位元組碼區塊
如果你發現你幾乎所有時間都花在理論上,那就開始將一些注意力轉向實務;這會改善你的理論。如果你發現你幾乎所有時間都花在實務上,那就開始將一些注意力轉向理論;這會改善你的實務。
Donald Knuth
我們已經有了使用 jlox 完整實作的 Lox,所以為什麼這本書還沒結束?部分原因是 jlox 依賴 JVM 為我們做很多事情。如果我們想要了解直譯器如何運作到最底層,我們需要自己建構這些零組件。
jlox 不夠用的另一個更根本原因是它太慢了。樹狀遍歷直譯器對於某些高階、宣告式語言來說還可以,但對於通用的、命令式語言—甚至是像 Lox 這樣的「腳本」語言—就行不通了。看看這個小腳本:
fun fib(n) { if (n < 2) return n; return fib(n - 1) + fib(n - 2); } var before = clock(); print fib(40); var after = clock(); print after - before;
在我的筆記型電腦上,jlox 大約需要 72 秒才能執行完。而一個等效的 C 程式則在半秒內完成。我們的動態型別腳本語言永遠不會像具有手動記憶體管理的靜態型別語言那麼快,但我們不需要容忍慢兩個數量級以上。
我們可以拿 jlox 並在效能分析器中執行,開始調整和修改熱點,但這只會將我們帶到那裡而已。執行模型—走訪 AST—從根本上來說是錯誤的設計。我們無法將其微調到我們想要的效能,就像你無法將 AMC Gremlin 打磨成 SR-71 Blackbird 一樣。
我們需要重新思考核心模型。本章介紹該模型,位元組碼,並開始我們新的直譯器 clox。
14.1什麼是位元組碼?
在工程學中,很少有選擇是沒有取捨的。為了更好地理解我們為什麼選擇位元組碼,讓我們將其與幾個替代方案進行比較。
14.1.1為什麼不走訪 AST?
我們現有的直譯器有幾項優點:
-
首先,我們已經寫好了它。它完成了。而且它完成的主要原因是這種風格的直譯器實作起來真的非常簡單。程式碼的執行階段表示直接對應到語法。從解析器到我們在執行階段需要的資料結構幾乎毫不費力。
-
它是可移植的。我們目前的直譯器是用 Java 撰寫的,可以在 Java 支援的任何平台上執行。我們可以採用相同的方法,用 C 寫一個新的實作,並在基本上所有平台上編譯和執行我們的語言。
這些都是真正的優點。但是,另一方面,它沒有記憶體效率。每個語法片段都會變成一個 AST 節點。像 1 + 2 這樣小的 Lox 表達式會變成一大堆物件,它們之間有很多指標,如下所示:
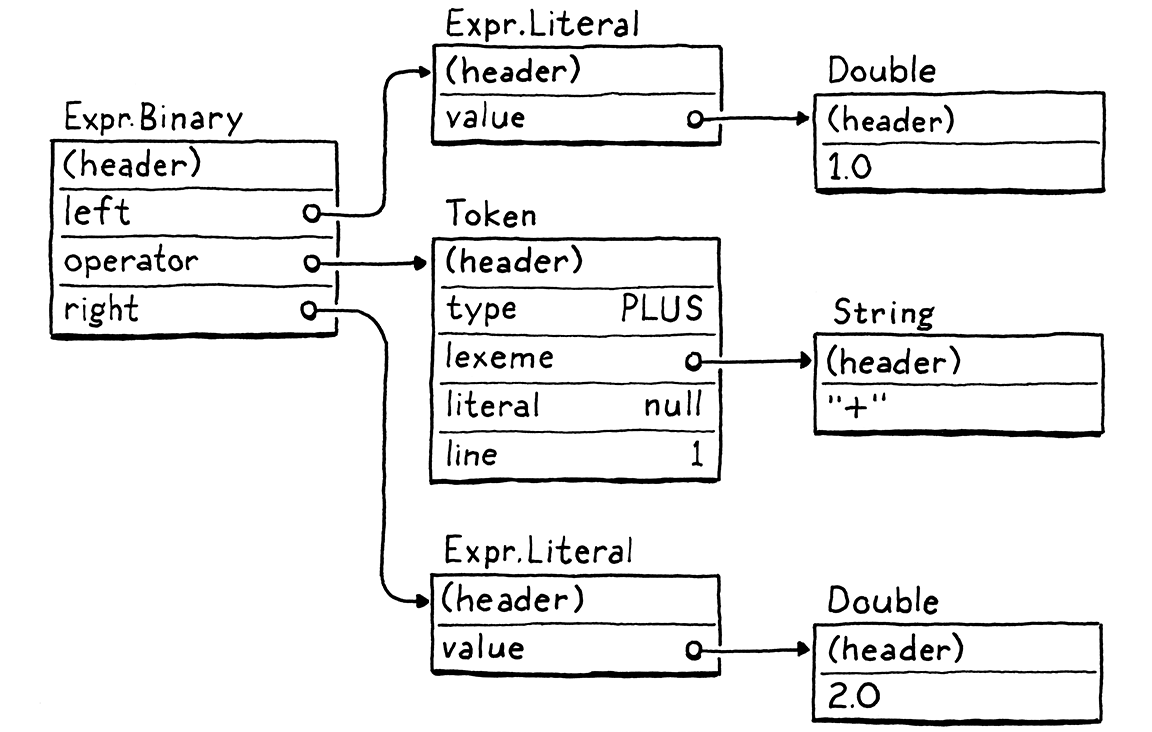
每個指標都會為物件增加額外的 32 或 64 位元的開銷。更糟糕的是,將我們的資料散落在堆積中一個鬆散連接的物件網路上,對空間局部性產生了不良影響。
現代 CPU 處理資料的速度比它們從 RAM 中提取資料的速度快得多。為了彌補這一點,晶片有多層快取。如果它需要的記憶體片段已經在快取中,則可以更快地載入。我們說的速度快了 100 倍以上。
資料是如何進入快取的?機器會推測性地將內容放入其中。它的啟發式方法非常簡單。每當 CPU 從 RAM 中讀取一個位元的資料時,它會拉取一整小捆相鄰的位元組並將它們塞入快取中。
如果我們的程式接下來請求一些足夠接近於快取行內的資料,我們的 CPU 就會像工廠裡運作良好的輸送帶一樣運行。我們真的想要利用這一點。為了有效地使用快取,我們在記憶體中表示程式碼的方式應該是密集的,並且像讀取它一樣排序。
現在抬頭看看那棵樹。這些子物件可能在任何地方。樹狀遍歷器採取的每一步都跟隨著對子節點的參考,可能會超出快取的範圍,並迫使 CPU 停止,直到可以從 RAM 中吸入新的資料塊。僅這些樹節點的開銷及其所有的指標欄位和物件標頭往往會將物件彼此推開並推出快取。
我們的 AST 走訪器在介面分派和訪問者模式周圍也有其他開銷,但光是局部性問題就足以證明更好的程式碼表示的合理性。
14.1.2為什麼不編譯成原生程式碼?
