隨需掃描
文學只是在水平線上以僅有的二十六個語音符號、十個阿拉伯數字和約八個標點符號所構成的獨特排列。
科特·馮內果,《像與上帝握手:關於寫作的對話》
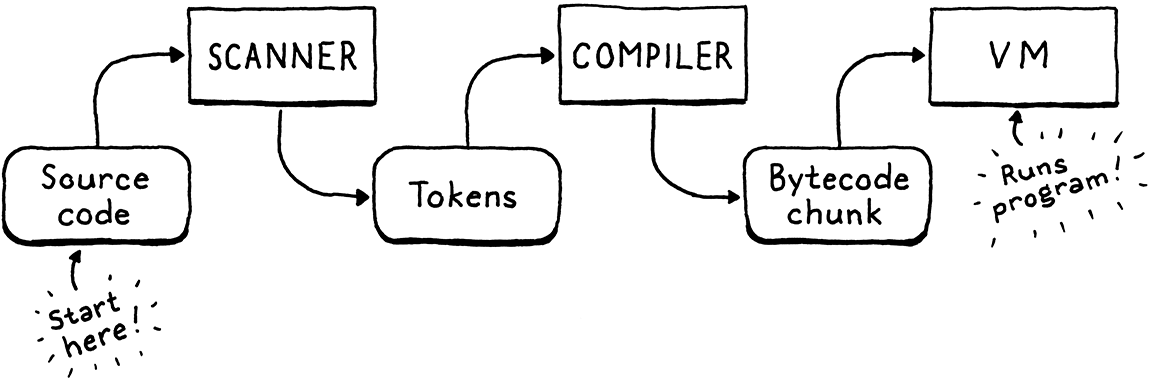
我們的第二個直譯器 clox 有三個階段—掃描器、編譯器和虛擬機器。一個資料結構連接每一對階段。Token 從掃描器流向編譯器,而位元組碼的區塊從編譯器流向 VM。我們從接近尾端的 區塊 和 VM 開始實作。現在,我們要跳回開頭,建立一個產生 Token 的掃描器。在下一章中,我們將用我們的位元組碼編譯器將兩端連接起來。
我承認,這不是本書中最令人興奮的一章。使用同一種語言的兩種實作,必然會有一些重複。我確實偷偷加入了一些與 jlox 掃描器相比有趣的差異。繼續閱讀以了解它們是什麼。
16.1啟動直譯器
既然我們正在建構前端,我們可以讓 clox 像真正的直譯器一樣執行。不再需要手動編寫的位元組碼區塊。現在是 REPL 和腳本載入的時候了。刪除 main() 中的大部分程式碼,並將其替換為
int main(int argc, const char* argv[]) {
initVM();
在 main() 中
替換 26 行
if (argc == 1) { repl(); } else if (argc == 2) { runFile(argv[1]); } else { fprintf(stderr, "Usage: clox [path]\n"); exit(64); } freeVM();
return 0; }
如果傳遞沒有任何參數給可執行檔,您將進入 REPL。單個命令行參數被理解為要執行的腳本路徑。
我們需要一些系統標頭,所以讓我們把它們都解決掉。
添加到檔案頂部
#include <stdio.h> #include <stdlib.h> #include <string.h>
#include "common.h"
接下來,我們啟動 REPL 並開始 REPL-ing。
#include "vm.h"
static void repl() { char line[1024]; for (;;) { printf("> "); if (!fgets(line, sizeof(line), stdin)) { printf("\n"); break; } interpret(line); } }
一個高品質的 REPL 可以優雅地處理跨越多行的輸入,並且沒有硬編碼的行長度限制。這裡的 REPL 有點...樸素,但對於我們的目的來說已經足夠了。
真正的工作發生在 interpret() 中。我們很快就會講到它,但首先讓我們處理載入腳本。
在 repl() 後添加
static void runFile(const char* path) { char* source = readFile(path); InterpretResult result = interpret(source); free(source); if (result == INTERPRET_COMPILE_ERROR) exit(65); if (result == INTERPRET_RUNTIME_ERROR) exit(70); }
我們讀取檔案並執行產生的 Lox 原始碼字串。然後,根據結果,我們適當地設定退出碼,因為我們是嚴謹的工具建構者,並且關心像這樣的小細節。
我們也需要釋放原始碼字串,因為 readFile() 動態分配它並將所有權傳遞給呼叫者。該函式如下所示
在 repl() 後添加
static char* readFile(const char* path) { FILE* file = fopen(path, "rb"); fseek(file, 0L, SEEK_END); size_t fileSize = ftell(file); rewind(file); char* buffer = (char*)malloc(fileSize + 1); size_t bytesRead = fread(buffer, sizeof(char), fileSize, file); buffer[bytesRead] = '\0'; fclose(file); return buffer; }
就像許多 C 程式碼一樣,它比看起來應該花費更多的精力,特別是對於一種專門為作業系統設計的語言來說。困難的部分是,我們想要分配一個足夠大的字串來讀取整個檔案,但在我們讀取它之前,我們不知道檔案有多大。
這裡的程式碼是解決這個問題的經典技巧。我們開啟檔案,但在讀取它之前,我們使用 fseek() 定位到結尾。然後我們呼叫 ftell(),它告訴我們從檔案開頭開始有多少位元組。由於我們搜尋(sought?)到結尾,這就是大小。我們倒帶回到開頭,分配一個大小的字串,並以單一批次讀取整個檔案。
那麼我們就完成了,對嗎?還沒有。這些函式呼叫,就像 C 標準程式庫中的大多數呼叫一樣,可能會失敗。如果這是 Java,失敗將被拋出為例外,並自動展開堆疊,這樣我們就不*真的*需要處理它們。在 C 中,如果我們不檢查它們,它們會被靜默地忽略。
