最佳化
傍晚是一天中最美好的時光。您完成了您一天的工作。現在您可以放鬆並享受它。
石黑一雄,《長日將盡》
如果我仍然住在新奧爾良,我會將這一章稱為lagniappe,給客戶的免費額外贈品。您已經有一整本書和一個完整的虛擬機器了,但我希望您在 clox 上進行更多有趣的駭客攻擊。這次,我們追求的是純粹的效能。我們將對我們的虛擬機器應用兩種非常不同的最佳化。在這個過程中,您將了解如何測量和提高語言實作(或任何程式)的效能。
30 . 1測量效能
最佳化是指對運作中的應用程式進行效能改進。最佳化的程式會執行相同的事情,只是它會使用較少的資源來執行。我們在進行最佳化時通常會想到的資源是執行速度,但減少記憶體使用量、啟動時間、持久儲存大小或網路頻寬也很重要。所有實體資源都有一定的成本,即使成本主要是在浪費人類時間上,最佳化工作通常也會得到回報。
在電腦發展的早期,一位熟練的程式設計師可以將整個硬體架構和編譯器管道記在腦海中,並且僅僅透過深入思考就能了解程式的效能。那段日子早已過去,微碼、快取線、分支預測、深度編譯器管道和龐大的指令集將其與現在分隔開來。我們喜歡假裝 C 是一種「低階」語言,但是
printf("Hello, world!");
和螢幕上顯示的問候語之間,技術堆疊現在非常高。
今天的最佳化是一門實證科學。我們的程式就像一隻短跑穿過硬體障礙賽的邊境牧羊犬。如果我們希望她更快地到達終點,我們不能只是坐下來思考犬類生理學,直到靈光一閃。相反,我們需要觀察她的表現,看看她在哪裡絆倒,然後找到更快的路徑讓她通過。
就像敏捷訓練是針對特定一隻狗和一個障礙賽道一樣,我們不能假設我們的虛擬機器最佳化會使所有 Lox 程式在所有硬體上都執行得更快。不同的 Lox 程式會強調虛擬機器的不同區域,而不同的架構有其自身的優點和缺點。
30 . 1 . 1基準測試
當我們新增新功能時,我們透過編寫測試來驗證正確性,也就是使用某個功能並驗證虛擬機器行為的 Lox 程式。測試可以確定語義並確保我們在新增新功能時不會破壞現有的功能。在效能方面,我們也有類似的需求
-
我們要如何驗證最佳化確實提高了效能,以及提高了多少?
-
我們要如何確保其他不相關的變更不會使效能倒退?
我們為了實現這些目標而編寫的 Lox 程式稱為基準測試。這些是精心設計的程式,可以強調語言實作的某些部分。它們測量的不是程式做什麼,而是執行它需要多久。
透過測量變更前後的基準測試效能,您可以了解您的變更所產生的影響。當您完成最佳化時,所有測試的行為應該與之前完全相同,但希望基準測試能執行得更快。
一旦您擁有一整套基準測試,您不僅可以測量最佳化是否改變了效能,還可以測量它在哪些類型的程式碼上改變了效能。您通常會發現某些基準測試變快了,而其他基準測試變慢了。然後,您必須針對您的語言實作要最佳化哪些類型的程式碼做出艱難的決定。
您選擇編寫的基準測試套件是該決策的關鍵部分。就像您的測試會編碼您對正確行為的選擇一樣,您的基準測試體現了您在效能方面的優先順序。它們將指導您實作哪些最佳化,因此請仔細選擇您的基準測試,並且不要忘記定期反思它們是否有助於您實現更大的目標。
基準測試是一門精深的藝術。就像測試一樣,您需要平衡避免過度擬合您的實作,同時確保基準測試確實會觸發您關心的程式碼路徑。當您測量效能時,您需要補償由 CPU 節流、快取和其他奇怪的硬體和作業系統怪癖引起的差異。我不會在這裡給您長篇大論,但請將基準測試視為一種透過練習可以改進的技能。
30 . 1 . 2效能分析
好的,所以您現在有一些基準測試了。您想要讓它們執行得更快。現在該怎麼辦?首先,讓我們假設您已經完成了所有顯而易見、容易的工作。您正在使用正確的演算法和資料結構,或者至少您沒有使用錯誤得離譜的演算法和資料結構。我認為使用雜湊表而不是在巨大的未排序陣列中進行線性搜尋並不是「最佳化」,而是「良好的軟體工程」。
由於硬體太複雜,無法從第一原理推論出我們程式的效能,因此我們必須進入實地。這表示進行效能分析。如果您從未使用過效能分析器,它是一個執行您程式並追蹤程式碼執行時硬體資源使用的工具。簡單的工具會顯示您的程式中每個函式花費的時間。複雜的工具會記錄資料快取未命中、指令快取未命中、分支預測錯誤、記憶體配置以及各種其他指標。
市面上有許多適用於各種作業系統和語言的效能分析器。在您程式設計的任何平台上,都值得熟悉一個不錯的效能分析器。您不需要成為大師。我從向效能分析器發送程式後的幾分鐘內,就學到了如果自己透過試誤法可能需要幾天才能發現的事情。效能分析器是很棒、神奇的工具。
30 . 2更快的雜湊表探測
別再誇誇其談了,讓我們讓效能圖表開始上升。事實證明,我們將要進行的第一個最佳化,是對我們的虛擬機器進行最微小的變更。
