虛擬機器
魔術師保護他們的秘密,並不是因為這些秘密有多大、多重要,而是因為它們太小、太微不足道。在舞台上創造出的奇妙效果,通常是基於一個荒謬的秘密,魔術師會不好意思承認那是他們的把戲。
克里斯多福·普利斯特,《頂尖對決》
我們花了很多時間討論如何將程式表示為一系列的位元組碼指令,但這感覺就像只用填充的死動物來學習生物學一樣。我們在理論上知道指令是什麼,但我們從未見過它們的實際運作,因此很難真正理解它們做什麼。如果我們對位元組碼的行為沒有很好的理解,就很難編寫輸出位元組碼的編譯器。
因此,在我們開始建構新的直譯器的前端之前,我們先從後端開始—執行指令的虛擬機器。它為位元組碼注入生命。觀察指令的運作可以讓我們更清楚地了解編譯器如何將使用者的原始碼翻譯成一系列的指令。
15.1指令執行機器
虛擬機器是直譯器內部架構的一部分。您將一段程式碼(實際上是一個區塊)交給它,它就會執行它。虛擬機器的程式碼和資料結構都位於一個新的模組中。
建立新檔案
#ifndef clox_vm_h #define clox_vm_h #include "chunk.h" typedef struct { Chunk* chunk; } VM; void initVM(); void freeVM(); #endif
像往常一樣,我們先從簡單的開始。虛擬機器會逐漸取得一大堆需要追蹤的狀態,因此我們現在定義一個結構來存放這些狀態。目前,我們只儲存它執行的區塊。
就像我們建立的大部分資料結構一樣,我們也定義了建立和拆解虛擬機器的函數。以下是實作方式
建立新檔案
#include "common.h" #include "vm.h" VM vm; void initVM() { } void freeVM() { }
好吧,稱這些函數為「實作」有點勉強。我們還沒有任何有趣的狀態需要初始化或釋放,因此函數都是空的。相信我,我們很快就會實現的。
這裡稍微有趣一點的是 `vm` 的宣告。這個模組最終會有大量的函數,如果將虛擬機器的指標傳遞給所有這些函數,會很麻煩。相反,我們宣告一個全域的虛擬機器物件。反正我們只需要一個,而且這樣可以讓本書中的程式碼更簡潔一些。
在我們開始將有趣的程式碼注入虛擬機器之前,我們先將它連接到直譯器的主要進入點。
int main(int argc, const char* argv[]) {
在 main() 中
initVM();
Chunk chunk;
當直譯器第一次啟動時,我們會啟動虛擬機器。然後,當我們準備退出時,我們會將它關閉。
disassembleChunk(&chunk, "test chunk");
在 main() 中
freeVM();
freeChunk(&chunk);
最後一個儀式性的義務
#include "debug.h"
#include "vm.h"
int main(int argc, const char* argv[]) {
現在當您執行 clox 時,它會在建立上一章中手動撰寫的區塊之前啟動虛擬機器。虛擬機器已準備就緒,因此讓我們教它做一些事情。
15.1.1執行指令
當我們命令它解釋位元組碼區塊時,虛擬機器就會開始運作。
disassembleChunk(&chunk, "test chunk");
在 main() 中
interpret(&chunk);
freeVM();
此函數是虛擬機器的主要進入點。它的宣告如下
void freeVM();
在 freeVM() 之後新增
InterpretResult interpret(Chunk* chunk);
#endif
虛擬機器會執行區塊,然後從這個列舉傳回一個值
} VM;
在結構 VM 之後新增
typedef enum { INTERPRET_OK, INTERPRET_COMPILE_ERROR, INTERPRET_RUNTIME_ERROR } InterpretResult;
void initVM(); void freeVM();
我們還沒有使用結果,但是當我們有一個報告靜態錯誤的編譯器和一個偵測執行階段錯誤的虛擬機器時,直譯器會使用它來知道如何設定程序的結束程式碼。
我們正朝著一些實際的實作邁進。
在 freeVM() 之後新增
InterpretResult interpret(Chunk* chunk) { vm.chunk = chunk; vm.ip = vm.chunk->code; return run(); }
首先,我們將要執行的區塊儲存在虛擬機器中。然後我們呼叫 `run()`,一個實際執行位元組碼指令的內部輔助函數。在這兩部分之間有一行有趣的程式碼。這個 `ip` 是什麼意思?