這並不是一本關於良好 C 程式設計實踐的書,但我討厭鼓勵不良風格,所以讓我們繼續處理錯誤。這對我們有好處,就像吃我們的蔬菜或使用牙線一樣。
幸運的是,如果發生失敗,我們不需要做任何特別聰明的事情。如果我們無法正確讀取使用者的腳本,我們真正能做的就是告訴使用者並優雅地退出直譯器。首先,我們可能無法開啟檔案。
FILE* file = fopen(path, "rb");
在 readFile() 中
if (file == NULL) { fprintf(stderr, "Could not open file \"%s\".\n", path); exit(74); }
fseek(file, 0L, SEEK_END);
如果檔案不存在或使用者無法存取它,就會發生這種情況。這很常見—人們總是會打錯路徑。
這種失敗更為罕見
char* buffer = (char*)malloc(fileSize + 1);
在 readFile() 中
if (buffer == NULL) { fprintf(stderr, "Not enough memory to read \"%s\".\n", path); exit(74); }
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
如果我們甚至無法分配足夠的記憶體來讀取 Lox 腳本,使用者可能會有更大的問題要擔心,但我們應該盡力至少讓他們知道。
最後,讀取本身可能會失敗。
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
在 readFile() 中
if (bytesRead < fileSize) { fprintf(stderr, "Could not read file \"%s\".\n", path); exit(74); }
buffer[bytesRead] = '\0';
這也不太可能。實際上,對 fseek()、ftell() 和 rewind() 的 呼叫 理論上也會失敗,但讓我們不要走得太遠,好嗎?
16.1.1開啟編譯管道
我們已經有了一個 Lox 原始碼字串,所以現在我們準備好設定一個管道來掃描、編譯和執行它。它由 interpret() 驅動。現在,該函式執行我們舊的硬編碼測試區塊。讓我們將其更改為更接近其最終版本的內容。
void freeVM();
函式 interpret()
替換 1 行
InterpretResult interpret(const char* source);
void push(Value value);
以前我們傳入一個區塊,現在我們傳入原始碼字串。這是新的實作
函式 interpret()
替換 4 行
InterpretResult interpret(const char* source) { compile(source); return INTERPRET_OK;
}
我們將在本章中不會建立實際的*編譯器*,但我們可以開始佈局其結構。它存在於一個新模組中。
#include "common.h"
#include "compiler.h"
#include "debug.h"
目前,其中的一個函式宣告如下
建立新檔案
#ifndef clox_compiler_h #define clox_compiler_h void compile(const char* source); #endif
該簽名將會改變,但它可以讓我們開始。
編譯的第一階段是掃描—我們在本章中正在做的事情—所以現在編譯器所做的就是設定它。
建立新檔案
#include <stdio.h> #include "common.h" #include "compiler.h" #include "scanner.h" void compile(const char* source) { initScanner(source); }
這自然也會在後面的章節中增加。
16.1.2掃描器掃描
在我們開始編寫有用的程式碼之前,還有一些腳手架要搭建。首先,一個新的標頭
建立新檔案
#ifndef clox_scanner_h #define clox_scanner_h void initScanner(const char* source); #endif
及其對應的實作
建立新檔案
#include <stdio.h> #include <string.h> #include "common.h" #include "scanner.h" typedef struct { const char* start; const char* current; int line; } Scanner; Scanner scanner;
當我們的掃描器處理使用者的原始碼時,它會追蹤它的進度。就像我們對 VM 所做的那樣,我們將該狀態包裝在一個結構中,然後建立該類型的一個頂級模組變數,這樣我們就不必在所有各種函式中傳遞它。
欄位出奇的少。start 指標標記了正在掃描的當前詞素的開始位置,而 current 指向正在查看的當前字元。

我們有一個 line 欄位來追蹤當前詞素所在的行以進行錯誤報告。就是這樣!我們甚至沒有保留指向原始碼字串開頭的指標。掃描器會處理程式碼一次,然後就完成了。