當我第一次讓 clox 所基於的位元組碼虛擬機器運作時,我做了任何自重的虛擬機器駭客都會做的事。我拼湊了幾個基準測試,啟動了一個效能分析器,然後透過我的直譯器執行這些腳本。在像 Lox 這樣的動態類型語言中,大部分使用者程式碼都是欄位存取和方法呼叫,因此我的基準測試之一看起來像這樣
class Zoo { init() { this.aardvark = 1; this.baboon = 1; this.cat = 1; this.donkey = 1; this.elephant = 1; this.fox = 1; } ant() { return this.aardvark; } banana() { return this.baboon; } tuna() { return this.cat; } hay() { return this.donkey; } grass() { return this.elephant; } mouse() { return this.fox; } } var zoo = Zoo(); var sum = 0; var start = clock(); while (sum < 100000000) { sum = sum + zoo.ant() + zoo.banana() + zoo.tuna() + zoo.hay() + zoo.grass() + zoo.mouse(); } print clock() - start; print sum;
如果您以前從未見過基準測試,這可能看起來很荒謬。這裡到底發生了什麼?程式本身並不打算做任何有用的事情。它所做的是呼叫一堆方法並存取一堆欄位,因為這些是我們感興趣的語言部分。欄位和方法存在於雜湊表中,因此它會仔細地在這些表中填入至少一些有趣的鍵。所有這些都包裝在一個大迴圈中,以確保我們的效能分析器有足夠的執行時間來深入研究並查看週期發生在何處。
在我告訴您我的效能分析器向我顯示了什麼之前,花一點時間做幾個猜測。您認為虛擬機器在 clox 程式碼庫的哪個位置花費了最多的時間?您是否懷疑我們在之前的章節中編寫的任何程式碼特別慢?
這是我發現的:自然地,包含時間最多的函式是 run()。(包含時間是指在某個函式和它呼叫的所有其他函式中花費的總時間,也就是您進入函式和它返回之間的總時間。)由於 run() 是主要的位元組碼執行迴圈,因此它驅動所有事物。
在 run() 內部,在位元組碼 switch 中的各種情況下,對於像 OP_POP、OP_RETURN 和 OP_ADD 這樣的常見指令,都有零星的時間片段。大型的指令是 OP_GET_GLOBAL,佔執行時間的 17%,OP_GET_PROPERTY 佔 12%,OP_INVOKE 則佔總執行時間的 42%。
所以我們有三個熱點需要最佳化?實際上,並不是這樣。因為事實證明,這三個指令幾乎將他們所有的時間都花在呼叫同一個函式 tableGet() 中。該函式佔據了總執行時間的 72%(同樣是包含時間)。現在,在動態類型語言中,我們期望在雜湊表中花費相當多的時間來查找東西,這算是動態的代價。但是,儘管如此,哇。
30 . 2 . 1慢速鍵包裝
如果你看看 tableGet(),你會發現它主要是一個對 findEntry() 的呼叫的包裝函式,而實際的雜湊表查找發生在 findEntry() 中。為了喚起你的記憶,這裡有完整的程式碼:
static Entry* findEntry(Entry* entries, int capacity, ObjString* key) { uint32_t index = key->hash % capacity; Entry* tombstone = NULL; for (;;) { Entry* entry = &entries[index]; if (entry->key == NULL) { if (IS_NIL(entry->value)) { // Empty entry. return tombstone != NULL ? tombstone : entry; } else { // We found a tombstone. if (tombstone == NULL) tombstone = entry; } } else if (entry->key == key) { // We found the key. return entry; } index = (index + 1) % capacity; } }
當執行先前的基準測試時—至少在我的機器上是這樣—VM 花了總執行時間的 70% 在這個函數的一行上。猜猜是哪一行?猜不到嗎?是這一行:
uint32_t index = key->hash % capacity;
指標解引用不是問題。問題是小小的 %。事實證明,模數運算符真的很慢。比其他算術運算符慢得多。我們可以做得更好嗎?
