編譯表達式
在我們人生的旅程中,我發現自己身處一片黑暗的森林中,那裡筆直的道路迷失了。
但丁·阿利吉耶里,《地獄篇》
本章之所以令人興奮,原因不是一個、兩個,而是三個。首先,它提供了我們虛擬機器執行管線的最後一個環節。一旦到位,我們就可以將使用者的原始碼從掃描一直貫穿到執行。
其次,我們將編寫一個真實、貨真價實的編譯器。它解析原始碼並輸出底層的一系列二進位指令。當然,它是位元組碼,而不是某個晶片的原生指令集,但它比 jlox 更接近底層。我們即將成為真正的語言駭客。
第三,也是最後一點,我要向您展示我最喜歡的演算法之一:Vaughan Pratt 的「自上而下的運算子優先級解析」。這是我所知解析表達式最優雅的方法。它可以優雅地處理前綴運算子、後綴、中綴、混綴,任何您有的-綴類型。它可以輕鬆處理優先級和結合性。我很喜歡它。
像往常一樣,在我們開始有趣的部分之前,我們有一些初步工作要完成。您必須先吃蔬菜才能吃甜點。首先,讓我們放棄我們為測試掃描器而編寫的臨時腳手架,並用更有用的東西取而代之。
InterpretResult interpret(const char* source) {
在 interpret() 中
取代 2 行
Chunk chunk; initChunk(&chunk); if (!compile(source, &chunk)) { freeChunk(&chunk); return INTERPRET_COMPILE_ERROR; } vm.chunk = &chunk; vm.ip = vm.chunk->code; InterpretResult result = run(); freeChunk(&chunk); return result;
}
我們建立一個新的空白程式碼塊,並將其傳遞給編譯器。編譯器將取得使用者的程式並使用位元組碼填滿程式碼塊。至少,如果程式沒有任何編譯錯誤,它會這樣做。如果它確實遇到錯誤,compile() 會傳回 false,我們就會捨棄無法使用的程式碼塊。
否則,我們將完成的程式碼塊傳送給虛擬機器執行。當虛擬機器完成時,我們會釋放程式碼塊,然後就完成了。如您所見,compile() 的簽章現在有所不同。
#define clox_compiler_h
取代 1 行
#include "vm.h" bool compile(const char* source, Chunk* chunk);
#endif
我們傳遞編譯器將在其中寫入程式碼的程式碼塊,然後 compile() 會傳回編譯是否成功。我們對實作中的簽章進行相同的變更。
#include "scanner.h"
函式 compile()
取代 1 行
bool compile(const char* source, Chunk* chunk) {
initScanner(source);
呼叫 initScanner() 是本章中唯一倖存的一行。撕掉我們為測試掃描器而編寫的臨時程式碼,並用這三行程式碼取而代之
initScanner(source);
在 compile() 中
取代 13 行
advance(); expression(); consume(TOKEN_EOF, "Expect end of expression.");
}
呼叫 advance() 會「啟動」掃描器。我們很快就會看到它的作用。然後我們解析一個單一表達式。我們還不會處理語句,所以這是我們支援的文法子集。當我們在幾個章節中新增語句時,我們會重新檢視這一點。在我們編譯表達式之後,我們應該位於原始碼的結尾,因此我們檢查 sentinel EOF 符號。
我們將在本章的剩餘部分努力使這個函式運作,尤其是那個小小的 expression() 呼叫。通常,我們會直接深入研究該函式定義,並從上到下逐步完成實作。
本章不同。一旦您將普拉特的解析技術全部載入腦海中,它就非常簡單,但要將其分解成小塊有點棘手。當然,它是遞迴的,這是問題的一部分。但它也依賴一個大型資料表。當我們建構演算法時,該表會新增額外的欄位。
我不想在每次擴展表格時都重新檢視 40 多行程式碼。因此,我們將從外部逐步深入到解析器的核心,並在進入核心之前涵蓋所有周圍的位元。這將需要比大多數章節更多的耐心和心理空間,但這是我能做的最好的事情。
17 . 1單趟編譯
編譯器大約有兩個工作。它解析使用者的原始碼以了解其含義。然後,它會利用這些知識輸出產生相同語義的底層指令。許多語言將這兩個角色分成實作中的兩個獨立趟次。解析器產生 AST—就像 jlox 所做的那樣—然後程式碼產生器會遍歷 AST 並輸出目標程式碼。
在 clox 中,我們採用舊式方法,將這兩個趟次合併為一個。在過去,語言駭客這樣做是因為電腦實際上沒有足夠的記憶體來儲存整個原始碼檔案的 AST。我們這樣做是因為它使我們的編譯器更簡單,這在使用 C 程式設計時是一個真正的優勢。
我們將要建構的單趟編譯器並不適用於所有語言。由於編譯器在產生程式碼時只能窺視使用者的程式,因此語言的設計必須讓您不需要太多周圍的上下文即可了解語法的一部分。幸運的是,微小的、動態類型的 Lox 非常適合這種情況。
實際上,這意味著我們的「編譯器」C 模組具有您從 jlox 認識的解析功能—使用符號、比對預期的符號類型等等。它也具有程式碼產生功能—發射位元組碼並將常數新增到目的地程式碼塊。(這也意味著我會在整個本章和後續章節中交替使用「解析」和「編譯」。)
我們將首先建構解析和程式碼產生部分。然後,我們將使用普拉特的技術,將它們與中間的程式碼結合在一起,以解析 Lox 的特定文法並輸出正確的位元組碼。
17 . 2解析符號
首先,編譯器的前端部分。這個函式的名稱應該聽起來很熟悉。
#include "scanner.h"
static void advance() { parser.previous = parser.current; for (;;) { parser.current = scanToken(); if (parser.current.type != TOKEN_ERROR) break; errorAtCurrent(parser.current.start); } }