既然我們有一些狀態,我們應該初始化它。
在變數 scanner 後添加
void initScanner(const char* source) { scanner.start = source; scanner.current = source; scanner.line = 1; }
我們從第一行的第一個字元開始,就像一個蹲在起跑線的跑步者一樣。
16.2一次一個 Token
在 jlox 中,當起跑槍響起時,掃描器會向前衝刺並急切地掃描整個程式,返回一個 Token 列表。這在 clox 中將是一個挑戰。我們需要某種可增長的陣列或列表來儲存 Token。我們需要管理 Token 的分配和釋放,以及集合本身。這有很多程式碼,以及大量的記憶體流失。
在任何時間點,編譯器只需要一到兩個 Token—記住我們的文法只需要一個 Token 的先行—因此我們不需要同時保留*所有* Token。相反,最簡單的解決方案是在編譯器需要時才掃描 Token。當掃描器提供一個時,它會按值傳回 Token。它不需要動態分配任何東西—它可以在 C 堆疊上傳遞 Token。
很遺憾,我們目前還沒有編譯器可以向掃描器請求詞法單元 (token),所以掃描器會一直閒置不做事。為了啟動它,我們會先寫一些臨時程式碼來驅動它。
initScanner(source);
在 compile() 中
int line = -1; for (;;) { Token token = scanToken(); if (token.line != line) { printf("%4d ", token.line); line = token.line; } else { printf(" | "); } printf("%2d '%.*s'\n", token.type, token.length, token.start); if (token.type == TOKEN_EOF) break; }
}
這個迴圈會無限執行。每次迴圈都會掃描一個詞法單元並印出來。當它遇到一個特殊的「檔案結尾」詞法單元或錯誤時,就會停止。例如,如果我們在這個程式上執行直譯器
print 1 + 2;
它會印出
1 31 'print' | 21 '1' | 7 '+' | 21 '2' | 8 ';' 2 39 ''
第一欄是行號,第二欄是詞法單元 類型 的數值,最後則是詞素。第二行最後一個空白的詞素是 EOF 詞法單元。
本章剩餘部分的目標是透過實作這個關鍵函式來使那段程式碼運作
void initScanner(const char* source);
在 initScanner() 之後加入
Token scanToken();
#endif
每次呼叫都會掃描並回傳原始碼中的下一個詞法單元。一個詞法單元看起來像這樣
#define clox_scanner_h
typedef struct { TokenType type; const char* start; int length; int line; } Token;
void initScanner(const char* source);
它和 jlox 的 Token 類別非常相似。我們有一個列舉型別來識別它是什麼類型的詞法單元—數字、識別符、+ 運算子等等。這個列舉型別實際上與 jlox 中的列舉相同,所以讓我們直接把它全部列出來。
#ifndef clox_scanner_h #define clox_scanner_h
typedef enum { // Single-character tokens. TOKEN_LEFT_PAREN, TOKEN_RIGHT_PAREN, TOKEN_LEFT_BRACE, TOKEN_RIGHT_BRACE, TOKEN_COMMA, TOKEN_DOT, TOKEN_MINUS, TOKEN_PLUS, TOKEN_SEMICOLON, TOKEN_SLASH, TOKEN_STAR, // One or two character tokens. TOKEN_BANG, TOKEN_BANG_EQUAL, TOKEN_EQUAL, TOKEN_EQUAL_EQUAL, TOKEN_GREATER, TOKEN_GREATER_EQUAL, TOKEN_LESS, TOKEN_LESS_EQUAL, // Literals. TOKEN_IDENTIFIER, TOKEN_STRING, TOKEN_NUMBER, // Keywords. TOKEN_AND, TOKEN_CLASS, TOKEN_ELSE, TOKEN_FALSE, TOKEN_FOR, TOKEN_FUN, TOKEN_IF, TOKEN_NIL, TOKEN_OR, TOKEN_PRINT, TOKEN_RETURN, TOKEN_SUPER, TOKEN_THIS, TOKEN_TRUE, TOKEN_VAR, TOKEN_WHILE, TOKEN_ERROR, TOKEN_EOF } TokenType;
typedef struct {
除了將所有名稱加上 TOKEN_ 前綴 (因為 C 會把列舉名稱放在最上層命名空間) 之外,唯一的差異是額外的 TOKEN_ERROR 類型。那是關於什麼的?