如果你想要真正快速,你會想要擺脫所有這些間接層。直接到最底層。機器碼。聽起來甚至都很快。機器碼。
直接編譯到晶片支援的原生指令集是速度最快的語言所做的事情。自從工程師實際上手寫機器碼程式的早期以來,針對原生程式碼一直是最高效的選擇。
如果你以前從未寫過任何機器碼,或其稍微更人性化的表親組合語言,我將給你最溫和的介紹。原生程式碼是一連串密集的運算,直接以二進制編碼。每個指令的長度為一到幾個位元組,而且幾乎令人難以置信地低階。「將值從這個位址移動到這個暫存器。」「將這兩個暫存器中的整數相加。」諸如此類的東西。
CPU 按順序處理指令,解碼並執行每個指令。沒有像我們 AST 這樣的樹狀結構,控制流程是透過直接從程式碼中的一點跳到另一個點來處理的。沒有間接、沒有開銷、沒有不必要的跳過或追逐指標。
快如閃電,但這種效能是有代價的。首先,編譯成原生程式碼並不容易。當今廣泛使用的許多晶片都有龐大而複雜的架構,其中包含數十年來累積的大量指令。它們需要複雜的暫存器分配、管線化和指令排程。
而且,當然,你已經放棄了可移植性。花幾年時間掌握某些架構,這仍然只會讓你接觸到目前流行的幾個指令集中的一個。為了讓你的語言可以在所有這些平台上運行,你需要學習所有這些指令集,並為每個指令集編寫一個單獨的後端。
14.1.3什麼是位元組碼?
將這兩點記在腦海中。一方面,樹狀遍歷直譯器簡單、可移植且速度慢。另一方面,原生程式碼複雜且特定於平台,但速度很快。位元組碼位於中間。它保留了樹狀遍歷器的可移植性—我們不會在這本書中接觸組合語言。它犧牲了一些簡單性來換取效能提升,但沒有像完全原生程式碼那麼快。
在結構上,位元組碼類似於機器碼。它是密集的、線性的二進制指令序列。這可以降低開銷並與快取良好配合。但是,它是一個比任何真實晶片都簡單得多的高階指令集。(在許多位元組碼格式中,每個指令只有一個位元組長,因此稱為「位元組碼」。)
想像一下,你正在從某個來源語言編寫原生編譯器,並且你可以隨意定義最容易針對的架構。位元組碼有點像那樣。它是一個理想化的虛擬指令集,可以讓身為編譯器撰寫者的你更輕鬆。
當然,虛擬架構的問題在於它不存在。我們透過編寫模擬器來解決這個問題—一個用軟體編寫的模擬晶片,一次解譯一個位元組碼指令。如果你願意的話,可以稱為虛擬機器 (VM)。
該模擬層增加了開銷,這是位元組碼比原生程式碼慢的主要原因。但作為回報,它為我們提供了可移植性。用像 C 這樣的語言編寫我們的 VM,這種語言已經在我們關心的所有機器上都支援,而且我們可以在我們喜歡的任何硬體上執行我們的模擬器。
這就是我們將用我們新的直譯器 clox 所採取的路徑。我們將追隨 Python、Ruby、Lua、OCaml、Erlang 等主要實作的腳步。在許多方面,我們 VM 的設計將與我們先前直譯器的結構相似
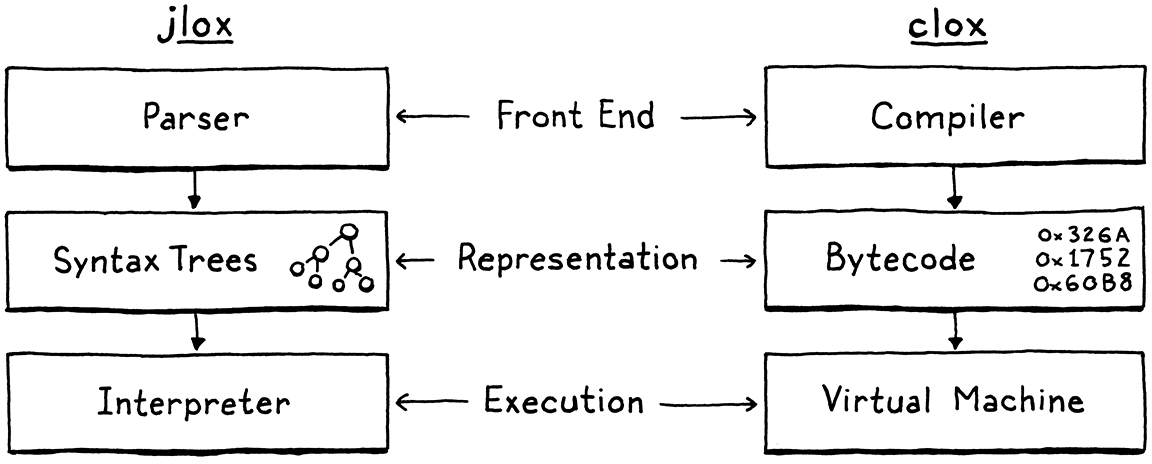
當然,我們不會嚴格按照順序實作這些階段。就像我們之前的直譯器一樣,我們會來回跳動,一次建構一個語言功能。在本章中,我們將建立應用程式的骨架,並建立儲存和表示位元組碼區塊所需的資料結構。
14.2開始
從哪裡開始好呢?當然是從 main() 開始!打開你可靠的文字編輯器,開始輸入程式碼。
建立新檔案
#include "common.h" int main(int argc, const char* argv[]) { return 0; }
從這顆小小的種子,我們將成長為整個虛擬機器。由於 C 語言給我們的東西很少,我們首先需要花一些時間來改良土壤。其中一些內容會寫入這個標頭檔。
建立新檔案
#ifndef clox_common_h #define clox_common_h #include <stdbool.h> #include <stddef.h> #include <stdint.h> #endif
有一些類型和常數我們會整個直譯器中使用,這裡是一個方便放置它們的地方。目前,它包括了受人尊敬的 NULL、size_t、不錯的 C99 布林值 bool,以及明確大小的整數類型—uint8_t 和其他相關類型。
14.3指令區塊
接下來,我們需要一個模組來定義我們的程式碼表示法。我一直在使用「區塊」來指稱位元組碼序列,所以我們就讓它成為該模組的正式名稱。
建立新檔案
#ifndef clox_chunk_h #define clox_chunk_h #include "common.h" #endif
在我們的位元組碼格式中,每個指令都有一個位元組的**操作碼**(普遍縮寫為 **opcode**)。該數字控制我們正在處理的指令類型—加法、減法、查詢變數等等。我們在這裡定義這些操作碼。
#include "common.h"
typedef enum { OP_RETURN, } OpCode;
#endif
目前,我們先從單一指令 OP_RETURN 開始。當我們擁有功能齊全的虛擬機器時,這個指令將表示「從目前函式返回」。我承認這目前還不是很有用,但我們必須從某個地方開始,而這是一個特別簡單的指令,原因我們稍後會說明。
14.3.1指令的動態陣列
位元組碼是一系列的指令。最終,我們還會將一些其他資料與指令一起儲存,所以我們現在就建立一個結構體來保存它們。
} OpCode;
在 enum OpCode 之後加入
typedef struct { uint8_t* code; } Chunk;
#endif
目前,這只是一個位元組陣列的包裝器。由於我們在開始編譯區塊之前不知道陣列需要多大,因此它必須是動態的。動態陣列是我最喜歡的資料結構之一。這聽起來像是在說香草是我最喜歡的冰淇淋口味,但請聽我說完。動態陣列提供:
-
快取友善、密集儲存
-
常數時間索引元素查詢
-
常數時間附加到陣列末尾
這些特性正是我們在 jlox 中一直使用動態陣列的原因,只是當時它偽裝成 Java 的 ArrayList 類別。現在我們使用 C 語言,我們可以自己建立一個動態陣列。如果你對動態陣列有點生疏,它的概念其實很簡單。除了陣列本身之外,我們還保留兩個數字:我們已配置的陣列元素數量(「容量」)以及這些已配置的項目中有多少實際正在使用中(「計數」)。
typedef struct {
在 struct Chunk 中
int count; int capacity;
uint8_t* code; } Chunk;
當我們加入一個元素時,如果計數小於容量,則表示陣列中已經有可用的空間。我們直接將新元素儲存在那裡,並增加計數。