在一般情況下,很難在使用者程式碼中重新實現基本算術運算符,使其速度比 CPU 本身能做到的更快。畢竟,我們的 C 程式碼最終會編譯成 CPU 自己的算術運算。如果我們可以使用任何技巧來加快速度,晶片早就已經在使用它們了。
然而,我們可以利用我們比 CPU 更了解我們的問題這個事實。我們在這裡使用模數運算,將金鑰字串的雜湊碼包裝到表格的條目陣列的範圍內。該陣列一開始有八個元素,並且每次都會以二為因數增長。我們知道—而 CPU 和 C 編譯器不知道—我們的表格大小總是 2 的冪。
因為我們是聰明的位元操作者,我們知道一種更快的方法來計算一個數字除以 2 的冪的餘數:位元遮罩。假設我們要計算 229 除以 64 的餘數。答案是 37,這在十進制中不是特別明顯,但當你以二進制檢視這些數字時會更清楚:
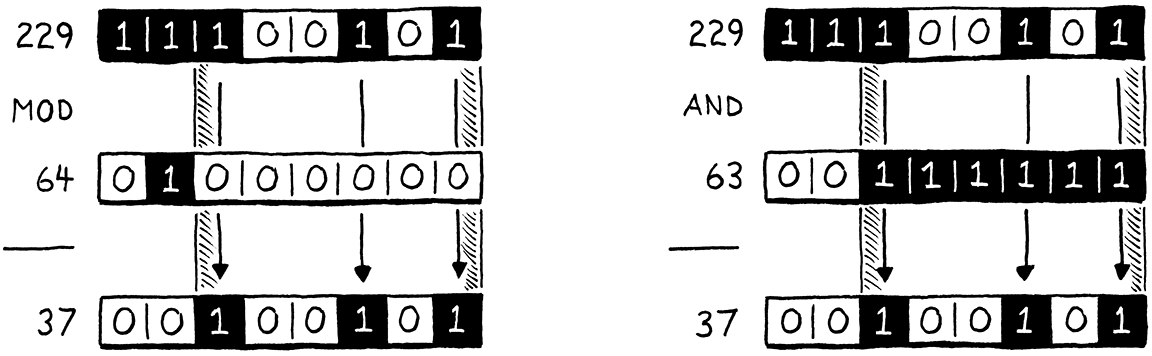
在插圖的左側,請注意結果 (37) 如何僅僅是被除數 (229) 去掉最高的兩個位元?這兩個最高的位元是位於除數單個 1 位元或位於其左側的位元。
在右側,我們通過將 229 與 63 進行位元 AND 運算,得到相同的結果,而 63 比我們原始的 2 的冪除數少 1。從 2 的冪減 1 會得到一系列 1 位元。這正是我們需要用來去除最左邊兩個位元的遮罩。
換句話說,你可以通過簡單地將一個數字與該 2 的冪減 1 進行 AND 運算,來計算該數字除以任何 2 的冪的餘數。我不是數學家,不足以向你證明這樣做有效,但如果你仔細思考,應該會覺得有道理。我們可以用一個非常快速的遞減和位元 AND 運算符來代替那個緩慢的模數運算符。我們只需將有問題的程式碼行更改為此:
static Entry* findEntry(Entry* entries, int capacity,
ObjString* key) {
在 findEntry() 中
替換 1 行
uint32_t index = key->hash & (capacity - 1);
Entry* tombstone = NULL;
CPU 喜歡位元運算符,因此很難改進這一點。
我們的線性探測搜尋可能需要在陣列的末尾環繞,因此 findEntry() 中還有另一個模數運算需要更新。
// We found the key.
return entry;
}
在 findEntry() 中
替換 1 行
index = (index + 1) & (capacity - 1);
}
此行未出現在效能分析器中,因為大多數搜尋不會環繞。
findEntry() 函數有一個姊妹函數 tableFindString(),它會為字串駐留執行雜湊表查找。我們也可以在那裡應用相同的優化。此函數僅在駐留字串時呼叫,而我們的基準測試並未對此進行大量強調。但是,建立大量字串的 Lox 程式可能會明顯受益於此變更。
if (table->count == 0) return NULL;
在 tableFindString() 中
替換 1 行
uint32_t index = hash & (table->capacity - 1);
for (;;) {
Entry* entry = &table->entries[index];
以及在線性探測環繞時。
return entry->key;
}
在 tableFindString() 中
替換 1 行
index = (index + 1) & (table->capacity - 1);
}
讓我們看看我們的修復是否值得。我調整了那個動物學基準測試,以計算它在十秒鐘內可以執行多少個 10,000 次呼叫的批次。更多批次等於更快的效能。在我的機器上使用未優化的程式碼,基準測試通過了 3,192 個批次。經過此優化後,這個數字躍升至 6,249。