就像在 jlox 中一樣,它會逐步瀏覽符號串流。它會向掃描器要求下一個符號並儲存它以供日後使用。在執行此操作之前,它會取得舊的 current 符號,並將其儲存在 previous 欄位中。稍後,在我們比對符號之後,這將派上用場,以便我們取得詞彙單元。
讀取下一個符號的程式碼封裝在迴圈中。請記住,clox 的掃描器不會報告詞彙錯誤。相反,它會建立特殊的錯誤符號,並讓解析器報告它們。我們在這裡執行此操作。
我們會不斷迴圈,讀取符號並報告錯誤,直到遇到非錯誤符號或到達結尾。這樣,解析器的其餘部分就只會看到有效的符號。目前和先前的符號會儲存在此結構中
#include "scanner.h"
typedef struct { Token current; Token previous; } Parser; Parser parser;
static void advance() {
就像我們在其他模組中所做的那樣,我們有一個此結構類型的單一全域變數,因此我們不需要在編譯器中的函式之間傳遞狀態。
17 . 2 . 1處理語法錯誤
如果掃描器交給我們一個錯誤符號,我們需要實際告知使用者。這會使用此項目發生
在變數 parser 之後新增
static void errorAtCurrent(const char* message) { errorAt(&parser.current, message); }
我們從目前的符號中提取位置,以便告知使用者錯誤發生在哪裡,並將其轉發到 errorAt()。更常見的是,我們會在剛使用完的符號位置報告錯誤,因此我們將此較短的名稱給予另一個函式
在變數 parser 之後新增
static void error(const char* message) { errorAt(&parser.previous, message); }
實際的工作在這裡發生
在變數 parser 之後新增
static void errorAt(Token* token, const char* message) { fprintf(stderr, "[line %d] Error", token->line); if (token->type == TOKEN_EOF) { fprintf(stderr, " at end"); } else if (token->type == TOKEN_ERROR) { // Nothing. } else { fprintf(stderr, " at '%.*s'", token->length, token->start); } fprintf(stderr, ": %s\n", message); parser.hadError = true; }
首先,我們列印錯誤發生的位置。如果詞彙單元是人類可讀的,我們會嘗試顯示它。然後,我們列印錯誤訊息本身。在那之後,我們設定這個 hadError 旗標。這會記錄編譯期間是否發生任何錯誤。此欄位也存在於解析器結構中。
Token previous;
在結構 Parser 中
bool hadError;
} Parser;
我之前說過,如果發生錯誤,compile() 應該回傳 false。現在我們可以讓它這麼做了。
consume(TOKEN_EOF, "Expect end of expression.");
在 compile() 中
return !parser.hadError;
}
我還有另一個用於錯誤處理的標誌要介紹。我們想要避免錯誤級聯。如果使用者在他們的程式碼中有錯誤,而且剖析器對於它在文法中的位置感到困惑,我們不希望在第一個錯誤之後,它噴出一堆毫無意義的連鎖錯誤。
我們在 jlox 中使用恐慌模式錯誤復原來解決這個問題。在 Java 直譯器中,我們拋出一個例外,以從所有剖析器程式碼中解開,到達一個我們可以跳過符號並重新同步的位置。我們在 C 中沒有 例外。相反地,我們會做一些障眼法。我們新增一個標誌來追蹤我們目前是否處於恐慌模式。
bool hadError;
在結構 Parser 中
bool panicMode;
} Parser;
當發生錯誤時,我們會設定它。
static void errorAt(Token* token, const char* message) {
在 errorAt() 中
parser.panicMode = true;
fprintf(stderr, "[line %d] Error", token->line);
在那之後,我們繼續像沒有發生錯誤一樣正常地編譯。位元組碼永遠不會被執行,所以繼續進行是無害的。訣竅是,當恐慌模式標誌被設定時,我們只是抑制任何其他被偵測到的錯誤。
static void errorAt(Token* token, const char* message) {
在 errorAt() 中
if (parser.panicMode) return;
parser.panicMode = true;
剖析器很有可能會偏離正軌,但使用者不會知道,因為錯誤都被吞掉了。當剖析器到達同步點時,恐慌模式就會結束。對於 Lox,我們選擇了語句邊界,所以當我們稍後將它們新增到我們的編譯器時,我們會在該處清除標誌。
這些新的欄位需要被初始化。
initScanner(source);
在 compile() 中
parser.hadError = false; parser.panicMode = false;
advance();
為了顯示錯誤,我們需要一個標準的標頭。
#include <stdio.h>
#include <stdlib.h>
#include "common.h"
還有一個最後的剖析函式,是來自 jlox 的另一個老朋友。
在 advance() 之後新增
static void consume(TokenType type, const char* message) { if (parser.current.type == type) { advance(); return; } errorAtCurrent(message); }
它與 advance() 類似,都會讀取下一個符號。但它也會驗證該符號是否具有預期的類型。如果沒有,它會報告錯誤。此函式是編譯器中大多數語法錯誤的基礎。
好了,關於前端的部分目前就夠了。
17 . 3發射位元組碼