掃描期間只會偵測到幾個錯誤:未終止的字串和無法識別的字元。在 jlox 中,掃描器會自行回報這些錯誤。在 clox 中,掃描器會為該錯誤產生一個合成的「錯誤」詞法單元,並將其傳遞給編譯器。這樣一來,編譯器就知道發生了錯誤,並可以在回報錯誤之前啟動錯誤修復。
clox 的 Token 類型中的新穎之處在於它如何表示詞素。在 jlox 中,每個 Token 都將詞素儲存為自己獨立的小 Java 字串。如果我們對 clox 也這樣做,就必須找出如何管理這些字串的記憶體。這尤其困難,因為我們是透過值來傳遞詞法單元—多個詞法單元可能會指向同一個詞素字串。所有權會變得非常奇怪。
取而代之的是,我們使用原始的原始碼字串作為字元儲存。我們用一個指向其第一個字元的指標和它所包含的字元數來表示詞素。這表示我們完全不需要擔心管理詞素的記憶體,而且可以自由地複製詞法單元。只要主要的原始碼字串的生命週期 比 所有詞法單元都長,一切都會正常運作。
16 . 2 . 1掃描詞法單元
我們準備好掃描一些詞法單元了。我們會逐步完成完整的實作,從這裡開始
在 initScanner() 之後加入
Token scanToken() { scanner.start = scanner.current; if (isAtEnd()) return makeToken(TOKEN_EOF); return errorToken("Unexpected character."); }
由於每次呼叫此函式都會掃描一個完整的詞法單元,因此我們知道當我們進入函式時,正處於一個新詞法單元的開頭。因此,我們設定 scanner.start 指向目前的字元,以便記住我們即將掃描的詞素的起始位置。
然後我們檢查是否已到達原始碼的結尾。如果是,我們會回傳一個 EOF 詞法單元並停止。這是一個哨兵值,會向編譯器發出訊號,停止請求更多的詞法單元。
如果我們沒有到達結尾,我們會執行一些 . . . 操作 . . . 來掃描下一個詞法單元。但我們還沒寫那段程式碼。我們很快就會處理它。如果那段程式碼沒有成功掃描並回傳詞法單元,那麼我們就會到達函式的結尾。這一定表示我們遇到掃描器無法辨識的字元,因此我們會為該字元回傳一個錯誤詞法單元。
這個函式依賴幾個輔助函式,其中大多數都與 jlox 中的相似。首先是
在 initScanner() 之後加入
static bool isAtEnd() { return *scanner.current == '\0'; }
我們要求原始字串是一個有效的以 null 結尾的 C 字串。如果目前的字元是 null 位元組,那麼我們就到達結尾了。
為了建立詞法單元,我們有這個類似建構函式的函式
在 isAtEnd() 之後加入
static Token makeToken(TokenType type) { Token token; token.type = type; token.start = scanner.start; token.length = (int)(scanner.current - scanner.start); token.line = scanner.line; return token; }
它使用掃描器的 start 和 current 指標來捕捉詞法單元的詞素。它會設定一些其他明顯的欄位,然後回傳詞法單元。它有一個用於回傳錯誤詞法單元的姊妹函式。
在 makeToken() 之後加入
static Token errorToken(const char* message) { Token token; token.type = TOKEN_ERROR; token.start = message; token.length = (int)strlen(message); token.line = scanner.line; return token; }
唯一的區別在於「詞素」指向錯誤訊息字串,而不是指向使用者的原始碼。同樣地,我們需要確保錯誤訊息持續存在足夠長的時間,以便編譯器讀取它。在實務上,我們只會用 C 字串文字呼叫這個函式。這些字串是常數且永久的,所以我們沒有問題。
我們現在所擁有的是一個基本上可以運作的掃描器,它適用於一個具有空詞法文法的語言。由於文法沒有產生式,所以每個字元都是錯誤。這並不是一個有趣的程式設計語言,所以讓我們填入規則。
16 . 3Lox 的詞法文法
最簡單的詞法單元只有一個字元。我們像這樣辨識它們
if (isAtEnd()) return makeToken(TOKEN_EOF);
在 scanToken() 中