當虛擬機器處理位元組碼時,它會追蹤它所在的位置—目前正在執行的指令的位置。我們沒有在 `run()` 內部使用區域變數來處理這個問題,因為最終其他函數也需要存取它。相反,我們將它儲存為 VM 中的一個欄位。
typedef struct {
Chunk* chunk;
在結構 VM 中
uint8_t* ip;
} VM;
它的類型是位元組指標。我們使用一個實際的 C 指標直接指向位元組碼陣列的中間,而不是像整數索引之類的東西,因為取消引用指標比按索引查詢陣列中的元素更快。
名稱「IP」是傳統的,而且—與 CS 中許多傳統名稱不同—實際上是有道理的:它是指令指標。幾乎世界上每一個指令集(無論是真實的還是虛擬的)都有一個類似的暫存器或變數。
我們透過將它指向區塊中第一個程式碼位元組來初始化 `ip`。我們還沒有執行該指令,因此 `ip` 指向即將被執行的指令。這在虛擬機器執行的整個過程中都成立:IP 始終指向下一個指令,而不是目前正在處理的指令。
真正有趣的事情發生在 `run()` 中。
在 freeVM() 之後新增
static InterpretResult run() { #define READ_BYTE() (*vm.ip++) for (;;) { uint8_t instruction; switch (instruction = READ_BYTE()) { case OP_RETURN: { return INTERPRET_OK; } } } #undef READ_BYTE }
這是 clox 中最重要的函數,到目前為止。當直譯器執行使用者的程式時,它會將大約 90% 的時間花在 `run()` 內部。它是虛擬機器跳動的心臟。
儘管有如此戲劇化的介紹,但它的概念很簡單。我們有一個不斷運行的外部迴圈。每次執行迴圈時,我們都會讀取並執行單個位元組碼指令。
若要處理指令,我們首先要弄清楚我們正在處理哪種指令。 `READ_BYTE` 巨集會讀取 `ip` 目前指向的位元組,然後前進指令指標。任何指令的第一個位元組都是運算碼。給定一個數值運算碼,我們需要取得實作該指令語義的正確 C 程式碼。此過程稱為解碼或分派指令。
我們對每個指令都執行此過程,每次執行指令時都執行此過程,因此這是整個虛擬機器中最關鍵的效能部分。程式語言的傳說中充斥著巧妙的技術,可以有效地進行位元組碼分派,這些技術可以追溯到電腦的早期。
唉,最快的解決方案需要非標準的 C 擴充功能,或手寫的組合語言程式碼。對於 clox,我們將保持簡單。就像我們的反組譯器一樣,我們有一個單一的大型 `switch` 陳述式,每個運算碼都有一個 case。每個 case 的主體都實作該運算碼的行為。
到目前為止,我們只處理一個指令 `OP_RETURN`,而它唯一做的就是完全退出迴圈。最終,該指令將用於從目前的 Lox 函數傳回,但我們還沒有函數,因此我們將暫時重新利用它來結束執行。
讓我們來支援我們的另一個指令。
switch (instruction = READ_BYTE()) {
在 run() 中
case OP_CONSTANT: { Value constant = READ_CONSTANT(); printValue(constant); printf("\n"); break; }
case OP_RETURN: {
我們還沒有足夠的機制來對常數做任何有用的事情。目前,我們只會將其列印出來,以便直譯器駭客可以看到我們的虛擬機器內部發生了什麼。呼叫 `printf()` 需要包含一個標頭。
新增至檔案頂端
#include <stdio.h>
#include "common.h"
我們還有一個新的巨集要定義。
#define READ_BYTE() (*vm.ip++)
在 run() 中
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
for (;;) {
`READ_CONSTANT()` 會從位元組碼讀取下一個位元組,將結果數字視為索引,並在區塊的常數表中查找對應的值。在後面的章節中,我們將新增一些帶有參考常數的運算元的指令,因此我們現在要設定這個輔助巨集。
與之前的 `READ_BYTE` 巨集一樣,`READ_CONSTANT` 僅在 `run()` 內部使用。為了使該範圍更明確,巨集定義本身被限制在該函數中。我們在開頭定義它們,並且—因為我們關心—在結尾取消定義它們。
#undef READ_BYTE
在 run() 中
#undef READ_CONSTANT
}
15.1.2執行追蹤
如果您現在執行 clox,它會執行我們在上一個章節中手動撰寫的區塊,並將 `1.2` 輸出到您的終端。我們可以看出來它正在運作,但那只是因為我們對 `OP_CONSTANT` 的實作有臨時程式碼可以記錄值。一旦該指令正在做它應該做的事情,並將該常數傳遞給其他想要消耗它的操作,虛擬機器將會變成一個黑盒子。這會使我們這些虛擬機器實作者的生活更加艱難。
為了幫助自己,現在是時候為虛擬機器新增一些診斷記錄,就像我們對區塊本身所做的那樣。事實上,我們甚至會重複使用相同的程式碼。我們不希望始終啟用此記錄—它僅適用於我們這些虛擬機器駭客,而不是 Lox 使用者—因此我們先建立一個標誌來隱藏它。
#include <stdint.h>
#define DEBUG_TRACE_EXECUTION
#endif
當定義此標誌時,虛擬機器會在執行每個指令之前反組譯並列印它。我們之前的反組譯器靜態地遍歷整個區塊一次,而此反組譯器會動態地、即時地反組譯指令。
for (;;) {
在 run() 中
#ifdef DEBUG_TRACE_EXECUTION disassembleInstruction(vm.chunk, (int)(vm.ip - vm.chunk->code)); #endif
uint8_t instruction;
由於 disassembleInstruction() 接受一個整數位元組偏移量,而我們將目前的指令參考儲存為直接指標,因此我們先做一些指標運算,將 ip 轉換回相對於位元組碼開頭的相對偏移量。然後,我們反組譯從該位元組開始的指令。
一如既往,我們需要在呼叫函式之前引入函式的宣告。
#include "common.h"
#include "debug.h"
#include "vm.h"
我知道到目前為止這段程式碼並不是很令人印象深刻—它實際上是一個包在 for 迴圈中的 switch 語句,但信不信由你,這是我們 VM 的兩個主要組件之一。有了它,我們就可以強制執行指令。它的簡單性是一種優點—它做的事情越少,速度就越快。與我們在 jlox 中使用 Visitor 模式來遍歷 AST 的所有複雜性和開銷相比,這完全不同。
15 . 2值堆疊操作器
除了強制性的副作用之外,Lox 還有產生、修改和消耗值的運算式。因此,我們編譯後的位元組碼需要一種方式,在需要它們的不同指令之間傳輸值。例如
print 3 - 2;
顯然,我們需要用於常數 3 和 2、print 語句以及減法的指令。但是,減法指令如何知道 3 是被減數,而 2 是減數?print 指令如何知道要印出結果?