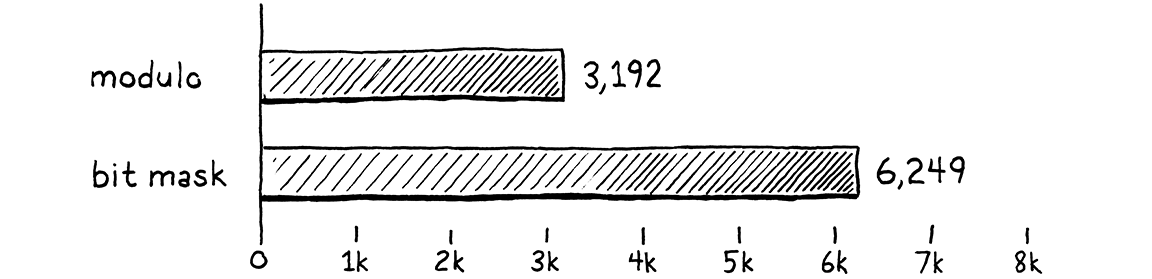
在相同的時間內,幾乎是兩倍的工作量。我們使 VM 快了兩倍(通常的警告:在這個基準測試中)。當涉及優化時,這是一個巨大的勝利。通常,如果你能在這裡或那裡獲得幾個百分點,你會感覺很好。由於方法、欄位和全域變數在 Lox 程式中如此普遍,這種微小的優化可以全面提高效能。幾乎每個 Lox 程式都受益。
現在,本節的重點不是模數運算符非常邪惡,你應該從你編寫的每個程式中消除它。也不是說微優化是一項至關重要的工程技能。效能問題很少有如此狹隘、有效的解決方案。我們很幸運。
重點是,在我們的效能分析器告訴我們之前,我們並不知道模數運算符是一個效能消耗。如果我們盲目地在 VM 的程式碼庫中閒逛,猜測熱點,我們可能不會注意到它。我希望你從中學到的是,擁有一個效能分析器在你的工具箱中是多麼重要。
為了加強這一點,讓我們繼續在我們現在已優化的 VM 中執行原始基準測試,看看效能分析器顯示了什麼。在我的機器上,tableGet() 仍然佔據了相當大的執行時間。對於動態類型語言來說,這是預料之中的。但是它已經從總執行時間的 72% 下降到 35%。這更符合我們期望看到的結果,並且表明我們的優化不僅使程式更快,而且使其以我們預期的方式更快。效能分析器在驗證解決方案方面與發現問題方面一樣有用。
30 . 3NaN Boxing
下一個優化具有非常不同的感覺。值得慶幸的是,儘管名稱很奇怪,但它不涉及毆打你的祖母。它不同,但並非如此大的不同。通過我們之前的優化,效能分析器告訴我們問題所在,而我們只需要發揮一些創造力來提出解決方案。
這種優化更微妙,其效能影響更分散在虛擬機器中。效能分析器不會幫助我們提出這個。相反,它是被某人深入思考機器架構的最低層次時發明的。
正如標題所說,這種優化稱為 NaN boxing 或有時稱為 NaN tagging。我個人喜歡後一個名稱,因為「boxing」往往暗示某種類型的堆積分配表示,但前者似乎是更廣泛使用的術語。這種技術改變了我們在 VM 中表示值的方式。
在 64 位元機器上,我們的 Value 類型佔用 16 個位元組。結構體有兩個欄位,一個類型標籤和一個用於酬載的聯集。聯集中最大的欄位是一個 Obj 指標和一個 double,它們都是 8 個位元組。為了保持聯集欄位與 8 位元組邊界對齊,編譯器也會在標籤後添加填充:

這相當大。如果我們可以縮小它,那麼 VM 可以將更多值打包到相同的記憶體量中。現在大多數電腦都有大量的 RAM,因此直接的記憶體節省不是什麼大問題。但是較小的表示意味著更多 Value 適合快取行中。這意味著更少的快取未命中,這會影響速度。
如果 Value 需要與其最大的酬載大小對齊,並且 Lox 數字或 Obj 指標需要完整的 8 個位元組,我們如何才能變得更小?在像 Lox 這樣的動態類型語言中,每個值不僅需要攜帶其酬載,還需要足夠的額外資訊來在執行時確定值的類型。如果 Lox 數字已經使用了完整的 8 個位元組,我們可以在哪裡偷偷儲存一些額外的位元來告訴執行時「這是一個數字」?
這是動態語言駭客的長期問題之一。它特別讓他們困擾,因為靜態類型語言通常沒有這個問題。每個值的類型在編譯時已知,因此在執行時不需要額外的記憶體來追蹤它。當你的 C 編譯器編譯一個 32 位元的 int 時,結果變數會獲得精確 32 位元的儲存空間。
動態語言使用者討厭輸給靜態陣營,因此他們想出了一些非常聰明的方法,將類型資訊和酬載打包到少量位元中。NaN boxing 就是其中之一。它特別適合像 JavaScript 和 Lua 這樣的語言,在這些語言中,所有數字都是雙精度浮點數。Lox 也處於相同的境地。
30 . 3 . 1什麼是(以及不是)數字?