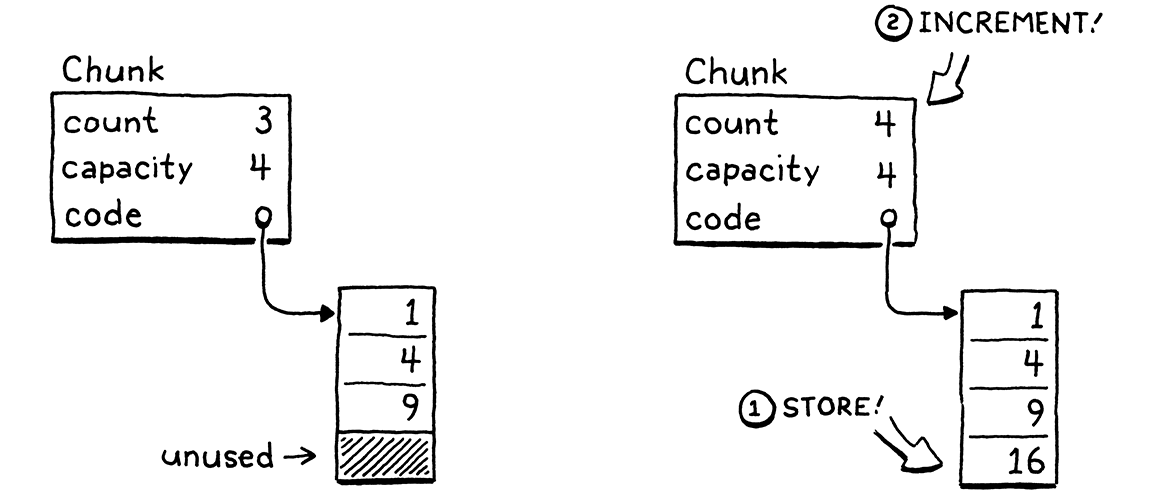
如果我們沒有剩餘容量,那麼這個過程就會稍微複雜一些。
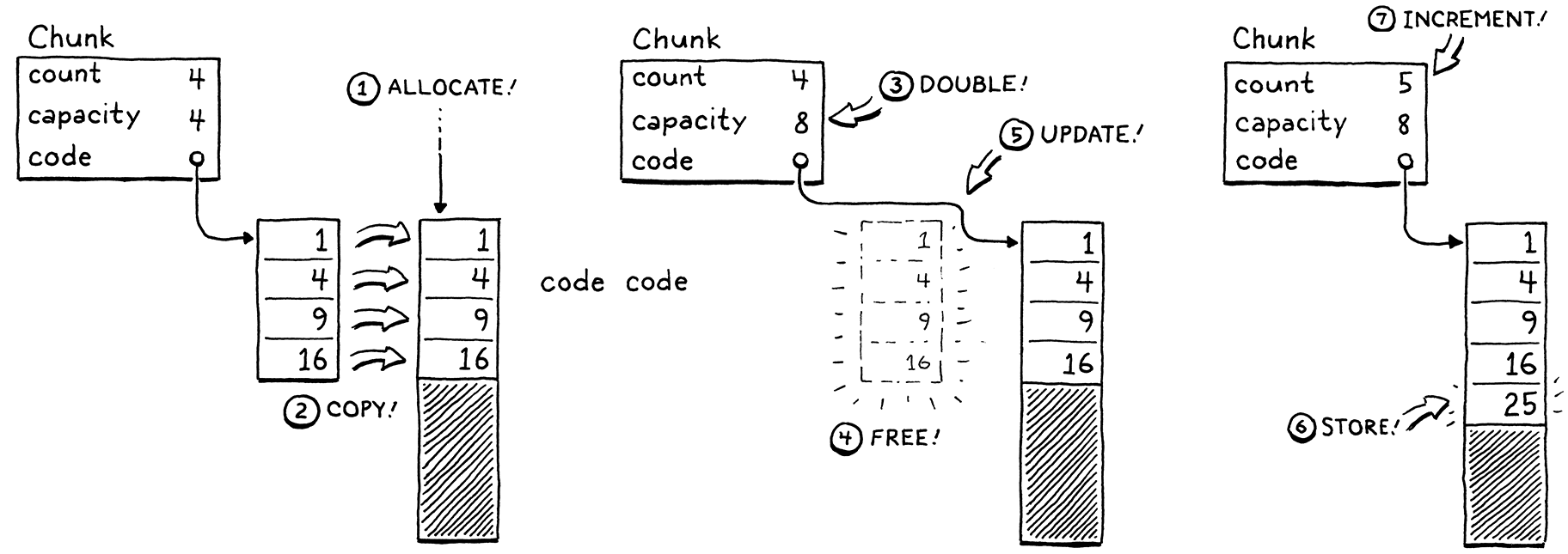
- 配置一個具有更大容量的新陣列。
- 將現有元素從舊陣列複製到新陣列。
- 儲存新的
capacity。 - 刪除舊陣列。
- 更新
code以指向新陣列。 - 既然有空間了,將元素儲存在新陣列中。
- 更新
count。
我們的結構體已經準備就緒,現在讓我們實作處理它的函式。C 語言沒有建構子,因此我們宣告一個函式來初始化新的區塊。
} Chunk;
在 struct Chunk 之後加入
void initChunk(Chunk* chunk);
#endif
並這樣實作它:
建立新檔案
#include <stdlib.h> #include "chunk.h" void initChunk(Chunk* chunk) { chunk->count = 0; chunk->capacity = 0; chunk->code = NULL; }
動態陣列從完全空的狀態開始。我們甚至還沒有配置原始陣列。要將一個位元組附加到區塊的末尾,我們使用一個新的函式。
void initChunk(Chunk* chunk);
在 initChunk() 之後加入
void writeChunk(Chunk* chunk, uint8_t byte);
#endif
這是發生有趣工作的地方。
在 initChunk() 之後加入
void writeChunk(Chunk* chunk, uint8_t byte) { if (chunk->capacity < chunk->count + 1) { int oldCapacity = chunk->capacity; chunk->capacity = GROW_CAPACITY(oldCapacity); chunk->code = GROW_ARRAY(uint8_t, chunk->code, oldCapacity, chunk->capacity); } chunk->code[chunk->count] = byte; chunk->count++; }
我們需要做的第一件事是查看目前的陣列是否有足夠的容量容納新的位元組。如果沒有,則我們首先需要擴大陣列以騰出空間。(在第一次寫入時,當陣列為 NULL 且 capacity 為 0 時,也會遇到這種情況。)
為了擴大陣列,首先我們要找出新的容量,並將陣列擴大到該大小。這兩個底層的記憶體操作都在一個新的模組中定義。
#include "chunk.h"
#include "memory.h"
void initChunk(Chunk* chunk) {
這足以讓我們開始。
建立新檔案
#ifndef clox_memory_h #define clox_memory_h #include "common.h" #define GROW_CAPACITY(capacity) \ ((capacity) < 8 ? 8 : (capacity) * 2) #endif
這個巨集會根據給定的目前容量計算新的容量。為了獲得我們想要的效能,重點是它會根據舊的大小進行 *縮放*。我們以二的倍數擴大,這很典型。1.5 倍是另一個常見的選擇。
我們還會處理目前容量為零的情況。在這種情況下,我們會直接跳到八個元素,而不是從一個元素開始。當陣列非常小時,這可以避免一些額外的記憶體流失,但代價是在非常小的區塊上浪費一些位元組。
一旦我們知道所需的容量,我們就會使用 GROW_ARRAY() 建立或擴大陣列到該大小。
#define GROW_CAPACITY(capacity) \
((capacity) < 8 ? 8 : (capacity) * 2)
#define GROW_ARRAY(type, pointer, oldCount, newCount) \ (type*)reallocate(pointer, sizeof(type) * (oldCount), \ sizeof(type) * (newCount)) void* reallocate(void* pointer, size_t oldSize, size_t newSize);
#endif
這個巨集會將對 reallocate() 的函式呼叫整理得更漂亮,而真正的運算發生在這裡。巨集本身會負責取得陣列元素類型的大小,並將產生的 void* 強制轉型為正確類型的指標。
這個 reallocate() 函式是我們將在 clox 中用於所有動態記憶體管理的單一函式—配置記憶體、釋放記憶體,以及變更現有配置的大小。將所有這些操作都透過單一函式路由,在我們稍後加入需要追蹤使用多少記憶體的垃圾收集器時,將會非常重要。
傳遞給 reallocate() 的兩個大小引數會控制要執行的操作:
| oldSize | newSize | 操作 |
| 0 | 非零 | 配置新的區塊。 |
| 非零 | 0 | 0 |
| 非零 | 釋放配置。 | 小於 oldSize |
| 非零 | 縮小現有配置。 | 大於 oldSize |
擴大現有配置。
建立新檔案
#include <stdlib.h> #include "memory.h" void* reallocate(void* pointer, size_t oldSize, size_t newSize) { if (newSize == 0) { free(pointer); return NULL; } void* result = realloc(pointer, newSize); return result; }
memory.c,建立新檔案
當 newSize 為零時,我們透過呼叫 free() 來自行處理釋放配置的情況。否則,我們依賴 C 標準函式庫的 realloc() 函式。該函式方便地支援我們政策的其他三個方面。當 oldSize 為零時,realloc() 等同於呼叫 malloc()。
有趣的情況是當 oldSize 和 newSize 都不為零時。這些情況會告訴 realloc() 調整先前配置的區塊的大小。如果新大小小於現有的記憶體區塊,它只會更新區塊的大小並傳回你提供的相同指標。如果新大小較大,它會嘗試擴大現有的記憶體區塊。