更確切地說,看看這裡的東西
fun echo(n) { print n; return n; } print echo(echo(1) + echo(2)) + echo(echo(4) + echo(5));
我將每個子運算式包裝在對 echo() 的呼叫中,該呼叫會印出並傳回其引數。這種副作用意味著我們可以查看運算的確切順序。
暫時別擔心 VM。想想 Lox 本身語義。算術運算子的運算元顯然需要在我們可以執行運算本身之前先求值。(如果你不知道 a 和 b 是什麼,就很難將 a + b 相加。)此外,當我們在 jlox 中實作運算式時,我們決定左運算元必須在右運算元之前求值。
這是 print 語句的語法樹
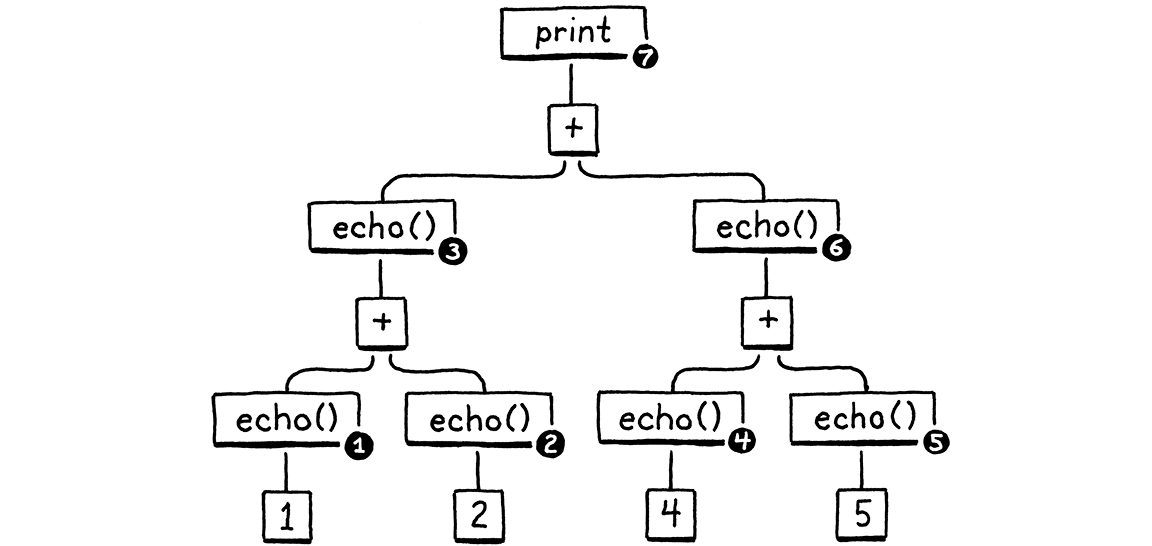
在從左到右求值,以及運算式巢狀方式的條件下,任何正確的 Lox 實作必須以這個順序印出這些數字
1 // from echo(1) 2 // from echo(2) 3 // from echo(1 + 2) 4 // from echo(4) 5 // from echo(5) 9 // from echo(4 + 5) 12 // from print 3 + 9
我們舊的 jlox 直譯器透過遞迴遍歷 AST 來完成此操作。它執行後序遍歷。首先,它會向下遞迴左運算元分支,然後是右運算元,最後它會求值節點本身。
在求值左運算元之後,jlox 需要將該結果暫時儲存在某處,同時它忙於向下遍歷右運算元樹。我們在 Java 中為此使用本機變數。我們的遞迴樹狀遍歷直譯器會為每個正在求值的節點建立一個唯一的 Java 呼叫框架,因此我們可以擁有任意多的本機變數。