char c = advance(); switch (c) { case '(': return makeToken(TOKEN_LEFT_PAREN); case ')': return makeToken(TOKEN_RIGHT_PAREN); case '{': return makeToken(TOKEN_LEFT_BRACE); case '}': return makeToken(TOKEN_RIGHT_BRACE); case ';': return makeToken(TOKEN_SEMICOLON); case ',': return makeToken(TOKEN_COMMA); case '.': return makeToken(TOKEN_DOT); case '-': return makeToken(TOKEN_MINUS); case '+': return makeToken(TOKEN_PLUS); case '/': return makeToken(TOKEN_SLASH); case '*': return makeToken(TOKEN_STAR); }
return errorToken("Unexpected character.");
我們從原始碼中讀取下一個字元,然後直接使用 switch 語句來查看它是否與 Lox 的任何單字元詞素相符。為了讀取下一個字元,我們使用一個新的輔助函式,它會消耗目前的字元並回傳它。
在 isAtEnd() 之後加入
static char advance() { scanner.current++; return scanner.current[-1]; }
接下來是兩個字元的標點符號詞法單元,例如 != 和 >=。這些詞法單元也各有對應的單字元詞法單元。這表示當我們看到像 ! 這樣的字元時,我們不知道我們是在 ! 詞法單元中還是 != 詞法單元中,直到我們也查看下一個字元。我們像這樣處理它們
case '*': return makeToken(TOKEN_STAR);
在 scanToken() 中
case '!': return makeToken( match('=') ? TOKEN_BANG_EQUAL : TOKEN_BANG); case '=': return makeToken( match('=') ? TOKEN_EQUAL_EQUAL : TOKEN_EQUAL); case '<': return makeToken( match('=') ? TOKEN_LESS_EQUAL : TOKEN_LESS); case '>': return makeToken( match('=') ? TOKEN_GREATER_EQUAL : TOKEN_GREATER);
}
在消耗第一個字元之後,我們尋找 =。如果找到,我們會消耗它並回傳對應的雙字元詞法單元。否則,我們會保持目前的字元不變 (以便它可以成為下一個詞法單元的一部分),並回傳適當的單字元詞法單元。
用於有條件地消耗第二個字元的邏輯在此處
在 advance() 之後加入
static bool match(char expected) { if (isAtEnd()) return false; if (*scanner.current != expected) return false; scanner.current++; return true; }
如果目前的字元是所需的字元,我們會前進並回傳 true。否則,我們會回傳 false 以表示它不相符。
現在我們的掃描器支援所有的標點符號式詞法單元。在我們處理較長的詞法單元之前,讓我們稍微繞道處理根本不屬於詞法單元的字元。
16 . 3 . 1空白字元
我們的掃描器需要處理空格、tab 和換行符號,但這些字元不會成為任何詞法單元的詞素的一部分。我們可以在 scanToken() 的主要字元 switch 語句中檢查這些字元,但是要確保函式在呼叫時仍能正確找到空白字元之後的下一個詞法單元,會變得有點棘手。我們必須將函式的整個主體包在迴圈或其他東西中。
取而代之的是,在開始詞法單元之前,我們會轉到一個單獨的函式。
Token scanToken() {
在 scanToken() 中
skipWhitespace();
scanner.start = scanner.current;
這會使掃描器跳過任何前導空白字元。在此呼叫回傳之後,我們知道下一個字元是有意義的字元 (或者我們已經到達原始碼的結尾)。
在 errorToken() 之後加入
static void skipWhitespace() { for (;;) { char c = peek(); switch (c) { case ' ': case '\r': case '\t': advance(); break; default: return; } } }
它有點像一個單獨的迷你掃描器。它會迴圈,消耗它遇到的每個空白字元。我們需要小心,不要消耗任何非空白字元。為了支援這一點,我們使用這個
在 advance() 之後加入
static char peek() { return *scanner.current; }
這只會回傳目前的字元,但不會消耗它。先前的程式碼會處理換行符號以外的所有空白字元。
break;
在 skipWhitespace() 中
case '\n': scanner.line++; advance(); break;
default:
return;
當我們消耗其中一個字元時,也會增加目前的行號。
16 . 3 . 2註解