在我們剖析並理解使用者程式碼的一部分之後,下一步是將其轉換為一系列位元組碼指令。它從最簡單的步驟開始:將單一位元組附加到區塊。
在 consume() 之後新增
static void emitByte(uint8_t byte) { writeChunk(currentChunk(), byte, parser.previous.line); }
很難相信偉大的事物會流經如此簡單的函式。它寫入給定的位元組,這可能是操作碼或指令的操作數。它傳入先前的符號的行資訊,以便執行階段錯誤與該行相關聯。
我們正在寫入的區塊會被傳遞到 compile() 中,但它需要傳遞到 emitByte()。為此,我們依賴這個中介函式
Parser parser;
在變數 parser 之後新增
Chunk* compilingChunk; static Chunk* currentChunk() { return compilingChunk; }
static void errorAt(Token* token, const char* message) {
現在,區塊指標儲存在模組層級變數中,就像我們儲存其他全域狀態一樣。稍後,當我們開始編譯使用者定義的函式時,「目前的區塊」的概念會變得更加複雜。為了避免必須回頭更改大量程式碼,我將該邏輯封裝在 currentChunk() 函式中。
我們在寫入任何位元組碼之前初始化這個新的模組變數
bool compile(const char* source, Chunk* chunk) {
initScanner(source);
在 compile() 中
compilingChunk = chunk;
parser.hadError = false;
然後,在最後,當我們完成編譯區塊時,我們會做最後的收尾。
consume(TOKEN_EOF, "Expect end of expression.");
在 compile() 中
endCompiler();
return !parser.hadError;
這會呼叫這個
在 emitByte() 之後新增
static void endCompiler() { emitReturn(); }
在本章中,我們的 VM 只處理表達式。當您執行 clox 時,它會剖析、編譯和執行單一表達式,然後印出結果。為了印出該值,我們暫時使用 OP_RETURN 指令。因此,我們讓編譯器在區塊的末尾新增一個這樣的指令。
在 emitByte() 之後新增
static void emitReturn() { emitByte(OP_RETURN); }
當我們來到後端時,我們不妨讓我們的生活更輕鬆一點。
在 emitByte() 之後新增
static void emitBytes(uint8_t byte1, uint8_t byte2) { emitByte(byte1); emitByte(byte2); }
隨著時間的推移,我們會有足夠多的情況需要寫入一個操作碼,後跟一個位元組的操作數,因此值得定義這個方便的函式。
17 . 4剖析前綴表達式
我們已經組裝了我們的剖析和程式碼產生工具函式。缺少的部分是中間連接這些工具的程式碼。

我們在 compile() 中剩下的唯一要實作的步驟是這個函式
在 endCompiler() 之後新增
static void expression() { // What goes here? }
我們還沒有準備好實作 Lox 中的所有種類的表達式。天哪,我們甚至沒有布林值。在本章中,我們只會擔心四種
- 數字字面值:
123 - 用於分組的括號:
(123) - 一元負號:
-123 - 算術的四大騎士:
+、-、*、/
當我們處理編譯每種表達式函式時,我們也會組裝呼叫它們的表格驅動剖析器的需求。
17 . 4 . 1符號的剖析器
現在,讓我們專注於每個都只有單一符號的 Lox 表達式。在本章中,只有數字字面值,但稍後會有更多。以下是我們如何編譯它們
我們將每個符號類型對應到不同的表達式類型。我們為每個輸出適當位元組碼的表達式定義一個函式。然後我們建立一個函式指標陣列。陣列中的索引對應到 TokenType 列舉值,而每個索引中的函式是編譯該符號類型表達式的程式碼。
為了編譯數字字面值,我們將一個指向以下函式的指標儲存在陣列中的 TOKEN_NUMBER 索引處。
在 endCompiler() 之後新增
static void number() { double value = strtod(parser.previous.start, NULL); emitConstant(value); }
我們假設數字字面值的符號已經被消耗,並儲存在 previous 中。我們取得該詞素並使用 C 標準函式庫將其轉換為雙精度值。然後我們產生程式碼以使用此函式載入該值
在 emitReturn() 之後新增
static void emitConstant(Value value) { emitBytes(OP_CONSTANT, makeConstant(value)); }
首先,我們將值新增到常數表中,然後我們發射一個 OP_CONSTANT 指令,該指令在執行階段將其推送到堆疊上。為了在常數表中插入一個條目,我們依賴
在 emitReturn() 之後新增
static uint8_t makeConstant(Value value) { int constant = addConstant(currentChunk(), value); if (constant > UINT8_MAX) { error("Too many constants in one chunk."); return 0; } return (uint8_t)constant; }
大多數工作發生在 addConstant() 中,我們在較早的章節中定義了它。這會將給定的值新增到區塊常數表的末尾並回傳其索引。新函式的工作主要是確保我們沒有太多常數。由於 OP_CONSTANT 指令使用單一位元組作為索引操作數,因此我們只能在一個區塊中儲存和載入最多 256 個常數。
基本上就是這樣了。只要有一些適當的程式碼會消耗 TOKEN_NUMBER 符號,在函式指標陣列中查找 number(),然後呼叫它,我們現在就可以將數字字面值編譯為位元組碼。