在 clox 中,我們的 run() 函式不是遞迴的—巢狀運算式樹會被扁平化為一系列線性指令。我們沒有使用 C 本機變數的奢侈,那麼我們應該如何以及在哪裡儲存這些暫時值?你可能已經猜到了,但我想深入探討這個問題,因為這是我們認為理所當然的程式設計的一個方面,但我們很少學習電腦為什麼會以這種方式架構。
讓我們做一個奇怪的練習。我們將逐步瀏覽上述程式的執行
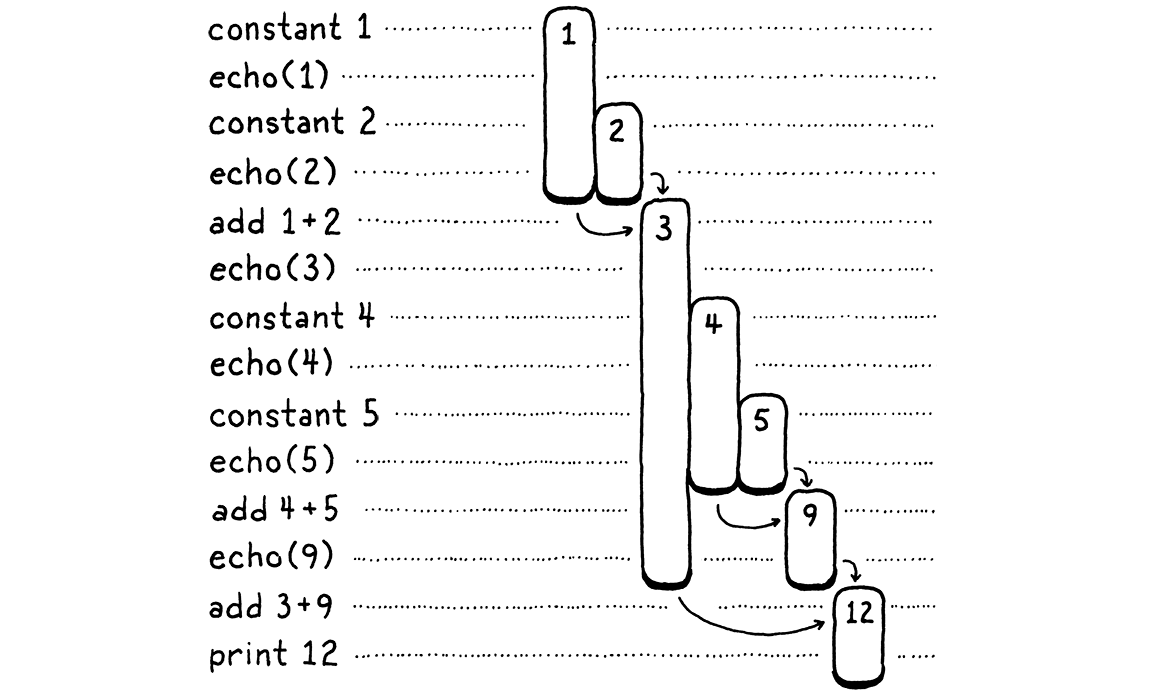
左邊是程式碼的步驟。右邊是我們正在追蹤的值。每個長條代表一個數字。它從值第一次產生時開始—無論是常數還是加法的結果。長條的長度會追蹤先前產生的值何時需要保留,並在該值最終被運算消耗時結束。
當你逐步瀏覽時,你會看到值出現,然後稍後被消耗掉。存在時間最長的是從加法左側產生的值。當我們處理右側運算元運算式時,這些值會保留下來。
在上面的圖表中,我給每個唯一的數字一個獨立的視覺欄位。讓我們稍微更節省一點。一旦消耗掉一個數字,我們允許其欄位重複用於稍後的另一個值。換句話說,我們拿走那裡的所有間隙並將它們填滿,從右邊推入數字
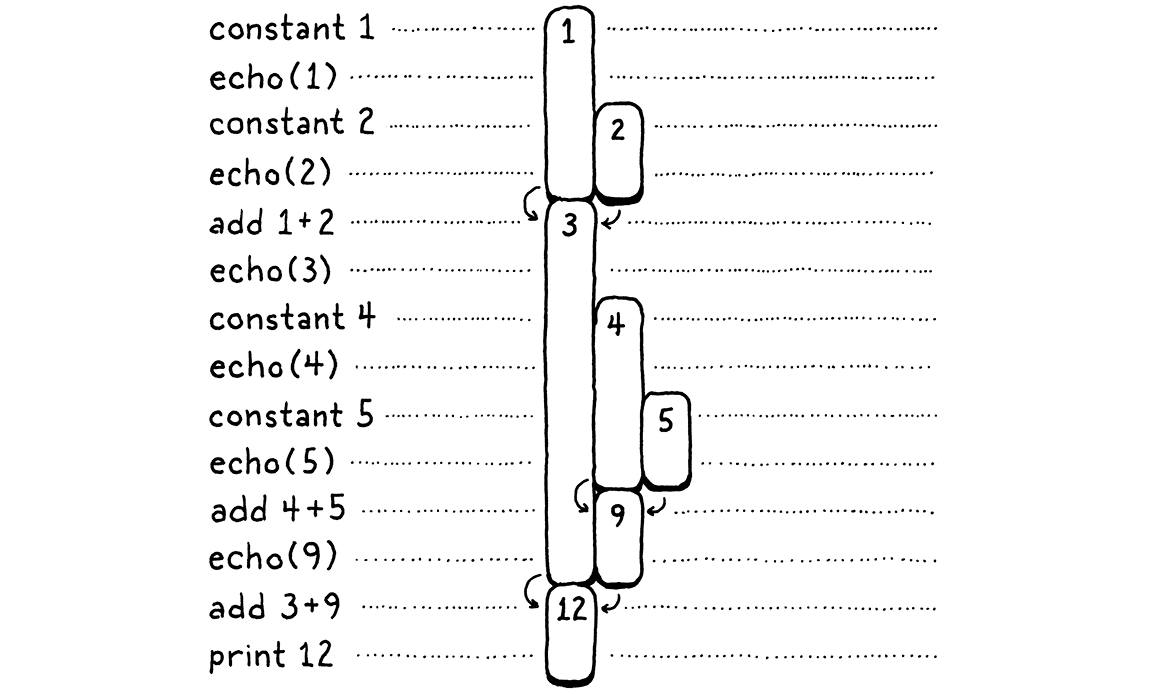
這裡有一些有趣的事情正在發生。當我們將所有內容都移過去時,每個數字仍然可以在其整個生命週期中保持在單一欄位中。此外,沒有留下任何間隙。換句話說,每當一個數字比另一個數字早出現時,它至少會和第二個數字一樣長。第一個出現的數字是最後一個被消耗的數字。嗯 . . . 後進先出 . . . 為什麼,這是一個堆疊!