在開始最佳化之前,我們需要真正了解我們的朋友 CPU 如何表示浮點數。現今幾乎所有的機器都使用相同的方案,編碼在古老的 IEEE 754 規範中,一般人稱之為「IEEE 浮點數算術標準」。
在你的電腦眼中,一個 64 位元、雙精度、IEEE 浮點數看起來像這樣

-
從右邊開始,前 52 位元是小數、尾數或有效數位元。它們以二進制整數的形式表示數字的有效位數。
-
旁邊的 11 位元是指數位元。這些位元告訴你尾數與小數點(實際上是二進制小數點)之間的偏移量。
-
最高的位元是符號位元,表示該數字是正數還是負數。
我知道這有點模糊,但本章並不是要深入探討浮點數的表示方式。如果你想知道指數和尾數如何協同工作,網路上已經有比我能寫出的更好的解釋。
對於我們的目的而言,重要的是該規範劃分了一個特殊的指數案例。當所有指數位元都被設置時,該值就不僅僅表示一個非常大的數字,而是具有不同的含義。這些值是「非數字」(Not a Number),也就是 NaN 值。它們表示諸如無窮大或除以零的結果等概念。
任何指數位元都被設置的雙精度浮點數都是 NaN,無論尾數位元如何。這意味著有非常非常多不同的 NaN 位元模式。IEEE 754 將它們分為兩類。最高尾數位元為 0 的值稱為信號 NaN,而其他則為靜默 NaN。信號 NaN 旨在作為錯誤計算的結果,例如除以零。當產生其中一個值時,晶片可能會檢測到並完全中止程式。如果你嘗試讀取它們,它們可能會自行毀滅。
靜默 NaN 應該是比較安全的使用方式。它們不代表有用的數值,但至少在接觸它們時不應該讓你著火。
每個指數位元都被設置且最高尾數位元也被設置的雙精度浮點數都是靜默 NaN。這留下了 52 個未被使用的位元。我們會避免使用其中一個,以免踩到 Intel 的「QNaN 浮點不定值」,這樣就剩下 51 個位元。剩餘的位元可以是任何值。我們正在談論 2,251,799,813,685,248 個獨特的靜默 NaN 位元模式。
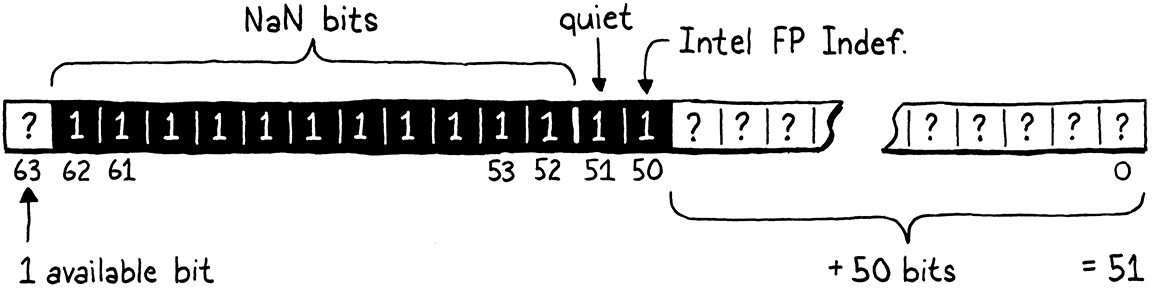
這意味著一個 64 位元的雙精度浮點數有足夠的空間來儲存所有不同的數值浮點數值,並且還有空間可以儲存另外 51 位元的數據,我們可以隨意使用。這有足夠的空間可以預留一些位元模式來表示 Lox 的 nil、true 和 false 值。但是 Obj 指標呢?指標不也需要完整的 64 位元嗎?
幸運的是,我們還有另一招。是的,從技術上講,64 位元架構上的指標是 64 位元。但是,據我所知,沒有任何架構真正使用整個位址空間。相反,現今最廣泛使用的晶片只使用低 48 位元。剩餘的 16 位元則未指定或始終為零。
如果我們有 51 位元,我們可以在其中塞入一個 48 位元的指標,並剩下三個位元。這三個位元剛好足以儲存微小的類型標籤,以區分 nil、布林值和 Obj 指標。
這就是 NaN boxing。在一個 64 位元的雙精度浮點數中,你可以儲存所有不同的浮點數值、指標,或任何其他幾個特殊的哨兵值。記憶體使用量只有目前 Value 結構的一半,同時保留了所有的精確度。
這個表示方式特別棒的地方在於,不需要將數值雙精度浮點數轉換為「封裝」的形式。Lox 數字就是普通的 64 位元雙精度浮點數。我們仍然需要在使用它們之前檢查它們的類型,因為 Lox 是動態類型的,但是我們不需要做任何位元移位或指標間接來從「值」轉換為「數字」。
對於其他值類型,當然會有一個轉換步驟。但是,幸運的是,我們的 VM 將從值到原始類型之間的所有機制都隱藏在一些巨集之後。重寫這些巨集以實現 NaN boxing,其餘的 VM 應該就可以正常工作。
30 . 3 . 2條件式支援
我知道你還沒有完全清楚這個新表示方式的細節。別擔心,當我們進行實作時,它們會逐漸明朗。在我們開始之前,我們要先建立一些編譯時的腳手架。
對於我們之前的最佳化,我們重寫了之前的慢速程式碼,然後就這樣結束了。這次的稍微不同。NaN boxing 依賴於晶片如何表示浮點數和指標的一些非常底層的細節。它可能在您可能遇到的大多數 CPU 上都能正常工作,但您永遠無法完全確定。
如果我們的 VM 僅僅因為其值的表示方式而完全失去對某種架構的支援,那就太糟糕了。為了避免這種情況,我們將同時維護對 Value 的舊標記聯合實作和新的 NaN boxing 形式的支援。我們在編譯時使用這個標誌選擇我們想要的表示方式
#include <stdint.h>
#define NAN_BOXING
#define DEBUG_PRINT_CODE