17 . 4 . 2用於分組的括號
如果每個表達式都只有一個符號長度,那麼我們尚未想像的剖析函式指標陣列會很棒。唉,大多數都比較長。但是,許多表達式都以特定的符號開始。我們將這些稱為前綴表達式。例如,當我們剖析表達式且目前的符號為 ( 時,我們知道我們一定正在查看括號分組表達式。
事實證明,我們的函式指標陣列也可以處理這些。表達式類型的剖析函式可以像在常規的遞迴下降剖析器中一樣,消耗它想要的任何其他符號。以下是括號的運作方式
在 endCompiler() 之後新增
static void grouping() { expression(); consume(TOKEN_RIGHT_PAREN, "Expect ')' after expression."); }
同樣地,我們假設初始的 ( 已經被消耗。我們遞迴回呼到 expression() 中,以編譯括號之間的表達式,然後剖析結尾的結束符號 )。
就後端而言,分組表達式實際上沒有任何意義。它的唯一作用是語法的—它可以讓您在預期較高優先級的地方插入較低優先級的表達式。因此,它本身沒有執行階段語意,因此不會發射任何位元組碼。內部呼叫 expression() 負責產生括號內表達式的位元組碼。
17 . 4 . 3一元負號
一元負號也是前綴表達式,所以它也可以與我們的模型一起使用。
在 number() 之後新增
static void unary() { TokenType operatorType = parser.previous.type; // Compile the operand. expression(); // Emit the operator instruction. switch (operatorType) { case TOKEN_MINUS: emitByte(OP_NEGATE); break; default: return; // Unreachable. } }
前導的 - 符號已被消耗,並位於 parser.previous 中。我們從中抓取符號類型,以記錄我們正在處理哪個一元運算子。現在沒有必要,但當我們在下一章中使用相同的函式編譯 ! 運算子時,這會更有意義。
在 grouping() 中,我們遞迴呼叫 expression() 來編譯運算元。在那之後,我們發射執行負號的位元組碼。在運算元的位元組碼之後寫入負號指令似乎有點奇怪,因為 - 出現在左邊,但請從執行順序的角度來思考它
-
我們先評估運算元,這會在堆疊上留下它的值。
-
然後我們彈出該值,將其取負,並推送結果。
因此,OP_NEGATE 指令應該最後發射。這是編譯器工作的一部分—以它在原始程式碼中出現的順序剖析程式,並將其重新排列為執行發生的順序。
但是,此程式碼存在一個問題。它呼叫的 expression() 函式將剖析運算元的任何表達式,無論優先順序如何。一旦我們新增二元運算子和其他語法,這會做錯事。考慮一下
-a.b + c;
在這裡,- 的運算元應該只是 a.b 表達式,而不是整個 a.b + c。但是,如果 unary() 呼叫 expression(),後者會很樂意地處理所有剩餘的程式碼,包括 +。它會錯誤地將 - 視為比 + 低的優先順序。
在剖析一元 - 的運算元時,我們只需要編譯在特定優先順序或更高優先順序的表達式。在 jlox 的遞迴下降剖析器中,我們透過呼叫我們想要允許的最低優先順序表達式(在此案例中為 call())的剖析方法來完成此操作。每個用於剖析特定表達式的方法也剖析了任何較高優先順序的表達式,因此也包括優先順序表的其餘部分。
這裡 clox 中的剖析函式(例如 number() 和 unary())是不同的。每個都只剖析一種表達式類型。它們不會串聯以包括較高優先順序的表達式類型。我們需要一個不同的解決方案,它看起來像這樣
在 unary() 之後新增
static void parsePrecedence(Precedence precedence) { // What goes here? }
這個函式—一旦我們實作它—會從目前的 token 開始,解析任何給定優先權層級或更高的表達式。在我們可以寫這個函式的主體之前,我們還有一些其他設定要完成,但你可能可以猜到它會使用我一直在談論的那個解析函式指標表。現在,別太擔心它是如何運作的。為了將「優先權」作為參數,我們以數值方式定義它。
} Parser;
在 struct Parser 之後加入
typedef enum { PREC_NONE, PREC_ASSIGNMENT, // = PREC_OR, // or PREC_AND, // and PREC_EQUALITY, // == != PREC_COMPARISON, // < > <= >= PREC_TERM, // + - PREC_FACTOR, // * / PREC_UNARY, // ! - PREC_CALL, // . () PREC_PRIMARY } Precedence;
Parser parser;
這些是 Lox 中所有優先權層級,從最低到最高依序排列。由於 C 隱式地為枚舉提供依序遞增的數字,這表示 PREC_CALL 在數值上大於 PREC_UNARY。例如,假設編譯器正在處理一段類似這樣的程式碼:
-a.b + c
如果我們呼叫 parsePrecedence(PREC_ASSIGNMENT),它將解析整個表達式,因為 + 的優先權高於賦值。如果我們改為呼叫 parsePrecedence(PREC_UNARY),它將編譯 -a.b 並停止在那裡。它不會繼續處理 +,因為加法的優先權低於一元運算符。
有了這個函式,要填寫 expression() 中遺失的主體就輕而易舉了。
static void expression() {
在 expression() 中
取代 1 行
parsePrecedence(PREC_ASSIGNMENT);
}
我們只需解析最低優先權層級,它也涵蓋了所有更高優先權的表達式。現在,為了編譯一元表達式的運算元,我們呼叫這個新函式,並將其限制在適當的層級。
// Compile the operand.