在第二張圖表中,每次我們引入一個數字時,我們都會將其從右邊推入堆疊。當數字被消耗時,它們總是從最右邊到最左邊彈出。
由於我們需要追蹤的暫時值自然具有類似堆疊的行為,因此我們的 VM 將使用堆疊來管理它們。當指令「產生」一個值時,它會將其推入堆疊。當它需要消耗一個或多個值時,它會透過從堆疊中彈出來取得它們。
15 . 2 . 1VM 的堆疊
也許這看起來不像是一個啟示,但我喜歡基於堆疊的 VM。當你第一次看到魔術時,它感覺就像真的有魔法。但是,當你了解它的運作方式時—通常是一些機械的噱頭或誤導—驚奇感就消失了。在電腦科學中有幾個概念,即使在我將它們拆開並了解所有細節之後,最初的光芒仍然存在。基於堆疊的 VM 就是其中之一。
正如你將在本章中看到的,在基於堆疊的 VM 中執行指令非常簡單。在後面的章節中,你還會發現將原始碼編譯為基於堆疊的指令集是一件輕而易舉的事。然而,這種架構的速度足以被生產語言實作所使用。這幾乎感覺像是在程式設計語言遊戲中作弊。
好吧,是時候寫程式碼了!這是堆疊
typedef struct {
Chunk* chunk;
uint8_t* ip;
在結構 VM 中
Value stack[STACK_MAX]; Value* stackTop;
} VM;
我們在原始 C 陣列之上自己實作堆疊語義。堆疊的底部—第一個被推入並且最後一個被彈出的值—位於陣列中的元素零,然後是稍後推入的值。如果我們將「crepe」的字母—我最喜歡的可堆疊早餐品項—依序推入堆疊,則產生的 C 陣列看起來像這樣

由於堆疊隨著值的推入和彈出而增長和縮小,因此我們需要追蹤堆疊頂部在陣列中的位置。與 ip 一樣,我們使用直接指標而不是整數索引,因為取消參考指標比每次需要時計算索引的偏移量要快。
指標指向陣列元素,該元素剛好在包含堆疊頂部值的元素之後。這看起來有點奇怪,但幾乎每個實作都會這樣做。這表示我們可以透過指向陣列中的元素零來表示堆疊為空。

如果我們指向頂部元素,那麼對於空堆疊,我們需要指向元素 -1。這在 C 中是未定義的。當我們將值推入堆疊時 . . .

. . . stackTop 始終指向剛好在最後一個項目之後的位置。

我記得是這樣:stackTop 指向接下來要推入的值將去的位置。我們可以在堆疊上儲存的最大值數量(至少目前是這樣)是
#include "chunk.h"
#define STACK_MAX 256
typedef struct {
為我們的 VM 提供固定堆疊大小意味著某些指令序列可能會推入太多值並耗盡堆疊空間—經典的「堆疊溢位」。我們可以根據需要動態增長堆疊,但現在我們將保持簡單。由於 VM 使用 Value,因此我們需要包含其宣告。
#include "chunk.h"
#include "value.h"
#define STACK_MAX 256
現在 VM 有一些有趣的狀態,我們可以初始化它。
void initVM() {
在 initVM() 中
resetStack();
}
這使用此輔助函式
在變數 vm 之後新增
static void resetStack() { vm.stackTop = vm.stack; }
由於堆疊陣列直接內嵌在 VM 結構中宣告,因此我們不需要配置它。我們甚至不需要清除陣列中未使用的儲存格—我們只會在將值儲存在其中之後才會存取它們。我們唯一需要初始化的就是將 stackTop 設定為指向陣列的開頭,以表示堆疊為空。
堆疊協定支援兩個運算
InterpretResult interpret(Chunk* chunk);
在 interpret() 之後新增
void push(Value value); Value pop();
#endif
你可以將新值推入堆疊頂部,也可以將最近推入的值彈出。這是第一個函式
在 freeVM() 之後新增
void push(Value value) { *vm.stackTop = value; vm.stackTop++; }
如果你不熟悉 C 指標語法和運算,這是一個很好的熱身。第一行將 value 儲存在堆疊頂部的陣列元素中。請記住,stackTop 指向剛好在最後一個使用元素之後,在下一個可用元素的位置。這將值儲存在該插槽中。然後,我們遞增指標本身,使其指向陣列中下一個未使用的插槽,因為先前的插槽已被佔用。
彈出是鏡像反轉。
在 push() 之後新增
Value pop() { vm.stackTop--; return *vm.stackTop; }
首先,我們將堆疊指標移回以到達陣列中最近使用的插槽。然後,我們查詢該索引處的值並傳回它。我們不需要明確地從陣列中「移除」它—向下移動 stackTop 足以將該插槽標示為不再使用。
15 . 2 . 2堆疊追蹤
我們有一個可運作的堆疊,但很難看出它正在運作。當我們開始實作更複雜的指令,並編譯和執行更大的程式碼片段時,最終會將大量的值塞進那個陣列中。如果我們可以檢視堆疊,我們這些 VM 黑客的生活會更容易。
為此,每當我們追蹤執行時,我們也會在解譯每個指令之前顯示堆疊的當前內容。
#ifdef DEBUG_TRACE_EXECUTION
在 run() 中
printf(" "); for (Value* slot = vm.stack; slot < vm.stackTop; slot++) { printf("[ "); printValue(*slot); printf(" ]"); } printf("\n");
disassembleInstruction(vm.chunk,
我們迴圈處理,列印陣列中的每個值,從第一個(堆疊底部)開始,到頂部結束。這讓我們可以觀察每個指令對堆疊的影響。輸出相當冗長,但當我們從直譯器的內部外科手術式地提取出一個惱人的錯誤時,它會很有用。
有了堆疊,讓我們重新檢視我們的兩個指令。首先是
case OP_CONSTANT: {
Value constant = READ_CONSTANT();
在 run() 中
取代 2 行
push(constant);
break;
在上一章中,我對 OP_CONSTANT 指令如何「載入」常數含糊其詞。現在我們有一個堆疊,你明白產生一個值的實際含義:它會被推入堆疊。
case OP_RETURN: {
在 run() 中
printValue(pop()); printf("\n");
return INTERPRET_OK;
然後我們讓 OP_RETURN 從堆疊中彈出頂端的值,並在退出之前列印出來。當我們為 clox 新增真實函式的支援時,我們會變更此程式碼。但是,就目前而言,這讓我們可以讓 VM 執行簡單的指令序列並顯示結果。
15 . 3算術計算機
我們 VM 的核心和靈魂現在都已就緒。位元組碼迴圈會分派和執行指令。當值在其中流動時,堆疊會增長和縮小。這兩個部分都可以運作,但僅憑我們目前僅有的兩個基本指令很難感受到它們之間巧妙的互動。因此,讓我們教我們的直譯器進行算術運算。
我們將從最簡單的算術運算開始,即一元否定。
var a = 1.2; print -a; // -1.2.