如果你想要用精確的術語來說,註解在技術上不是「空白字元」,但就 Lox 而言,它們也可以被視為空白字元,所以我們也跳過它們。
break;
在 skipWhitespace() 中
case '/': if (peekNext() == '/') { // A comment goes until the end of the line. while (peek() != '\n' && !isAtEnd()) advance(); } else { return; } break;
default:
return;
註解在 Lox 中以 // 開頭,所以和 != 等一樣,我們需要向前看第二個字元。但是,對於 !=,即使找不到 =,我們仍然想要消耗 !。註解不同。如果我們沒有找到第二個 /,那麼 skipWhitespace() 也不能消耗第一個斜線。
為了處理這個問題,我們加入
在 peek() 之後加入
static char peekNext() { if (isAtEnd()) return '\0'; return scanner.current[1]; }
這類似於 peek(),但適用於目前的字元之後的一個字元。如果目前的字元和下一個字元都是 /,我們會消耗它們,然後消耗任何其他字元,直到下一個換行符號或原始碼的結尾。
我們使用 peek() 來檢查換行符號,但不會消耗它。這樣一來,在 skipWhitespace() 的外迴圈的下一次執行中,換行符號將會是目前的字元,我們會辨識它並遞增 scanner.line。
16 . 3 . 3常值詞法單元
數字和字串詞法單元很特別,因為它們具有與之關聯的執行階段值。我們會從字串開始,因為它們很容易識別—它們總是從雙引號開始。
match('=') ? TOKEN_GREATER_EQUAL : TOKEN_GREATER);
在 scanToken() 中
case '"': return string();
}
這會呼叫一個新的函式。
在 skipWhitespace() 之後加入
static Token string() { while (peek() != '"' && !isAtEnd()) { if (peek() == '\n') scanner.line++; advance(); } if (isAtEnd()) return errorToken("Unterminated string."); // The closing quote. advance(); return makeToken(TOKEN_STRING); }
類似於 jlox,我們會消耗字元,直到我們遇到結尾引號。我們也會追蹤字串文字內的換行符號。(Lox 支援多行字串。)而且,和以往一樣,我們會妥善處理在找到結尾引號之前就用完原始碼的情況。
clox 中的主要變更是不存在的東西。這又與記憶體管理有關。在 jlox 中,Token 類別有一個型別為 Object 的欄位,用於儲存從常值詞法單元的詞素轉換而來的執行階段值。
在 C 中實作這個功能需要很多工作。我們需要某種聯集和型別標記,以判斷詞法單元是否包含字串或雙精度值。如果是字串,我們需要以某種方式管理字串字元陣列的記憶體。
我們沒有將該複雜性加入掃描器,而是將常值詞素轉換為執行階段值的動作延後到稍後再進行。在 clox 中,詞法單元只會儲存詞素—也就是字元序列,與它在使用者原始碼中的顯示方式完全相同。稍後在編譯器中,當我們準備將該詞素儲存在區塊的常數表時,我們會將它轉換為執行階段值。
接下來是數字。我們不為每個可以開頭數字的十個數字添加一個 switch case,而是在這裡處理它們
char c = advance();
在 scanToken() 中
if (isDigit(c)) return number();
switch (c) {
這使用這個顯而易見的實用函數
在 initScanner() 之後加入
static bool isDigit(char c) { return c >= '0' && c <= '9'; }
我們使用這個來完成數字的掃描
在 skipWhitespace() 之後加入
static Token number() { while (isDigit(peek())) advance(); // Look for a fractional part. if (peek() == '.' && isDigit(peekNext())) { // Consume the ".". advance(); while (isDigit(peek())) advance(); } return makeToken(TOKEN_NUMBER); }
它與 jlox 的版本幾乎相同,只是我們再次不將詞素轉換為 double。
16 . 4識別符號和關鍵字
最後一批符號是識別符號,包括使用者定義的和保留的。本節應該很有趣—我們在 clox 中識別關鍵字的方式與在 jlox 中不同,並且涉及一些重要的資料結構。
首先,我們必須掃描詞素。名稱以字母或底線開頭。