在 unary() 中
取代 1 行
parsePrecedence(PREC_UNARY);
// Emit the operator instruction.
我們使用一元運算符自己的 PREC_UNARY 優先權,以允許像 !!doubleNegative 這樣的巢狀一元表達式。由於一元運算符的優先權相當高,這會正確地排除像二元運算符之類的東西。說到這個 . . .
17 . 5解析中綴表達式
二元運算符與先前的表達式不同,因為它們是中綴的。對於其他表達式,我們從第一個 token 就知道我們正在解析什麼。對於中綴表達式,我們在解析完其左運算元,然後偶然發現中間的運算符 token 之後,才知道我們正處於二元運算符的中間。
這是一個範例
1 + 2
讓我們逐步嘗試使用我們目前所知的來編譯它
-
我們呼叫
expression()。它反過來呼叫parsePrecedence(PREC_ASSIGNMENT)。 -
這個函式(一旦我們實作它)會看到開頭的數字 token,並識別出它正在解析一個數字字面值。它將控制權交給
number()。 -
number()建立一個常數,發出一個OP_CONSTANT,並返回到parsePrecedence()。
現在呢?對 parsePrecedence() 的呼叫應該消耗整個加法表達式,所以它需要以某種方式繼續下去。幸運的是,解析器正好在我們需要它的位置。現在我們已經編譯了開頭的數字表達式,下一個 token 是 +。這正是 parsePrecedence() 需要偵測到我們正處於中綴表達式中間的 token,並意識到我們已經編譯的表達式實際上是它的運算元。
所以這個假設的函式指標陣列不僅列出了解析以給定 token 開頭的表達式的函式。相反,它是一個函式指標表。一欄將前綴解析器函式與 token 類型關聯。第二欄將中綴解析器函式與 token 類型關聯。
我們將用作 TOKEN_PLUS、TOKEN_MINUS、TOKEN_STAR 和 TOKEN_SLASH 的中綴解析器的函式是這個
在 endCompiler() 之後新增
static void binary() { TokenType operatorType = parser.previous.type; ParseRule* rule = getRule(operatorType); parsePrecedence((Precedence)(rule->precedence + 1)); switch (operatorType) { case TOKEN_PLUS: emitByte(OP_ADD); break; case TOKEN_MINUS: emitByte(OP_SUBTRACT); break; case TOKEN_STAR: emitByte(OP_MULTIPLY); break; case TOKEN_SLASH: emitByte(OP_DIVIDE); break; default: return; // Unreachable. } }
當呼叫前綴解析器函式時,開頭的 token 已經被消耗了。中綴解析器函式甚至更in medias res—整個左運算元表達式已經被編譯,並且後續的中綴運算符也被消耗了。
左運算元先被編譯的事實運作良好。這表示在執行期間,該程式碼會先執行。當它執行時,它產生的值將會出現在堆疊上。這正是中綴運算符將需要它的地方。
然後我們來到這裡的 binary() 來處理其餘的算術運算符。這個函式會編譯右運算元,很像 unary() 編譯自己的尾隨運算元。最後,它會發出執行二元運算的位元碼指令。
當執行時,VM 會按順序執行左和右運算元程式碼,將它們的值留在堆疊上。然後它會執行運算符的指令。這會彈出兩個值,計算運算,並將結果推入。
這裡可能讓你注意到的是 getRule() 那一行。當我們解析右運算元時,我們再次需要擔心優先權。以像這樣的表達式為例
2 * 3 + 4
當我們解析 * 表達式的右運算元時,我們只需要捕獲 3,而不是 3 + 4,因為 + 的優先權低於 *。我們可以為每個二元運算符定義一個單獨的函式。每個函式都會呼叫 parsePrecedence(),並傳入其運算元的正確優先權層級。
但這有點乏味。每個二元運算符的右運算元優先權都比它自己的層級高一個層級。我們可以透過我們稍後會介紹的 getRule() 來動態查找它。使用該函式,我們呼叫 parsePrecedence(),其層級比此運算符的層級高一個層級。
這樣一來,即使它們具有不同的優先權,我們也可以為所有二元運算符使用單個 binary() 函式。
17 . 6Pratt 解析器
我們現在已經佈局了編譯器的所有組件。我們為每個語法產生式都有一個函式:number()、grouping()、unary() 和 binary()。我們仍然需要實作 parsePrecedence() 和 getRule()。我們也知道我們需要一個表格,給定一個 token 類型,可以讓我們找到
-
編譯以該類型 token 開頭的前綴表達式的函式、
-
編譯左運算元後接該類型 token 的中綴表達式的函式,以及
-