如果定義了該標誌,則 VM 使用新的形式。否則,它會回復到舊的樣式。關心值表示方式細節的少數程式碼片段—主要是用於封裝和解封 Value 的少數巨集—會根據是否設置此標誌而有所不同。其餘的 VM 可以繼續正常執行。
大部分工作都發生在「value」模組中,我們在其中為新類型添加一個區段。
typedef struct ObjString ObjString;
#ifdef NAN_BOXING typedef uint64_t Value; #else
typedef enum {
啟用 NaN boxing 後,Value 的實際類型是一個扁平的、無符號的 64 位元整數。我們可以使用 double 代替,這會使處理 Lox 數字的巨集更簡單一些。但是所有其他的巨集都需要進行位元運算,而 uint64_t 則是一種更友好的類型。在這個模組之外,VM 的其餘部分並不真正關心哪種方式。
在我們開始重新實作這些巨集之前,我們關閉舊表示方式定義末尾的 #ifdef 的 #else 分支。
#define OBJ_VAL(object) ((Value){VAL_OBJ, {.obj = (Obj*)object}})
#endif
typedef struct {
我們剩下的任務很簡單,就是用 #else 邊已經存在的所有東西的新實作來填補第一個 #ifdef 區段。我們將一次處理一種值類型,從最簡單到最難的。
30 . 3 . 3數字
我們將從數字開始,因為它們在 NaN boxing 下具有最直接的表示形式。要將 C 的 double「轉換」為 NaN boxing 的 clox Value,我們不需要觸碰任何一位元—表示形式完全相同。但是我們確實需要讓我們的 C 編譯器相信這個事實,我們通過將 Value 定義為 uint64_t 而使這變得更加困難。
我們需要讓編譯器將它認為是一組 double 的位元,並將這些相同的位元用作 uint64_t,反之亦然。這稱為類型雙關。C 和 C++ 程式設計師從喇叭褲和 8 軌時代就一直在這樣做,但是語言規範一直猶豫是否要說出哪一種方法是正式認可的。
我知道一種將 double 轉換為 Value 並再轉換回來的辦法,我相信 C 和 C++ 規範都支援這種辦法。不幸的是,它不適合單一的表達式,因此轉換巨集必須呼叫輔助函數。這是第一個巨集
typedef uint64_t Value;
#define NUMBER_VAL(num) numToValue(num)
#else
該巨集將 double 傳遞到此處
#define NUMBER_VAL(num) numToValue(num)
static inline Value numToValue(double num) { Value value; memcpy(&value, &num, sizeof(double)); return value; }
#else
我知道,很奇怪,對吧?將一系列位元組視為具有不同類型而不改變其值的方式是 memcpy()?這看起來非常慢:建立一個本地變數。通過系統呼叫將其位址傳遞給作業系統,以複製幾個位元組。然後返回結果,該結果與輸入的位元組完全相同。值得慶幸的是,由於這是用於類型雙關的受支援慣用方法,因此大多數編譯器都能識別此模式並完全最佳化掉 memcpy()。
「解封裝」Lox 數字是相反的過程。
typedef uint64_t Value;
#define AS_NUMBER(value) valueToNum(value)
#define NUMBER_VAL(num) numToValue(num)
該巨集呼叫此函數
#define NUMBER_VAL(num) numToValue(num)
static inline double valueToNum(Value value) { double num; memcpy(&num, &value, sizeof(Value)); return num; }
static inline Value numToValue(double num) {
它的工作方式完全相同,只是我們交換了類型。同樣,編譯器會消除所有這些。即使對 memcpy() 的呼叫會消失,我們仍然需要向編譯器顯示我們正在呼叫哪個 memcpy(),因此我們還需要一個 include。
#define clox_value_h
#include <string.h>
#include "common.h"