char c = advance();
在 scanToken() 中
if (isAlpha(c)) return identifier();
if (isDigit(c)) return number();
我們使用這個來識別它們
在 initScanner() 之後加入
static bool isAlpha(char c) { return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_'; }
一旦我們找到一個識別符號,我們就在這裡掃描其餘部分
在 skipWhitespace() 之後加入
static Token identifier() { while (isAlpha(peek()) || isDigit(peek())) advance(); return makeToken(identifierType()); }
在第一個字母之後,我們也允許使用數字,並且我們持續消耗字母數字,直到用完為止。然後我們產生具有正確類型的符號。確定「正確」的類型是本章的獨特之處。
在 skipWhitespace() 之後加入
static TokenType identifierType() { return TOKEN_IDENTIFIER; }
好吧,我想這還不是很令人興奮。如果我們完全沒有保留字,那它就是這個樣子。我們應該如何識別關鍵字?在 jlox 中,我們將它們全部塞進一個 Java Map 中並按名稱查找。我們在 clox 中沒有任何雜湊表結構,至少目前沒有。
無論如何,雜湊表會是多餘的。要在雜湊表中查找字串,我們需要遍歷字串來計算其雜湊碼,找到雜湊表中對應的 bucket,然後對它碰巧在那裡找到的任何字串進行逐個字元的相等性比較。
假設我們掃描了識別符號「gorgonzola」。我們應該需要做多少工作來判斷它是否是一個保留字?好吧,沒有任何 Lox 關鍵字以「g」開頭,所以看第一個字元就足以明確回答否。這比雜湊表查找簡單得多。
那「cardigan」呢?我們在 Lox 中有一個以「c」開頭的關鍵字:「class」。但是「cardigan」中的第二個字元「a」排除了這種可能性。那「forest」呢?由於「for」是一個關鍵字,我們必須在字串中走得更遠才能確定我們沒有保留字。但是,在大多數情況下,只需要一兩個字元就足以判斷我們手上的是使用者定義的名稱。我們應該能夠識別出來並快速失敗。
這是一個視覺表示,說明了這種分支字元檢查邏輯
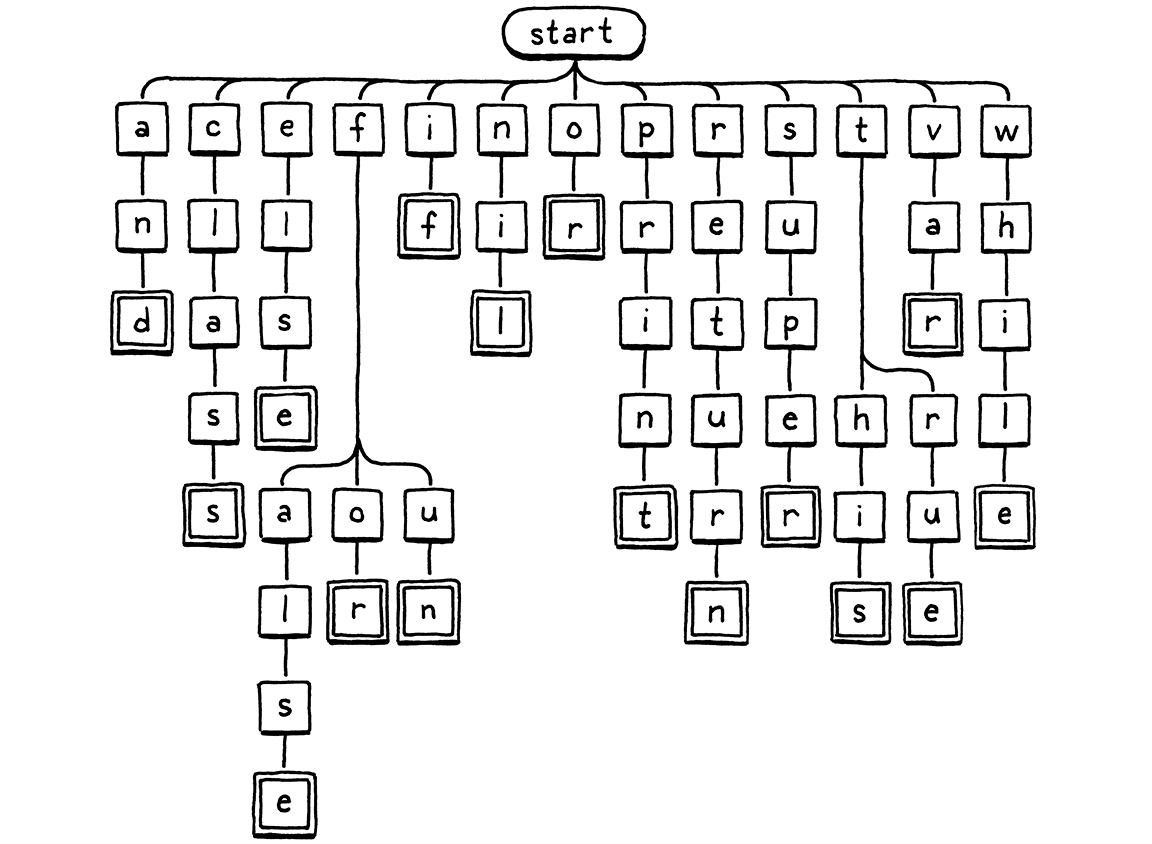
我們從根節點開始。如果有一個子節點的字母與詞素中的第一個字元匹配,我們就移動到該節點。然後針對詞素中的下一個字母重複此操作,依此類推。如果在任何時候詞素中的下一個字母與子節點不匹配,則識別符號一定不是關鍵字,我們就停止。如果我們到達雙線框,並且我們位於詞素的最後一個字元,那麼我們就找到了關鍵字。
16 . 4 . 1Tries 和狀態機
這個樹狀圖是一個稱為 trie 的東西的示例。trie 儲存一組字串。大多數其他用於儲存字串的資料結構都包含原始字元陣列,然後將它們包裹在一些更大的結構中,以幫助你更快地搜尋。trie 是不同的。你不會在 trie 中找到整個字串。
相反,trie「包含」的每個字串都表示為通過字元節點樹的路徑,就像我們上面的遍歷一樣。與字串中最後一個字元匹配的節點有一個特殊標記—圖示中的雙線框。這樣,如果你的 trie 包含「banquet」和「ban」,你就可以知道它不包含「banque」—「e」節點不會有該標記,而「n」和「t」節點會有。
Trie 是一個更基礎的資料結構的特例:一個確定性有限自動機 (DFA)。你可能也知道這些的其他名稱:有限狀態機,或簡稱狀態機。狀態機很棒。它們最終在從遊戲程式設計到實現網路協議的各種應用中都很有用。
在 DFA 中,你有一組狀態,它們之間有轉換,形成一個圖。在任何時間點,機器都「處於」一個狀態。它透過遵循轉換到達其他狀態。當你使用 DFA 進行詞法分析時,每個轉換都是從字串匹配的字元。每個狀態代表一組允許的字元。
我們的關鍵字樹正是識別 Lox 關鍵字的 DFA。但是 DFA 比簡單的樹更強大,因為它們可以是任意圖。轉換可以在狀態之間形成循環。這使你可以識別任意長度的字串。例如,這是一個識別數字字面值的 DFA
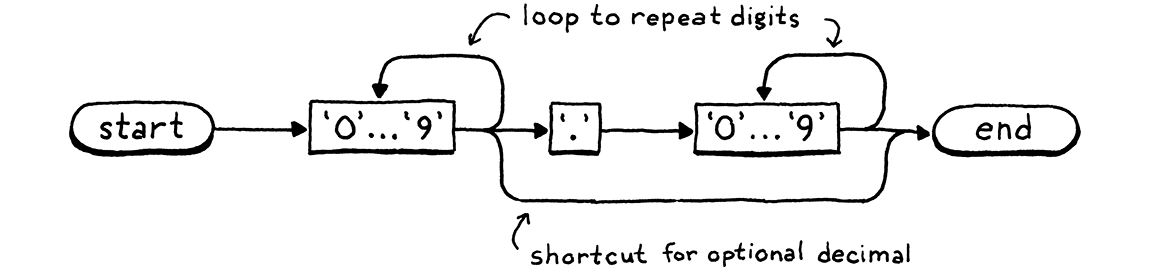
我將十個數字的節點折疊在一起以使其更具可讀性,但是基本過程是相同的—當你在詞素中消耗相應的字元時,你會遍歷路徑並進入節點。如果我們有此意願,我們可以構建一個巨大的 DFA,它可以為 Lox 執行所有詞法分析,一個可以識別並吐出我們所需的所有符號的單一狀態機。
然而,手動設計那個巨型 DFA 會很有挑戰性。這就是創建 Lex 的原因。你給它一個簡單的詞法語法文字描述—一堆正規表示式—它會自動為你生成一個 DFA,並產生一堆實現它的 C 程式碼。
我們不會走這條路。我們已經有一個完全可用的手動掃描器。我們只需要一個用於識別關鍵字的小型 trie。我們應該如何將其對應到程式碼?