使用該 token 作為運算符的中綴表達式的優先權。
我們將這三個屬性包裝在一個小的結構中,該結構表示解析器表中的單一行。
} Precedence;
在 enum Precedence 之後加入
typedef struct { ParseFn prefix; ParseFn infix; Precedence precedence; } ParseRule;
Parser parser;
該 ParseFn 類型是一個簡單的 typedef,用於不帶引數且不返回任何內容的函式類型。
} Precedence;
在 enum Precedence 之後加入
typedef void (*ParseFn)();
typedef struct {
驅動我們整個解析器的表是一個 ParseRules 陣列。我們已經談論它很久了,最後你終於看到了它。
在 unary() 之後新增
ParseRule rules[] = { [TOKEN_LEFT_PAREN] = {grouping, NULL, PREC_NONE}, [TOKEN_RIGHT_PAREN] = {NULL, NULL, PREC_NONE}, [TOKEN_LEFT_BRACE] = {NULL, NULL, PREC_NONE}, [TOKEN_RIGHT_BRACE] = {NULL, NULL, PREC_NONE}, [TOKEN_COMMA] = {NULL, NULL, PREC_NONE}, [TOKEN_DOT] = {NULL, NULL, PREC_NONE}, [TOKEN_MINUS] = {unary, binary, PREC_TERM}, [TOKEN_PLUS] = {NULL, binary, PREC_TERM}, [TOKEN_SEMICOLON] = {NULL, NULL, PREC_NONE}, [TOKEN_SLASH] = {NULL, binary, PREC_FACTOR}, [TOKEN_STAR] = {NULL, binary, PREC_FACTOR}, [TOKEN_BANG] = {NULL, NULL, PREC_NONE}, [TOKEN_BANG_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_EQUAL_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_GREATER] = {NULL, NULL, PREC_NONE}, [TOKEN_GREATER_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_LESS] = {NULL, NULL, PREC_NONE}, [TOKEN_LESS_EQUAL] = {NULL, NULL, PREC_NONE}, [TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE}, [TOKEN_STRING] = {NULL, NULL, PREC_NONE}, [TOKEN_NUMBER] = {number, NULL, PREC_NONE}, [TOKEN_AND] = {NULL, NULL, PREC_NONE}, [TOKEN_CLASS] = {NULL, NULL, PREC_NONE}, [TOKEN_ELSE] = {NULL, NULL, PREC_NONE}, [TOKEN_FALSE] = {NULL, NULL, PREC_NONE}, [TOKEN_FOR] = {NULL, NULL, PREC_NONE}, [TOKEN_FUN] = {NULL, NULL, PREC_NONE}, [TOKEN_IF] = {NULL, NULL, PREC_NONE}, [TOKEN_NIL] = {NULL, NULL, PREC_NONE}, [TOKEN_OR] = {NULL, NULL, PREC_NONE}, [TOKEN_PRINT] = {NULL, NULL, PREC_NONE}, [TOKEN_RETURN] = {NULL, NULL, PREC_NONE}, [TOKEN_SUPER] = {NULL, NULL, PREC_NONE}, [TOKEN_THIS] = {NULL, NULL, PREC_NONE}, [TOKEN_TRUE] = {NULL, NULL, PREC_NONE}, [TOKEN_VAR] = {NULL, NULL, PREC_NONE}, [TOKEN_WHILE] = {NULL, NULL, PREC_NONE}, [TOKEN_ERROR] = {NULL, NULL, PREC_NONE}, [TOKEN_EOF] = {NULL, NULL, PREC_NONE}, };
你可以看到 grouping 和 unary 如何針對它們各自的 token 類型插入前綴解析器欄位中。在下一欄中,binary 被連接到四個算術中綴運算符。這些中綴運算符的優先權也設定在最後一欄。