只有在該區塊之後的記憶體沒有被使用的情況下,它才能這麼做。如果沒有空間擴大區塊,realloc() 會改為配置一個所需大小的 *新* 記憶體區塊,複製舊位元組,釋放舊區塊,然後傳回新區塊的指標。請記住,這正是我們動態陣列所需的行為。
void* result = realloc(pointer, newSize);
由於電腦是有限的物質塊,而不是電腦科學理論希望我們相信的完美數學抽象,如果沒有足夠的記憶體,配置可能會失敗,並且
realloc() 會傳回 NULL。我們應該處理這種情況。if (result == NULL) exit(1);
return result;
memory.c,在 reallocate() 中
malloc() 的許多實作會將配置的大小儲存在傳回位址 *之前* 的記憶體中。
void initChunk(Chunk* chunk);
在 initChunk() 之後加入
void freeChunk(Chunk* chunk);
void writeChunk(Chunk* chunk, uint8_t byte);
好的,我們可以建立新的區塊並在其中寫入指令。我們完成了嗎?還沒!我們現在使用的是 C 語言,請記住,我們必須像過去一樣自己管理記憶體,這也表示要 *釋放* 記憶體。
在 initChunk() 之後加入
void freeChunk(Chunk* chunk) { FREE_ARRAY(uint8_t, chunk->code, chunk->capacity); initChunk(chunk); }
實作方式如下:
#define GROW_ARRAY(type, pointer, oldCount, newCount) \
(type*)reallocate(pointer, sizeof(type) * (oldCount), \
sizeof(type) * (newCount))
#define FREE_ARRAY(type, pointer, oldCount) \ reallocate(pointer, sizeof(type) * (oldCount), 0)
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
我們會釋放所有記憶體,然後呼叫 initChunk() 將欄位歸零,讓區塊處於明確定義的空狀態。為了釋放記憶體,我們再加入一個巨集。
就像 GROW_ARRAY() 一樣,這是對 reallocate() 呼叫的包裝器。它透過傳入零作為新的大小來釋放記憶體。我知道,這是一堆乏味的底層東西。別擔心,我們在後面的章節中會大量使用這些內容,並且將以更高的層次進行程式設計。但是,在我們可以做到這一點之前,我們必須先打好基礎。
14.4反組譯區塊
int main(int argc, const char* argv[]) {
現在我們有一個用於建立位元組碼區塊的小模組。讓我們試著手動建立一個範例區塊。
Chunk chunk; initChunk(&chunk); writeChunk(&chunk, OP_RETURN); freeChunk(&chunk);
return 0;
別忘了 include。
#include "common.h"
#include "chunk.h"
int main(int argc, const char* argv[]) {
執行它並試試看。它成功了嗎?呃 . . .誰知道?我們所做的只是在記憶體中搬移一些位元組。我們沒有任何人類友好的方式來查看我們建立的區塊內部的實際內容。
為了修正這個問題,我們將建立一個反組譯器。一個組譯器是一個老式的程式,它會讀取一個包含人類可讀的 CPU 指令助記名稱(例如「ADD」和「MULT」)的檔案,並將它們轉換為對應的二進制機器碼。而反組譯器則朝相反的方向運作—給定一塊機器碼,它會吐出指令的文字列表。
我們將實作類似的工具。給定一個區塊,它會印出其中所有的指令。Lox 的使用者不會用到這個,但我們 Lox 的維護者肯定會受益,因為它可以讓我們了解直譯器內部的程式碼表示方式。
在 main() 中,在建立區塊後,我們將其傳遞給反組譯器。
initChunk(&chunk); writeChunk(&chunk, OP_RETURN);
現在我們有一個用於建立位元組碼區塊的小模組。讓我們試著手動建立一個範例區塊。
disassembleChunk(&chunk, "test chunk");
freeChunk(&chunk);
再次地,我們快速建立另一個模組。
#include "chunk.h"
#include "debug.h"
int main(int argc, const char* argv[]) {
這是標頭檔。
建立新檔案
#ifndef clox_debug_h #define clox_debug_h #include "chunk.h" void disassembleChunk(Chunk* chunk, const char* name); int disassembleInstruction(Chunk* chunk, int offset); #endif
在 main() 中,我們呼叫 disassembleChunk() 來反組譯整個區塊中的所有指令。它是根據另一個函式實作的,該函式只反組譯單一指令。它在這裡的標頭檔中出現,是因為我們將在後面的章節中從虛擬機器呼叫它。
這是實作檔案的開頭。
建立新檔案
#include <stdio.h> #include "debug.h" void disassembleChunk(Chunk* chunk, const char* name) { printf("== %s ==\n", name); for (int offset = 0; offset < chunk->count;) { offset = disassembleInstruction(chunk, offset); } }
為了反組譯一個區塊,我們印出一個小標頭(以便我們知道我們正在查看哪個區塊),然後處理位元組碼,反組譯每個指令。我們迭代程式碼的方式有點奇怪。我們不是在迴圈中遞增 offset,而是讓 disassembleInstruction() 為我們做。當我們呼叫該函式時,在反組譯給定偏移量的指令後,它會傳回下一個指令的偏移量。這是因為,正如我們稍後將看到的,指令可能有不同的大小。
「debug」模組的核心是這個函式。
在 disassembleChunk() 後面新增。