這段程式碼最終做了很多事情,但最終只是為了讓 C 類型檢查器安靜下來。對 Lox 數字執行執行時間類型測試會更有趣。如果我們擁有的只是 double 的位元,我們如何判斷它是 double?現在該進行位元操作了。
typedef uint64_t Value;
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
#define AS_NUMBER(value) valueToNum(value)
我們知道每個不是數字的 Value 都會使用特殊的靜默 NaN 表示形式。並且我們假設我們已正確避免了任何可能通過對數字進行算術運算而實際產生的有意義的 NaN 表示形式。
如果 double 設定了所有 NaN 位元,並且設定了靜默 NaN 位元,並且再多設定一位元以確保安全,我們就可以非常確定它是我們自己預留給其他類型的位元模式之一。為了檢查這一點,我們將除了靜默 NaN 位元集之外的所有位元遮罩掉。如果所有這些位元都被設定,則它必須是某種其他 Lox 類型的 NaN-boxed 值。否則,它實際上是一個數字。
靜默 NaN 位元的集合宣告如下
#ifdef NAN_BOXING
#define QNAN ((uint64_t)0x7ffc000000000000)
typedef uint64_t Value;
如果 C 支援二進位字面值就好了。但如果你進行轉換,你會發現該值與此相同

這正好是所有的指數位元,加上靜默 NaN 位元,再加上一個額外的位元來避開 Intel 的值。
30 . 3 . 4Nil、true 和 false
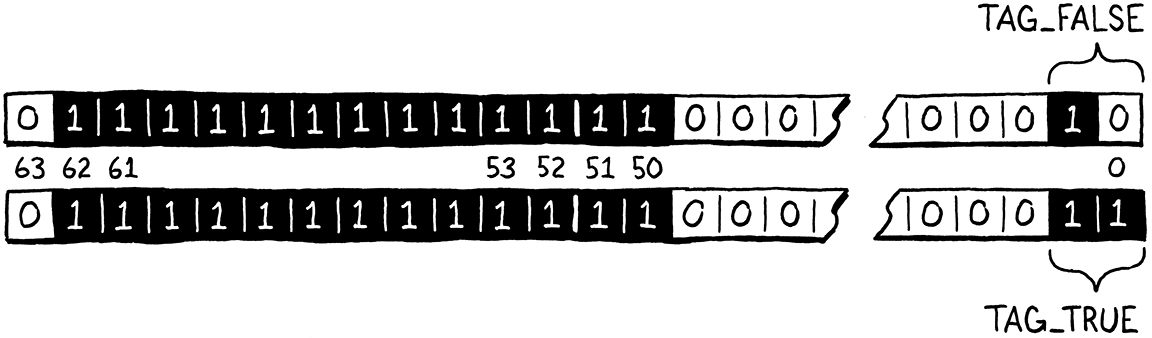
下一個要處理的類型是 nil。這相當簡單,因為只有一個 nil 值,因此我們只需要一個位元模式來表示它。還有另外兩個單例值,即兩個布林值,true 和 false。這需要總共三個獨特的位元模式。
兩個位元給我們四種不同的組合,這已經足夠了。我們將未使用尾數空間的最低兩個位元聲明為「類型標籤」,以確定我們正在查看的是這三個單例值中的哪一個。這三個類型標籤定義如下
#define QNAN ((uint64_t)0x7ffc000000000000)
#define TAG_NIL 1 // 01. #define TAG_FALSE 2 // 10. #define TAG_TRUE 3 // 11.
typedef uint64_t Value;
因此,我們對 nil 的表示是定義靜默 NaN 表示所需的所有位元,以及 nil 類型標籤位元
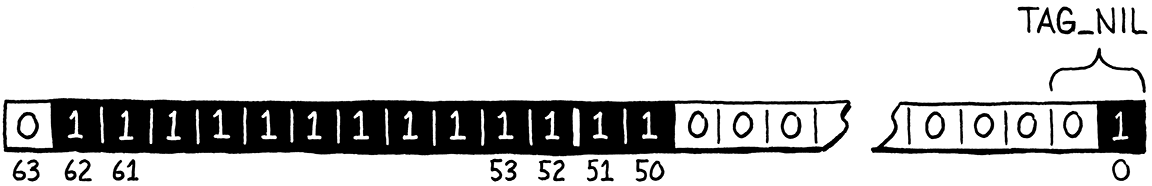
在程式碼中,我們像這樣檢查位元
#define AS_NUMBER(value) valueToNum(value)
#define NIL_VAL ((Value)(uint64_t)(QNAN | TAG_NIL))
#define NUMBER_VAL(num) numToValue(num)
我們只需將靜默 NaN 位元和類型標籤進行位元 OR 運算,然後做一些類型轉換,以告知 C 編譯器我們希望這些位元代表的含義。
由於 nil 只有單一位元表示,我們可以使用 uint64_t 的相等性來判斷 Value 是否為 nil。
typedef uint64_t Value;
#define IS_NIL(value) ((value) == NIL_VAL)
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
你可以猜到我們如何定義 true 和 false 值。
#define AS_NUMBER(value) valueToNum(value)
#define FALSE_VAL ((Value)(uint64_t)(QNAN | TAG_FALSE)) #define TRUE_VAL ((Value)(uint64_t)(QNAN | TAG_TRUE))
#define NIL_VAL ((Value)(uint64_t)(QNAN | TAG_NIL))
位元看起來像這樣
要將 C 的布林值轉換為 Lox 的布林值,我們依賴於這兩個單例值和古老的條件運算符。
#define AS_NUMBER(value) valueToNum(value)
#define BOOL_VAL(b) ((b) ? TRUE_VAL : FALSE_VAL)