前綴 - 運算子採用一個運算元,即要否定的值。它會產生單一結果。我們還沒有處理剖析器,但我們可以新增上述語法將編譯成的位元組碼指令。
OP_CONSTANT,
在 enum OpCode 中
OP_NEGATE,
OP_RETURN,
我們像這樣執行它
}
在 run() 中
case OP_NEGATE: push(-pop()); break;
case OP_RETURN: {
該指令需要一個運算的值,它會從堆疊中彈出該值來取得。它會否定該值,然後將結果推回,以供後續指令使用。沒有比這更容易的了。我們也可以反組譯它。
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
在 disassembleInstruction() 中
case OP_NEGATE: return simpleInstruction("OP_NEGATE", offset);
case OP_RETURN:
我們可以在測試區塊中試試看。
writeChunk(&chunk, constant, 123);
在 main() 中
writeChunk(&chunk, OP_NEGATE, 123);
writeChunk(&chunk, OP_RETURN, 123);
載入常數後,但在傳回之前,我們執行否定指令。這會以其否定值取代堆疊上的常數。然後傳回指令會將其列印出來
-1.2
神奇!
15 . 3 . 1二元運算子
好吧,一元運算子並不是那麼令人印象深刻。我們在堆疊上仍然只有單一值。要真正看到一些深度,我們需要二元運算子。Lox 有四個二元算術運算子:加法、減法、乘法和除法。我們將一次實作所有這些運算子。
OP_CONSTANT,
在 enum OpCode 中
OP_ADD, OP_SUBTRACT, OP_MULTIPLY, OP_DIVIDE,
OP_NEGATE,
回到位元組碼迴圈,它們會像這樣執行
}
在 run() 中
case OP_ADD: BINARY_OP(+); break; case OP_SUBTRACT: BINARY_OP(-); break; case OP_MULTIPLY: BINARY_OP(*); break; case OP_DIVIDE: BINARY_OP(/); break;
case OP_NEGATE: push(-pop()); break;
這四個指令之間唯一的區別在於它們最終使用哪個基礎 C 運算子來組合兩個運算元。圍繞該核心算術運算式的是一些樣板程式碼,用於從堆疊中拉出值並將結果推入。當我們稍後新增動態類型時,該樣板程式碼將會增長。為了避免重複該程式碼四次,我將其包裝在巨集中。
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
在 run() 中
#define BINARY_OP(op) \ do { \ double b = pop(); \ double a = pop(); \ push(a op b); \ } while (false)
for (;;) {
我承認這是對 C 前置處理器相當冒險的使用。我曾猶豫是否要這樣做,但當我們在後續章節中需要為每個運算元新增類型檢查之類的東西時,你會很高興。要帶你瀏覽相同的程式碼四次將會是一件苦差事。
如果你不熟悉這個技巧,那麼外部的 do while 迴圈可能看起來很奇怪。這個巨集需要展開為一系列陳述式。為了謹慎的巨集作者,我們想要確保這些陳述式在巨集展開時都位於相同的範圍內。想像一下,如果你定義了
#define WAKE_UP() makeCoffee(); drinkCoffee();
然後像這樣使用它
if (morning) WAKE_UP();
目的是僅在 morning 為 true 時執行巨集主體的兩個陳述式。但它會展開為
if (morning) makeCoffee(); drinkCoffee();;
糟糕。if 僅附加到第一個陳述式。你可能會認為你可以使用區塊來修正此問題。
#define WAKE_UP() { makeCoffee(); drinkCoffee(); }
這更好,但你仍然有風險
if (morning) WAKE_UP(); else sleepIn();