int disassembleInstruction(Chunk* chunk, int offset) { printf("%04d ", offset); uint8_t instruction = chunk->code[offset]; switch (instruction) { case OP_RETURN: return simpleInstruction("OP_RETURN", offset); default: printf("Unknown opcode %d\n", instruction); return offset + 1; } }
首先,它會印出給定指令的位元組偏移量—這會告訴我們這個指令在區塊中的哪個位置。當我們開始進行控制流程並在位元組碼中跳轉時,這將是一個有用的標記。
接下來,它會從給定偏移量的位元組碼中讀取單一位元組。這是我們的運算碼。我們根據這個運算碼進行切換。對於每種指令,我們會分派到一個小的工具函式來顯示它。如果給定的位元組看起來根本不像指令—我們的編譯器中存在錯誤—我們也會印出它。對於我們擁有的單一指令 OP_RETURN,顯示函式為:
在 disassembleChunk() 後面新增。
static int simpleInstruction(const char* name, int offset) { printf("%s\n", name); return offset + 1; }
return 指令沒有太多內容,所以它所做的只是印出運算碼的名稱,然後傳回這個指令之後的下一個位元組偏移量。其他指令會有更多內容。
如果我們現在執行我們剛起步的直譯器,它實際上會印出一些東西。
== test chunk == 0000 OP_RETURN
它成功了!這有點像是我們程式碼表示的「Hello, world!」。我們可以建立一個區塊,向其中寫入一個指令,然後將該指令擷取出來。我們對二進制位元組碼的編碼和解碼正在運作。
14 . 5常數
既然我們已經有一個基本的區塊結構在運作,讓我們開始讓它更有用。我們可以在區塊中儲存程式碼,但資料呢?直譯器使用的許多值是在執行期間作為運算的結果而建立的。
1 + 2;
值 3 在這裡的程式碼中沒有任何地方出現。但是,文字 1 和 2 確實出現了。為了將該陳述式編譯為位元組碼,我們需要某種表示「產生常數」的指令,並且這些文字值需要儲存在區塊中的某個位置。在 jlox 中,Expr.Literal AST 節點保存了該值。既然我們沒有語法樹,我們現在需要一個不同的解決方案。
14 . 5 . 1表示值
我們不會在本章中執行任何程式碼,但由於常數在我們的直譯器的靜態和動態世界中都佔有一席之地,它們迫使我們開始至少稍微思考一下我們的虛擬機器應該如何表示值。
現在,我們將盡可能從簡單開始—我們將只支援雙精度浮點數。隨著時間的推移,這顯然會擴展,因此我們將建立一個新的模組,以便我們有擴展的空間。
建立新檔案
#ifndef clox_value_h #define clox_value_h #include "common.h" typedef double Value; #endif
這個 typedef 抽象了 Lox 值在 C 中如何具體表示。這樣,我們可以變更該表示,而無需回去修正傳遞值的現有程式碼。
回到在區塊中儲存常數的問題。對於像整數這樣的小型固定大小的值,許多指令集會將該值直接儲存在運算碼之後的程式碼串流中。這些被稱為立即指令,因為該值的位元緊接在運算碼之後。
對於像字串這樣的大型或可變大小的常數,這種方式效果不佳。在機器碼的原生編譯器中,那些較大的常數會儲存在二進制可執行檔案中的單獨「常數資料」區域中。然後,載入常數的指令會有一個位址或偏移量,指向該值儲存在該區段中的位置。
大多數虛擬機器都執行類似的操作。例如,Java 虛擬機器會將常數池與每個編譯的類別相關聯。對我來說,這對 clox 來說已經足夠好了。每個區塊都會帶有程式中以文字形式出現的值的列表。為了保持簡單,我們會將所有常數都放在那裡,甚至是簡單的整數。
14 . 5 . 2值陣列
常數池是一個值陣列。載入常數的指令會透過該陣列中的索引來查詢值。與我們的位元組碼陣列一樣,編譯器事先不知道陣列需要多大。因此,我們再次需要一個動態陣列。由於 C 沒有泛型資料結構,我們將編寫另一個動態陣列資料結構,這次用於 Value。
typedef double Value;
typedef struct { int capacity; int count; Value* values; } ValueArray;
#endif
與 Chunk 中的位元組碼陣列一樣,這個結構會包裝一個指向陣列的指標,以及其配置的容量和正在使用的元素數量。我們也需要三個相同的函式來處理值陣列。
} ValueArray;
在 struct ValueArray 後面新增。
void initValueArray(ValueArray* array); void writeValueArray(ValueArray* array, Value value); void freeValueArray(ValueArray* array);
#endif
實作可能會讓您有似曾相識的感覺。首先,建立一個新的。
建立新檔案
#include <stdio.h> #include "memory.h" #include "value.h" void initValueArray(ValueArray* array) { array->values = NULL; array->capacity = 0; array->count = 0; }
一旦我們有了初始化的陣列,我們就可以開始向其中新增值。
在 initValueArray() 後面新增。
void writeValueArray(ValueArray* array, Value value) { if (array->capacity < array->count + 1) { int oldCapacity = array->capacity; array->capacity = GROW_CAPACITY(oldCapacity); array->values = GROW_ARRAY(Value, array->values, oldCapacity, array->capacity); } array->values[array->count] = value; array->count++; }