除此之外,表的其餘部分都填滿了 NULL 和 PREC_NONE。這些空單元格中的大多數是因為沒有與這些 token 相關的表達式。你不能用 else 開頭一個表達式,而 } 會造成相當令人困惑的中綴運算符。
但是,我們也沒有填寫完整的語法。在後面的章節中,當我們新增新的表達式類型時,這些插槽中的一些將會加入函式。我喜歡這種解析方法的一點是,它可以非常容易地看出哪些 token 被語法使用,哪些是可用的。
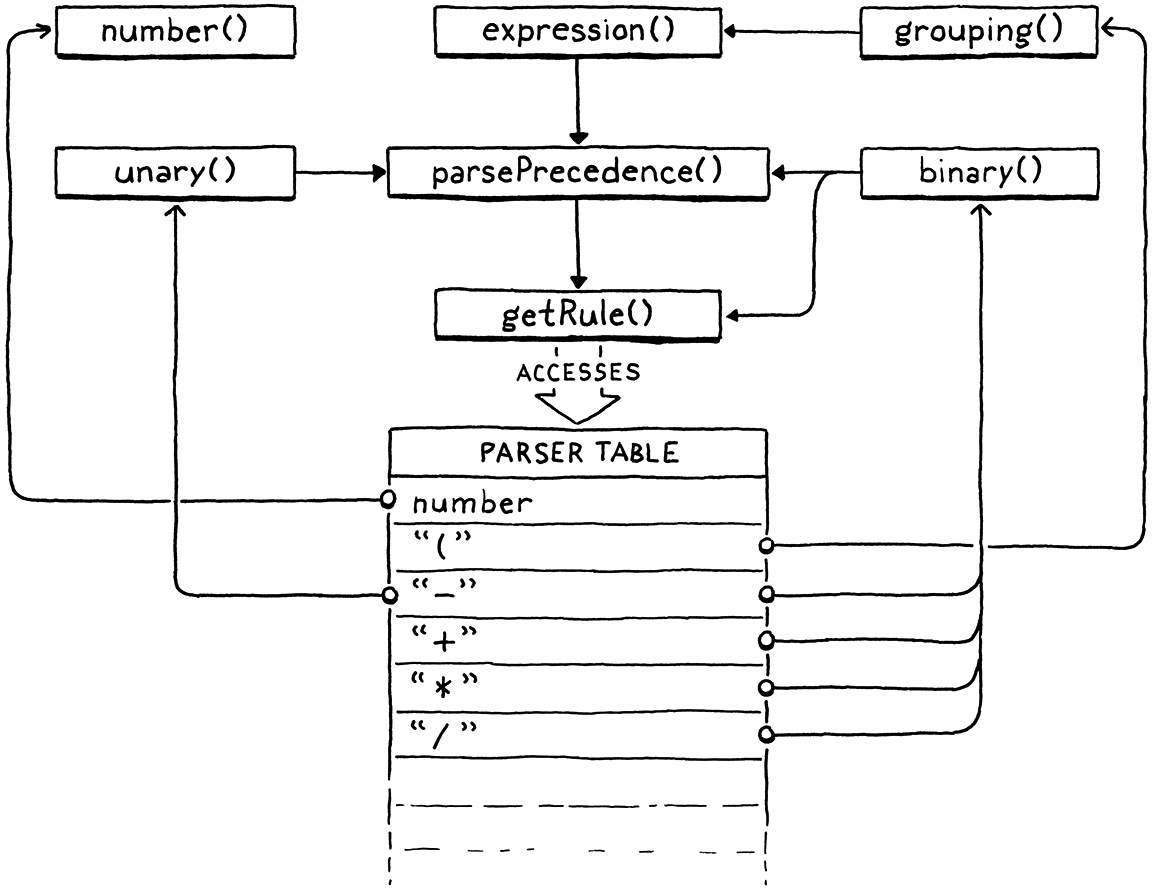
現在我們有了這個表,我們終於可以編寫使用它的程式碼了。這是我們的 Pratt 解析器誕生的地方。最容易定義的函式是 getRule()。
在 parsePrecedence() 之後加入
static ParseRule* getRule(TokenType type) { return &rules[type]; }
它只是返回給定索引的規則。它由 binary() 呼叫以查找目前運算符的優先權。此函式僅存在以處理 C 程式碼中的宣告循環。binary() 是在規則表之前定義的,以便該表可以儲存指向它的指標。這表示 binary() 的主體無法直接存取該表。
相反地,我們將查找包裝在一個函式中。這讓我們可以在 binary() 的定義之前前向宣告 getRule(),然後在表之後定義 getRule()。我們需要幾個其他前向宣告來處理我們的語法是遞迴的事實,所以讓我們把它們都處理掉。
emitReturn(); }
在 endCompiler() 之後新增
static void expression(); static ParseRule* getRule(TokenType type); static void parsePrecedence(Precedence precedence);
static void binary() {
如果你正在跟著實作 clox,請特別注意那些告訴你程式碼片段應該放在哪裡的小註解。不過別擔心,就算你放錯了,C 編譯器也會很樂意告訴你。
17 . 6 . 1使用優先順序進行解析
現在我們進入有趣的部分了。負責協調我們定義的所有解析函式的大師是 parsePrecedence()。我們先從解析前綴表達式開始。
static void parsePrecedence(Precedence precedence) {
在 parsePrecedence() 函式中
取代 1 行
advance(); ParseFn prefixRule = getRule(parser.previous.type)->prefix; if (prefixRule == NULL) { error("Expect expression."); return; } prefixRule();
}
我們讀取下一個 token 並查找對應的 ParseRule。如果沒有前綴解析器,則該 token 必定是語法錯誤。我們回報錯誤並返回呼叫者。
否則,我們呼叫該前綴解析函式,讓它執行它的工作。該前綴解析器會編譯剩餘的前綴表達式,消耗任何它需要的其他 token,然後返回此處。中綴表達式是比較有趣的部分,因為優先順序會起作用。實作方式非常簡單。
prefixRule();
在 parsePrecedence() 函式中
while (precedence <= getRule(parser.current.type)->precedence) { advance(); ParseFn infixRule = getRule(parser.previous.type)->infix; infixRule(); }
}
這就是全部了。真的。以下是整個函式的工作原理:在 parsePrecedence() 的開頭,我們會查找目前 token 的前綴解析器。根據定義,第一個 token *永遠*都會屬於某種前綴表達式。它可能會變成巢狀,作為一個或多個中綴表達式中的運算元,但當你從左到右讀取程式碼時,你碰到的第一個 token 總是屬於前綴表達式。
在解析完畢後,這可能會消耗更多 token,前綴表達式就完成了。現在我們為下一個 token 尋找中綴解析器。如果我們找到一個,這表示我們已經編譯的前綴表達式可能成為它的運算元。但前提是呼叫 parsePrecedence() 的 precedence 必須夠低,才能允許該中綴運算子。
如果下一個 token 的優先順序太低,或者根本不是中綴運算子,那我們就完成了。我們已經解析了我們能夠解析的表達式。否則,我們會消耗該運算子,並將控制權移交給我們找到的中綴解析器。它會消耗它需要的任何其他 token(通常是右運算元),然後返回 parsePrecedence()。然後我們繞回迴圈,查看*下一個* token 是否也是一個有效的中綴運算子,可以將整個前面的表達式作為其運算元。我們會像這樣持續迴圈,處理中綴運算子及其運算元,直到我們碰到一個不是中綴運算子的 token 或優先順序太低的 token 而停止。