現在你在 else 上得到編譯錯誤,因為巨集區塊之後有尾隨的 ;。在巨集中使用 do while 迴圈看起來很有趣,但它為你提供了一種將多個陳述式包含在也允許在結尾使用分號的區塊內的方法。
我們剛才說到哪裡了?對了,該巨集主體所做的事情很簡單。二元運算子採用兩個運算元,因此會彈出兩次。它對這兩個值執行運算,然後將結果推入。
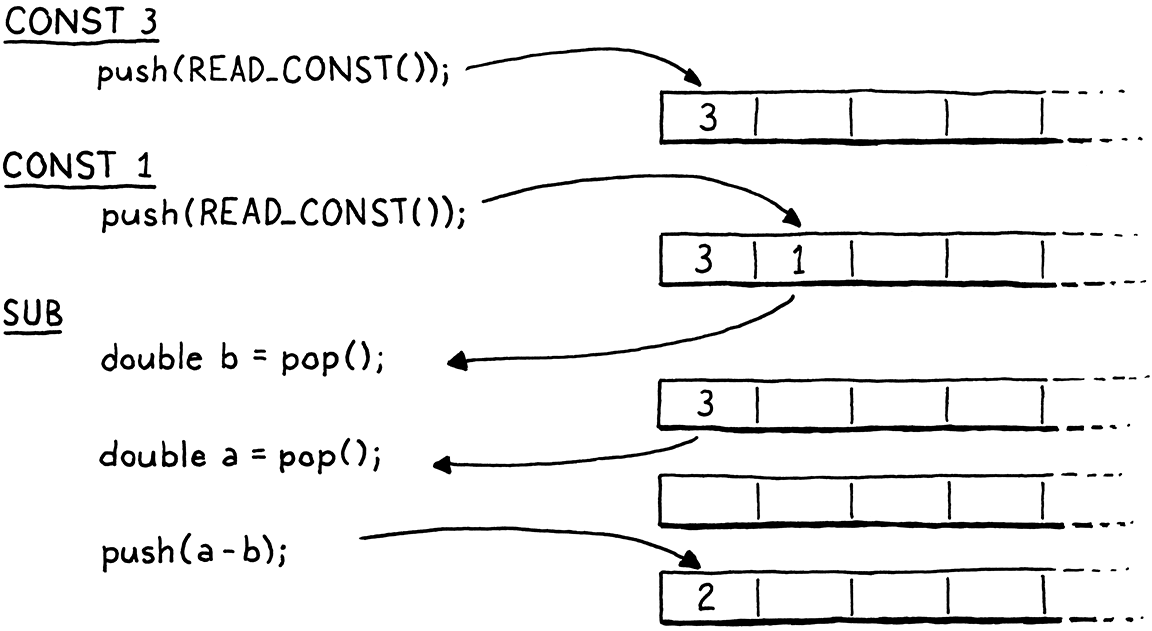
請密切注意兩個彈出的順序。請注意,我們將第一個彈出的運算元指派給 b,而不是 a。它看起來是反向的。當運算元本身被計算時,會先評估左邊,然後評估右邊。這表示左運算元會在右運算元之前被推入。因此,位於堆疊頂端的是右運算元。因此,我們彈出的第一個值是 b。
例如,如果我們編譯 3 - 1,則指令之間的資料流看起來像這樣
如同我們在 run() 內的其他巨集所做的那樣,我們在函式結尾處清理自己。
#undef READ_CONSTANT
在 run() 中
#undef BINARY_OP
}
最後是反組譯器支援。
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
在 disassembleInstruction() 中
case OP_ADD: return simpleInstruction("OP_ADD", offset); case OP_SUBTRACT: return simpleInstruction("OP_SUBTRACT", offset); case OP_MULTIPLY: return simpleInstruction("OP_MULTIPLY", offset); case OP_DIVIDE: return simpleInstruction("OP_DIVIDE", offset);
case OP_NEGATE:
算術指令格式很簡單,如 OP_RETURN。即使算術運算子採用運算元—它們在堆疊上被找到—算術位元組碼指令則不然。
讓我們透過評估更大的運算式來測試一些新的指令
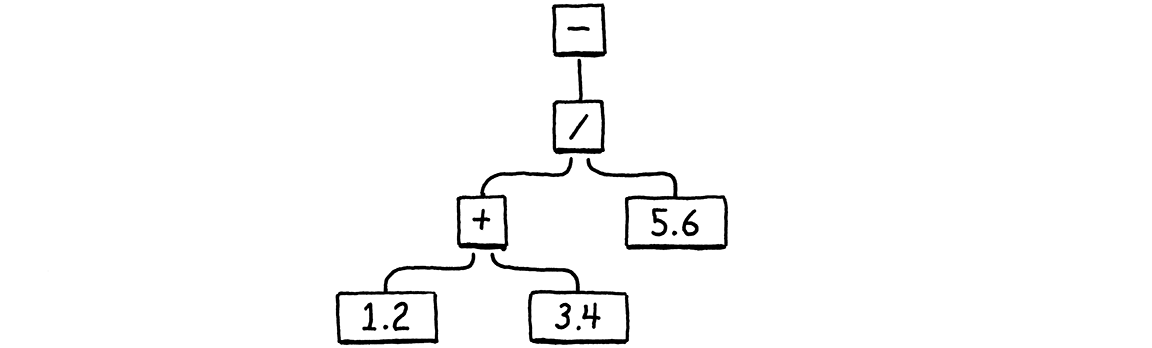
在我們現有的範例區塊的基礎上,以下是我們需要手動編譯該 AST 為位元組碼的其他指令。
int constant = addConstant(&chunk, 1.2); writeChunk(&chunk, OP_CONSTANT, 123); writeChunk(&chunk, constant, 123);
在 main() 中
constant = addConstant(&chunk, 3.4); writeChunk(&chunk, OP_CONSTANT, 123); writeChunk(&chunk, constant, 123); writeChunk(&chunk, OP_ADD, 123); constant = addConstant(&chunk, 5.6); writeChunk(&chunk, OP_CONSTANT, 123); writeChunk(&chunk, constant, 123); writeChunk(&chunk, OP_DIVIDE, 123);
writeChunk(&chunk, OP_NEGATE, 123); writeChunk(&chunk, OP_RETURN, 123);
加法優先。左常數 1.2 的指令已存在,因此我們再新增一個用於 3.4 的指令。然後我們使用 OP_ADD 將這兩個相加,並將其留在堆疊上。這涵蓋了除法的左側。接下來,我們推送 5.6,並將加法結果除以它。最後,我們將該結果否定。
請注意 OP_ADD 的輸出如何隱式地流動成為 OP_DIVIDE 的運算元,而無需任何指令彼此直接耦合。這就是堆疊的魔力。它讓我們可以自由地組合指令,而無需它們具有任何複雜性或對資料流程的了解。堆疊就像一個它們全部讀取和寫入的共用工作區。
在這個小小的範例區塊中,堆疊仍然只有兩個值高,但是當我們開始將 Lox 來源編譯為位元組碼時,我們將擁有使用更多堆疊的區塊。同時,請嘗試使用這個手動編寫的區塊來計算不同的巢狀算術運算式,並查看值如何在指令和堆疊中流動。