我們之前編寫的記憶體管理巨集確實讓我們可以重複使用程式碼陣列中的一些邏輯,所以這還不算太糟。最後,釋放陣列使用的所有記憶體。
在 writeValueArray() 後面新增。
void freeValueArray(ValueArray* array) { FREE_ARRAY(Value, array->values, array->capacity); initValueArray(array); }
既然我們有了可成長的值陣列,我們可以將一個陣列新增到 Chunk 中來儲存區塊的常數。
uint8_t* code;
在 struct Chunk 中
ValueArray constants;
} Chunk;
別忘了 include。
#include "common.h"
#include "value.h"
typedef enum {
啊,C,以及它石器時代的模組化故事。我們說到哪了?對了。當我們初始化一個新區塊時,我們也會初始化它的常數列表。
chunk->code = NULL;
在 initChunk() 中。
initValueArray(&chunk->constants);
}
同樣地,當我們釋放區塊時,我們也會釋放常數。
FREE_ARRAY(uint8_t, chunk->code, chunk->capacity);
在 freeChunk() 中。
freeValueArray(&chunk->constants);
initChunk(chunk);
接下來,我們定義一個方便的方法來將一個新常數新增到區塊中。我們尚未編寫的編譯器可以直接寫入 Chunk 內部的常數陣列—C 沒有私有欄位之類的任何東西—但新增一個明確的函式會比較好一點。
void writeChunk(Chunk* chunk, uint8_t byte);
在 writeChunk() 後面新增。
int addConstant(Chunk* chunk, Value value);
#endif
然後我們實作它。
在 writeChunk() 後面新增。
int addConstant(Chunk* chunk, Value value) { writeValueArray(&chunk->constants, value); return chunk->constants.count - 1; }
在我們新增常數之後,我們會傳回附加常數的索引,以便我們稍後可以找到相同的常數。
14 . 5 . 3常數指令
我們可以在區塊中儲存常數,但我們也需要執行它們。在像這樣的程式碼中:
print 1; print 2;
編譯的區塊不僅需要包含值 1 和 2,還需要知道何時產生它們,以便它們以正確的順序印出。因此,我們需要一個產生特定常數的指令。
typedef enum {
在 enum OpCode 中。
OP_CONSTANT,
OP_RETURN,
當虛擬機器執行常數指令時,它會「載入」常數以供使用。這個新指令比 OP_RETURN 稍微複雜一點。在上面的範例中,我們載入了兩個不同的常數。單一裸運算碼不足以知道要載入哪個常數。
為了處理這種情況,我們的位元組碼—就像其他大多數位元組碼一樣—允許指令具有運算元。這些會儲存為指令串流中運算碼之後的立即二進制資料,並讓我們可以參數化指令的行為。
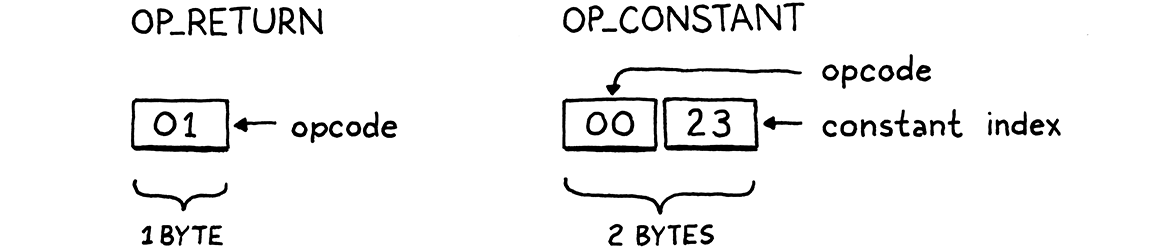
每個運算碼都會決定它有多少個運算元位元組以及它們的含義。例如,像「return」這樣的簡單操作可能沒有運算元,而「載入局部變數」的指令則需要一個運算元來識別要載入哪個變數。每次我們向 clox 新增一個運算碼時,我們都會指定其運算元的樣子—它的指令格式。
在這種情況下,OP_CONSTANT 採用單一位元組運算元,該運算元指定要從區塊的常數陣列中載入哪個常數。由於我們還沒有編譯器,我們會在測試區塊中「手動編譯」一個指令。
initChunk(&chunk);
現在我們有一個用於建立位元組碼區塊的小模組。讓我們試著手動建立一個範例區塊。
int constant = addConstant(&chunk, 1.2); writeChunk(&chunk, OP_CONSTANT); writeChunk(&chunk, constant);
writeChunk(&chunk, OP_RETURN);
我們將常數值本身新增到區塊的常數池中。這會傳回常數在陣列中的索引。然後我們寫入常數指令,從其運算碼開始。之後,我們寫入單一位元組的常數索引運算元。請注意,writeChunk() 可以寫入運算碼或運算元。就該函式而言,它們都是原始位元組。
如果我們現在嘗試執行這個,反組譯器會對我們大喊大叫,因為它不知道如何解碼這個新指令。讓我們修正這個問題。
switch (instruction) {
在 disassembleInstruction() 中
case OP_CONSTANT: return constantInstruction("OP_CONSTANT", chunk, offset);
case OP_RETURN:
這個指令有不同的指令格式,因此我們寫一個新的輔助函數來反組譯它。
在 disassembleChunk() 後面新增。
static int constantInstruction(const char* name, Chunk* chunk, int offset) { uint8_t constant = chunk->code[offset + 1]; printf("%-16s %4d '", name, constant); printValue(chunk->constants.values[constant]); printf("'\n"); }
這裡還有更多事情要做。如同 OP_RETURN 一樣,我們印出操作碼的名稱。然後,我們從程式碼區塊的後續位元組中取出常數索引。我們印出該索引,但對我們人類讀者來說並不是非常有用。因此,我們也查詢實際的常數值—畢竟常數在編譯時是已知的—並顯示該值本身。
這需要某種方式來印出一個 clox Value。該函數將位於「value」模組中,因此我們將其包含進來。
#include "debug.h"
#include "value.h"
void disassembleChunk(Chunk* chunk, const char* name) {