這是一大段文字,但如果你真的想與 Vaughan Pratt 心靈相通並完全理解這個演算法,請在偵錯工具中逐步執行解析器,讓它處理一些表達式。或許圖片會有幫助。只有少數幾個函式,但它們彼此巧妙地交織在一起
稍後,我們需要調整本章中的程式碼以處理賦值。但除此之外,我們所寫的程式碼涵蓋了本書剩餘部分的所有表達式編譯需求。當我們加入新的表達式類型時,我們會將額外的解析函式插入表格中,但 parsePrecedence() 已經完成。
17 . 7傾印 Chunk
當我們在編譯器的核心時,我們應該加入一些儀器設備。為了協助偵錯產生的位元組碼,我們將加入對在編譯器完成時傾印 chunk 的支援。我們稍早手動撰寫 chunk 時有一些暫時的記錄。現在我們會加入一些真正的程式碼,以便我們在需要時隨時啟用它。
由於這不是給終端使用者使用的,我們將它隱藏在一個旗標後面。
#include <stdint.h>
#define DEBUG_PRINT_CODE
#define DEBUG_TRACE_EXECUTION
當該旗標被定義時,我們會使用現有的「除錯」模組來印出 chunk 的位元組碼。
emitReturn();
在 endCompiler() 函式中
#ifdef DEBUG_PRINT_CODE if (!parser.hadError) { disassembleChunk(currentChunk(), "code"); } #endif
}
我們只有在程式碼沒有錯誤時才執行此動作。在語法錯誤之後,編譯器會繼續執行,但它處於某種奇怪的狀態,可能會產生損壞的程式碼。這無傷大雅,因為它不會被執行,但如果我們嘗試讀取它,我們只會把自己搞糊塗。
最後,要存取 disassembleChunk(),我們需要包含它的標頭。
#include "scanner.h"
#ifdef DEBUG_PRINT_CODE #include "debug.h" #endif
typedef struct {
我們做到了!這是我們在 VM 的編譯和執行管道中安裝的最後一個主要部分。我們的直譯器*看起來*不怎麼樣,但它的內部正在掃描、解析、編譯成位元組碼,然後執行。
啟動 VM 並輸入一個表達式。如果我們做的一切都正確,它應該會計算並印出結果。我們現在有一個過度設計的算術計算機。我們在接下來的章節中還有很多語言功能要加入,但基礎已經就位。
挑戰
-
要真正理解解析器,你需要查看執行緒如何穿過有趣的解析函式—
parsePrecedence()以及儲存在表格中的解析函式。以下列這個(奇怪的)表達式為例(-1 + 2) * 3 - -4
寫出這些函式如何被呼叫的追蹤紀錄。顯示它們被呼叫的順序、哪個呼叫哪個,以及傳遞給它們的參數。
-
TOKEN_MINUS的 ParseRule 列同時具有前綴和中綴函式指標。這是因為-既是前綴運算子(一元否定),也是中綴運算子(減法)。在完整的 Lox 語言中,還有哪些 token 可以同時用於前綴和中綴位置?在 C 或你選擇的另一種語言中呢?
-
你可能對由 token 分隔的多個運算元組成的複雜「mixfix」表達式感到好奇。C 的條件或「三元」運算子
?:是廣為人知的一個。為編譯器加入對該運算子的支援。你不必產生任何位元組碼,只需展示你將如何將它連接到解析器並處理運算元。
設計筆記:它只是解析
我將在此處提出一個會不受一些編譯器和語言人員歡迎的主張。如果你不同意,沒關係。就我個人而言,我從強烈表達但我不認同的觀點中學到的東西,比從好幾頁的限定詞和模稜兩可的說法中學到的更多。我的主張是*解析並不重要*。
多年來,許多程式語言人員,尤其是在學術界,都*非常*投入解析器,並非常認真地看待它們。最初,是編譯器人員投入到 編譯器編譯器、LALR 和其他類似的東西中。《龍書》的前半部分是一封寫給解析器產生器奇蹟的長情書。
後來,函數式程式設計人員投入到解析器組合子、Packrat 解析器和其他類型的東西中。因為,很明顯地,如果你給一個函數式程式設計師一個問題,他們做的第一件事就是掏出一大堆高階函式。
在數學和演算法分析領域,長期以來一直有研究證明各種解析技術的時間和記憶體使用量、將解析問題轉換為其他問題並來回轉換,以及為不同的語法分配複雜度類別。
在某個層面上,這些東西很重要。如果你正在實作一種語言,你會希望確保你的解析器不會呈指數級增長,並花費 7,000 年來解析語法中的奇怪邊緣案例。解析器理論可以給你這種約束。作為一種智力練習,學習解析技術也很有趣且有回報。
但是,如果你的目標只是實作一種語言並將它呈現在使用者面前,那麼幾乎所有這些東西都不重要。很容易被那些熱衷於此的人的熱情所激發,認為你的前端*需要*某種令人驚嘆的產生式組合子解析器工廠。我見過有人花費大量時間,使用當今流行的程式庫或技術來編寫和重寫他們的解析器。
這些時間並沒有為你的使用者帶來任何價值。如果你只是想完成你的解析器,請選擇一種標準技術,使用它,然後繼續前進。遞迴下降、Pratt 解析和像 ANTLR 或 Bison 這樣的流行解析器產生器都很好。
把你節省下來沒有重寫解析程式碼的時間,花在改進你的編譯器顯示給使用者的編譯錯誤訊息上。良好的錯誤處理和報告對使用者來說,比你在前端投入的幾乎所有其他事情都更有價值。