會派上用場。或者,如果您不在意維護 AstPrinter,請隨意刪除它。我們不會再次需要它。
挑戰
-
稍早,我說我們新增到語法元語法的
|、*和+形式只是語法糖。採用此語法expr → expr ( "(" ( expr ( "," expr )* )? ")" | "." IDENTIFIER )+ | IDENTIFIER | NUMBER
產生一個符合相同語言的語法,但未使用任何語法糖。
獎勵:這段語法編碼的是哪種表達式?
-
Visitor 模式讓您可以在物件導向語言中模擬函數式樣式。為函數式語言設計一個互補的模式。它應該讓您可以將一個類型上的所有操作綁定在一起,並讓您可以輕鬆定義新類型。
(SML 或 Haskell 非常適合此練習,但 Scheme 或其他 Lisp 也可以。)
-
在逆波蘭表示法 (RPN) 中,算術運算子的運算元都放置在運算子之前,因此
1 + 2變成1 2 +。計算從左到右進行。數字被推入隱式堆疊。算術運算子會彈出最上面的兩個數字、執行運算,然後將結果推入。因此,這個(1 + 2) * (4 - 3)
在 RPN 中變成
1 2 + 4 3 - *
為我們的語法樹類別定義一個訪問者類別,該類別會採用表達式、將其轉換為 RPN,並傳回結果字串。