在該標頭檔中,我們宣告
void freeValueArray(ValueArray* array);
在 freeValueArray() 之後新增
void printValue(Value value);
#endif
這是一個實作
在 freeValueArray() 之後新增
void printValue(Value value) { printf("%g", value); }
太棒了,對吧?如你所想,一旦我們將動態型別新增到 Lox 中並擁有不同型別的值時,這將變得更加複雜。
回到 constantInstruction(),剩下的唯一部分是回傳值。
printf("'\n");
在 constantInstruction() 中
return offset + 2;
}
請記住,disassembleInstruction() 也會回傳一個數字,告知呼叫者 *下一個* 指令的起始偏移量。OP_RETURN 只有一個位元組,而 OP_CONSTANT 則是兩個—一個用於操作碼,另一個用於運算元。
14 . 6行號資訊
程式碼區塊包含執行時期從使用者原始碼中需要的所有資訊。想到我們可以將在 jlox 中建立的所有不同 AST 類別簡化為一個位元組陣列和一個常數陣列,這真是令人難以置信。我們只缺少一塊資料。我們需要它,即使使用者希望永遠看不到它。
當執行時期錯誤發生時,我們向使用者顯示錯誤原始碼的行號。在 jlox 中,這些數字存在於 token 中,而我們反過來將其儲存在 AST 節點中。現在,由於我們已經拋棄語法樹而改用位元碼,因此我們需要一個不同的 clox 解決方案。給定任何位元碼指令,我們需要能夠確定它是從使用者原始碼的哪一行編譯而來的。
有很多巧妙的方法可以對此進行編碼。我採用了我能想到的絕對最簡單的方法,即使它在記憶體使用上非常沒有效率。在程式碼區塊中,我們儲存一個與位元碼平行的獨立整數陣列。陣列中的每個數字都是位元碼中對應位元組的行號。當執行時期錯誤發生時,我們會查詢程式碼陣列中與目前指令的偏移量相同索引的行號。
為了實作此功能,我們將另一個陣列新增到 Chunk 中。
uint8_t* code;
在 struct Chunk 中
int* lines;
ValueArray constants;
由於它與位元碼陣列完全平行,因此我們不需要單獨的計數或容量。每次我們接觸程式碼陣列時,我們都會對行號陣列進行相應的變更,從初始化開始。
chunk->code = NULL;
在 initChunk() 中。
chunk->lines = NULL;
initValueArray(&chunk->constants);
同樣地,釋放記憶體
FREE_ARRAY(uint8_t, chunk->code, chunk->capacity);
在 freeChunk() 中。
FREE_ARRAY(int, chunk->lines, chunk->capacity);
freeValueArray(&chunk->constants);
當我們將程式碼的位元組寫入程式碼區塊時,我們需要知道它來自哪個原始碼行,因此我們在 writeChunk() 的宣告中新增一個額外參數。
void freeChunk(Chunk* chunk);
函式 writeChunk()
取代 1 行
void writeChunk(Chunk* chunk, uint8_t byte, int line);
int addConstant(Chunk* chunk, Value value);
在實作中
函式 writeChunk()
取代 1 行
void writeChunk(Chunk* chunk, uint8_t byte, int line) {
if (chunk->capacity < chunk->count + 1) {
當我們配置或擴展程式碼陣列時,我們也會對行資訊執行相同的操作。
chunk->code = GROW_ARRAY(uint8_t, chunk->code,
oldCapacity, chunk->capacity);
在 writeChunk() 中
chunk->lines = GROW_ARRAY(int, chunk->lines, oldCapacity, chunk->capacity);
}
最後,我們將行號儲存在陣列中。
chunk->code[chunk->count] = byte;
在 writeChunk() 中
chunk->lines[chunk->count] = line;
chunk->count++;
14 . 6 . 1反組譯行號資訊
好的,讓我們用我們的小、嗯、手工製作的程式碼區塊來試試看。首先,由於我們在 writeChunk() 中新增了一個新參數,我們需要修正這些呼叫,以傳入一些—在這個時間點是任意的—行號。
int constant = addConstant(&chunk, 1.2);
現在我們有一個用於建立位元組碼區塊的小模組。讓我們試著手動建立一個範例區塊。
取代 4 行
writeChunk(&chunk, OP_CONSTANT, 123); writeChunk(&chunk, constant, 123); writeChunk(&chunk, OP_RETURN, 123);
disassembleChunk(&chunk, "test chunk");
當然,一旦我們有了真正的前端,編譯器將在剖析時追蹤目前的行並傳入它。
現在我們有了每個指令的行資訊,讓我們好好利用它。在我們的反組譯器中,顯示每個指令是從哪個原始碼行編譯而來的會很有幫助。當我們試圖找出某個位元碼區塊應該做什麼時,這提供了一種映射回原始程式碼的方法。在印出指令的偏移量—從程式碼區塊開頭算起的位元組數—之後,我們顯示其原始碼行。
int disassembleInstruction(Chunk* chunk, int offset) {
printf("%04d ", offset);
在 disassembleInstruction() 中
if (offset > 0 && chunk->lines[offset] == chunk->lines[offset - 1]) { printf(" | "); } else { printf("%4d ", chunk->lines[offset]); }
uint8_t instruction = chunk->code[offset];