你現在最好從你的系統中移除它。這是我們手動建立的最後一個區塊。當我們下次重新檢視位元組碼時,我們將編寫一個編譯器來為我們產生它。
挑戰
-
你將為下列運算式產生什麼位元組碼指令序列
1 * 2 + 3 1 + 2 * 3 3 - 2 - 1 1 + 2 * 3 - 4 / -5
(請記住,Lox 沒有負數常值語法,因此
-5會否定數字 5。) -
如果我們真的想要最小的指令集,我們可以消除
OP_NEGATE或OP_SUBTRACT。顯示你將為下列項目產生的位元組碼指令序列4 - 3 * -2
首先,不使用
OP_NEGATE。然後,不使用OP_SUBTRACT。根據以上所述,你認為同時擁有這兩個指令有意義嗎?為什麼?你是否會考慮包含其他任何多餘的指令?
-
我們 VM 的堆疊具有固定大小,而且我們不會檢查推送值是否會使其溢位。這表示錯誤的指令序列可能會導致我們的直譯器當機或進入未定義的行為。透過在需要時動態增長堆疊來避免這種情況。
這樣做的成本和效益是什麼?
-
為了解譯
OP_NEGATE,我們彈出運算元,否定該值,然後將結果推入。這是一個簡單的實作,但它不必要地遞增和遞減stackTop,因為堆疊最終會保持相同的高度。直接在堆疊上否定值並保持stackTop不變可能會更快。試試看,看看你是否可以測量到效能差異。是否還有其他指令你可以執行類似的優化?
設計註記:基於暫存器的位元組碼
在這本書的其餘部分,我們將仔細地實作一個圍繞基於堆疊的位元組碼指令集的直譯器。還有另一個位元組碼架構系列—基於暫存器。儘管名稱如此,這些位元組碼指令並不像實際晶片(如 x64)中的暫存器那樣難以處理。使用實際硬體暫存器,你通常只有少數幾個用於整個程式,因此你會花費大量精力嘗試有效率地使用它們並在它們之間傳輸內容。
在基於暫存器的 VM 中,你仍然有一個堆疊。暫時值仍然會被推入其中,並且在不再需要時彈出。主要區別在於指令可以從堆疊中的任何位置讀取其輸入,並且可以將其輸出儲存到特定的堆疊插槽中。
採用這個小的 Lox 指令碼
var a = 1; var b = 2; var c = a + b;
在我們的基於堆疊的 VM 中,最後一個陳述式將會編譯成類似
load <a> // Read local variable a and push onto stack. load <b> // Read local variable b and push onto stack. add // Pop two values, add, push result. store <c> // Pop value and store in local variable c.
(如果你還不完全了解載入和儲存指令,請不要擔心。我們將在實作變數時更詳細地說明它們。)我們有四個單獨的指令。這表示通過位元組碼解譯迴圈四次,解碼和分派四個指令。它至少需要七個位元組的程式碼—四個用於運算碼,另外三個用於識別要載入和儲存的局部變數的運算元。三次推送和三次彈出。大量的工作!
在基於暫存器的指令集中,指令可以直接從局部變數讀取和儲存。上面最後一個陳述式的位元組碼如下所示
add <a> <b> <c> // Read values from a and b, add, store in c.
加法指令較大—它有三個指令運算元,定義了從堆疊的哪個位置讀取輸入,以及將結果寫入的位置。但是,由於局部變數存在於堆疊上,它可以直接從 a 和 b 讀取,然後將結果直接存儲到 c 中。
只需要解碼和分派單一指令,而且整個指令僅佔用四個位元組。由於額外的運算元,解碼更為複雜,但仍然是整體上的優勢。不需要進行推入和彈出或其他堆疊操作。
Lua 的主要實作過去是基於堆疊的。在 Lua 5.0 中,實作者切換到暫存器指令集,並注意到速度有所提升。提升的幅度自然很大程度取決於語言語義的細節、特定的指令集以及編譯器的複雜程度,但這應該會引起您的注意。
這引出了一個顯而易見的問題,為什麼我會在這本書的剩餘部分使用基於堆疊的位元碼?暫存器虛擬機很棒,但要為其編寫編譯器要困難得多。對於很可能是您的第一個編譯器,我希望堅持使用易於生成且易於執行的指令集。基於堆疊的位元碼非常簡單。
它在文獻和社群中也更為人所知。即使您最終可能會轉向更進階的技術,這也是與其他語言駭客同行分享的一個很好的共同基礎。