最簡單的解決方案是為每個節點使用一個 switch 語句,每個分支都有 case。我們將從根節點開始,並處理簡單的關鍵字。
static TokenType identifierType() {
在 identifierType() 中
switch (scanner.start[0]) { case 'a': return checkKeyword(1, 2, "nd", TOKEN_AND); case 'c': return checkKeyword(1, 4, "lass", TOKEN_CLASS); case 'e': return checkKeyword(1, 3, "lse", TOKEN_ELSE); case 'i': return checkKeyword(1, 1, "f", TOKEN_IF); case 'n': return checkKeyword(1, 2, "il", TOKEN_NIL); case 'o': return checkKeyword(1, 1, "r", TOKEN_OR); case 'p': return checkKeyword(1, 4, "rint", TOKEN_PRINT); case 'r': return checkKeyword(1, 5, "eturn", TOKEN_RETURN); case 's': return checkKeyword(1, 4, "uper", TOKEN_SUPER); case 'v': return checkKeyword(1, 2, "ar", TOKEN_VAR); case 'w': return checkKeyword(1, 4, "hile", TOKEN_WHILE); }
return TOKEN_IDENTIFIER;
這些是與單個關鍵字對應的初始字母。如果我們看到「s」,則識別符號唯一可能對應的關鍵字是 super。但它可能不是,所以我們仍然需要檢查其餘的字母。在樹狀圖中,這基本上是懸掛在「s」上的直線路徑。
我們不會為每個節點滾動一個 switch。相反,我們有一個實用函數,可以測試潛在關鍵字的詞素的其餘部分。
在 skipWhitespace() 之後加入
static TokenType checkKeyword(int start, int length, const char* rest, TokenType type) { if (scanner.current - scanner.start == start + length && memcmp(scanner.start + start, rest, length) == 0) { return type; } return TOKEN_IDENTIFIER; }
我們將其用於樹中所有未分支的路徑。一旦我們找到一個只能是一個可能的保留字的首碼,我們就需要驗證兩件事。詞素的長度必須與關鍵字的長度完全相同。如果第一個字母是「s」,則詞素仍然可能是「sup」或「superb」。其餘的字元也必須完全匹配—「supar」是不夠好的。
如果我們確實有正確數量的字元,並且它們是我們想要的字元,那麼它就是一個關鍵字,我們返回相關的符號類型。否則,它必須是一個普通的識別符號。
我們有幾個關鍵字,其中樹在第一個字母之後再次分支。如果詞素以「f」開頭,則它可以是 false、for 或 fun。因此,我們為從「f」節點分支出來的分支添加另一個 switch。
case 'e': return checkKeyword(1, 3, "lse", TOKEN_ELSE);
在 identifierType() 中
case 'f': if (scanner.current - scanner.start > 1) { switch (scanner.start[1]) { case 'a': return checkKeyword(2, 3, "lse", TOKEN_FALSE); case 'o': return checkKeyword(2, 1, "r", TOKEN_FOR); case 'u': return checkKeyword(2, 1, "n", TOKEN_FUN); } } break;
case 'i': return checkKeyword(1, 1, "f", TOKEN_IF);
在我們切換之前,我們需要檢查是否甚至存在第二個字母。畢竟,「f」本身也是一個有效的識別符號。另一個分支字母是「t」。
case 's': return checkKeyword(1, 4, "uper", TOKEN_SUPER);
在 identifierType() 中
case 't': if (scanner.current - scanner.start > 1) { switch (scanner.start[1]) { case 'h': return checkKeyword(2, 2, "is", TOKEN_THIS); case 'r': return checkKeyword(2, 2, "ue", TOKEN_TRUE); } } break;
case 'v': return checkKeyword(1, 2, "ar", TOKEN_VAR);
就是這樣。幾個巢狀的 switch 語句。此程式碼不僅簡短,而且非常、非常快。它執行偵測關鍵字所需的最小工作量,並在它可以判斷識別符號不是保留字時立即退出。
這樣,我們的掃描器就完成了。
挑戰
-
許多較新的語言都支援字串內插。在字串字面值內部,你有一些特殊的分隔符—最常見的是開頭的
${和結尾的}。在這些分隔符之間,可以出現任何表達式。當字串字面值執行時,會評估內部表達式,將其轉換為字串,然後與周圍的字串字面值合併。例如,如果 Lox 支援字串內插,那麼這個 . . .
var drink = "Tea"; var steep = 4; var cool = 2; print "${drink} will be ready in ${steep + cool} minutes.";
. . .會列印出
Tea will be ready in 6 minutes.
你會定義哪些符記類型來實作字串插值 (string interpolation) 的掃描器?對於上述的字串字面值,你會發出哪些符記序列?
你會為以下內容發出哪些符記?
"Nested ${"interpolation?! Are you ${"mad?!"}"}"可以考慮參考其他支援插值的程式語言實作,看看它們是如何處理的。
-
許多程式語言使用角括號來表示泛型,同時也有
>>右移運算子。這導致了早期 C++ 版本中的一個經典問題。vector<vector<string>> nestedVectors;
這會產生編譯錯誤,因為
>>被詞法分析為單一個右移符記,而不是兩個>符記。使用者被迫在右括號之間加入空格來避免這個問題。後來的 C++ 版本變得更聰明,可以處理上面的程式碼。Java 和 C# 從來沒有這個問題。這些程式語言是如何指定和實作的?
-
許多程式語言,尤其是在其發展的後期,會定義「上下文關鍵字」。這些識別符號在某些上下文中表現得像保留字,但在其他上下文中可以是正常的用戶定義識別符號。
例如,在 C# 的
async方法中,await是一個關鍵字,但在其他方法中,你可以將await用作你自己的識別符號。舉幾個其他程式語言中的上下文關鍵字,以及它們有意義的上下文。擁有上下文關鍵字的優缺點是什麼?如果你需要在你的語言前端實作它們,你會如何實作?