位元碼指令往往非常精細。單行原始碼通常會編譯成一連串的指令。為了使這種情況在視覺上更清晰,我們為任何與前一個指令來自同一原始碼行的指令顯示一個 |。我們手寫的程式碼區塊的結果輸出如下所示
== test chunk == 0000 123 OP_CONSTANT 0 '1.2' 0002 | OP_RETURN
我們有一個三位元組的程式碼區塊。前兩個位元組是一個常數指令,它從程式碼區塊的常數池載入 1.2。第一個位元組是 OP_CONSTANT 操作碼,第二個是常數池中的索引。第三個位元組(偏移量 2)是一個單位元組回傳指令。
在剩下的章節中,我們將用更多種類的指令來擴充它。但是基本的結構在這裡,而且我們現在擁有在我們的虛擬機中完全表示一個可執行程式碼所需的一切。還記得我們在 jlox 中定義的整個 AST 類別家族嗎?在 clox 中,我們將其簡化為三個陣列:程式碼的位元組、常數值和用於除錯的行資訊。
這種簡化是我們的新解譯器比 jlox 快的一個關鍵原因。你可以將位元碼視為 AST 的一種緊湊序列化,針對解譯器在執行時按所需順序反序列化它的方式進行高度最佳化。在下一章中,我們將看到虛擬機如何做到這一點。
挑戰
-
我們對行資訊的編碼在記憶體使用上非常浪費。鑑於一系列指令通常對應於相同的原始碼行,一個自然的解決方案是類似於行號的行程長度編碼。
設計一種編碼,壓縮同一行上的一系列指令的行資訊。變更
writeChunk()以寫入此壓縮形式,並實作一個getLine()函式,給定指令的索引,確定指令發生的行。提示:
getLine()並不需要特別有效率。由於它僅在執行時期錯誤發生時才會呼叫,因此它在效能至關重要的關鍵路徑之外。 -
由於
OP_CONSTANT的運算元僅使用單一位元組,因此程式碼區塊最多只能包含 256 個不同的常數。這個數字很小,足以讓編寫實際程式碼的人達到這個限制。我們可以使用兩個或多個位元組來儲存運算元,但這會使 *每個* 常數指令佔用更多空間。大多數程式碼區塊不需要那麼多唯一的常數,因此這會浪費空間,並在常見情況下犧牲一些局部性,以支援罕見的情況。為了平衡這兩個相互競爭的目標,許多指令集都具有執行相同操作但具有不同大小運算元的多个指令。讓現有的單位元組
OP_CONSTANT指令保持不變,並定義第二個OP_CONSTANT_LONG指令。它將運算元儲存為 24 位元的數字,這應該足夠了。實作此函式
void writeConstant(Chunk* chunk, Value value, int line) { // Implement me... }
它將
value新增到chunk的常數陣列,然後寫入適當的指令以載入常數。也新增對OP_CONSTANT_LONG指令的反組譯器支援。定義兩個指令似乎是兩全其美的辦法。如果有任何犧牲,它會強加給我們什麼?
-
我們的
reallocate()函式依賴 C 標準程式庫進行動態記憶體配置和釋放。malloc()和free()並不是魔法。找到它們的幾個開源實作並解釋它們的工作原理。它們如何追蹤哪些位元組已配置,哪些位元組是空閒的?配置記憶體區塊需要什麼?釋放它?它們如何使其有效率?它們如何處理碎片?硬派模式: 在不呼叫
realloc()、malloc()或free()的情況下實作reallocate()。您可以在解譯器執行開始時呼叫malloc()*一次*,以配置一個大的記憶體區塊,您的reallocate()函式可以存取該區塊。它從那個單一區域中分配記憶體區塊,你自己的個人堆積。你的工作是定義它如何做到這一點。
設計注意事項:測試你的語言
我們已經快要看完這本書的一半了,有一件事我們還沒有談到,那就是 *測試* 你的語言實作。這並不是因為測試不重要。我再怎麼強調為你的語言提供一個良好、全面的測試套件有多重要,都無法說盡。
在寫這本書的一個字之前,我為 Lox 寫了一個Lox 測試套件(你很歡迎在自己的 Lox 實作中使用它)。這些測試發現了我的實作中的無數錯誤。
測試在所有軟體中都很重要,但它們對於程式語言來說更為重要,至少有以下幾個原因
-
使用者期望他們的程式語言非常可靠。 我們已經非常習慣成熟、穩定的編譯器和解譯器,以至於「這是你的程式碼,不是編譯器的問題」已經成為軟體文化中根深蒂固的一部分。如果你的語言實作中存在錯誤,使用者將會經歷完整的五個階段的悲傷,然後才能弄清楚發生了什麼事,而你不想讓他們經歷這一切。
-
語言實作是一個深度互連的軟體。 有些程式碼庫很廣且淺。如果你的文字編輯器中的檔案載入程式碼壞了,它—希望如此!—不會導致螢幕上的文字渲染失敗。語言實作更窄更深,特別是處理語言實際語意的解譯器核心。這使得微妙的錯誤很容易由於系統各部分之間的奇怪互動而潛入。這需要良好的測試才能將它們沖刷出來。
-
語言實作的輸入在設計上是組合的。 使用者可以編寫無限多個可能的程式,而你的實作需要正確執行所有這些程式。你顯然無法徹底測試它,但你需要努力涵蓋盡可能多的輸入空間。
-
語言實作通常很複雜、不斷變化且充滿最佳化。 這會導致複雜的程式碼,其中有很多黑暗的角落可以隱藏錯誤。
這一切都表示你需要大量的測試。但是,什麼樣的測試呢?我見過的專案大多著重於端對端的「語言測試」。每個測試都是一個用該語言編寫的程式,以及預期產生的輸出或錯誤。然後,你會擁有一個測試執行器,它會將測試程式送入你的語言實作中,並驗證它是否執行了它應該做的事情。用該語言本身來編寫測試有幾個不錯的優點。
-
測試不會與實作的任何特定 API 或內部架構決策耦合。這讓你可以在不需要更新大量測試的情況下,重新組織或重寫你的直譯器或編譯器的部分。
-
你可以將相同的測試用於語言的多個實作。
-
測試通常可以簡潔、易於閱讀和維護,因為它們只是你的語言中的腳本。
不過,這並非一切都美好。
-
端對端測試可以幫助你確定是否有錯誤,但無法確定錯誤在哪裡。找出實作中錯誤的程式碼可能更困難,因為測試只會告訴你沒有出現正確的輸出。
-
製作一個能夠觸發實作中某些隱晦角落的有效程式,可能是一件苦差事。對於高度最佳化的編譯器來說尤其如此,你可能需要編寫複雜的程式碼,以確保你最終進入可能隱藏錯誤的正確最佳化路徑。
-
啟動直譯器、解析、編譯和執行每個測試腳本的開銷可能很高。有了大量的測試套件—你確實想要,記得嗎—這可能意味著花費大量的時間等待測試完成執行。
我可以繼續說下去,但我不希望這變成一場佈道。而且,我也不假裝是如何測試語言的專家。我只是希望你內化測試你的語言是多麼重要。說真的。測試你的語言。你會因此感謝我的。