#define FALSE_VAL ((Value)(uint64_t)(QNAN | TAG_FALSE))
可能有一種更聰明的位元運算方式來做到這一點,但我的直覺是編譯器可以比我更快地找到一種方式。反向操作比較簡單。
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
#define AS_BOOL(value) ((value) == TRUE_VAL)
#define AS_NUMBER(value) valueToNum(value)
由於我們知道 Lox 中只有兩種布林位元表示—不像 C 中任何非零值都可以被認為是「true」—如果它不是 true,它一定是 false。這個巨集假設你只在已知是 Lox 布林值的 Value 上呼叫它。為了檢查這一點,還有一個巨集。
typedef uint64_t Value;
#define IS_BOOL(value) (((value) | 1) == TRUE_VAL)
#define IS_NIL(value) ((value) == NIL_VAL)
這看起來有點奇怪。一個更明顯的巨集看起來會像這樣
#define IS_BOOL(v) ((v) == TRUE_VAL || (v) == FALSE_VAL)
不幸的是,這並不安全。展開式會提到 v 兩次,這表示如果該表達式有任何副作用,它們將會被執行兩次。我們可以讓巨集呼叫一個獨立的函數,但是,唉,真是麻煩。
取而代之的是,我們將 1 位元 OR 到該值,以合併僅有的兩種有效布林位元模式。這會留下該值可能處於的三種狀態
-
它是
FALSE_VAL,現在已轉換為TRUE_VAL。 -
它是
TRUE_VAL,而| 1沒有任何作用,它仍然是TRUE_VAL。 -
它是其他一些非布林值。
在這種情況下,我們只需將結果與 TRUE_VAL 進行比較,即可查看我們是否處於前兩種狀態或第三種狀態。
30 . 3 . 5物件
最後一個數值類型是最困難的。與單例值不同,我們需要將數十億個不同的指標值裝箱到 NaN 中。這表示我們需要某種標籤來指示這些特定的 NaN 是 Obj 指標,以及儲存位址本身的空間。
我們用於單例值的標籤位元位於我決定儲存指標本身的位置,因此我們不能輕易地在那裡使用不同的 位元 來指示該值是物件參考。但是,還有另一個我們沒有使用的位元。由於我們所有的 NaN 值都不是數字—這在名稱中很清楚—符號位元沒有用於任何用途。我們將使用它作為物件的類型標籤。如果我們的靜默 NaN 之一設定了其符號位元,那麼它就是 Obj 指標。否則,它必須是之前的單例值之一。
如果設定了符號位元,則剩餘的低位元會儲存指向 Obj 的指標
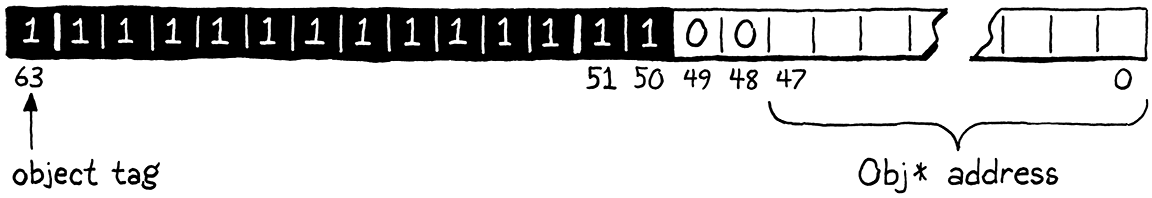
要將原始 Obj 指標轉換為 Value,我們取得指標並設定所有靜默 NaN 位元和符號位元。
#define NUMBER_VAL(num) numToValue(num)
#define OBJ_VAL(obj) \ (Value)(SIGN_BIT | QNAN | (uint64_t)(uintptr_t)(obj))
static inline double valueToNum(Value value) {
指標本身是完整的 64 位元,在原則上,因此可能會與某些靜默 NaN 和符號位元重疊。但在實務上,至少在我測試過的架構上,指標中第 48 位元以上的所有內容始終為零。這裡進行了很多類型轉換,我發現這對於滿足一些最挑剔的 C 編譯器是必要的,但最終結果只是將一些位元組合在一起。
我們定義符號位元如下
#ifdef NAN_BOXING
#define SIGN_BIT ((uint64_t)0x8000000000000000)
#define QNAN ((uint64_t)0x7ffc000000000000)
要將 Obj 指標取回,我們只需屏蔽掉所有額外的位元。
#define AS_NUMBER(value) valueToNum(value)
#define AS_OBJ(value) \ ((Obj*)(uintptr_t)((value) & ~(SIGN_BIT | QNAN)))
#define BOOL_VAL(b) ((b) ? TRUE_VAL : FALSE_VAL)
波浪符號 (~),如果你還沒有進行足夠的位元操作來遇到它,它是位元NOT。它會切換其運算元中的所有 1 和 0。透過使用靜默 NaN 和符號位元的位元反相來屏蔽值,我們清除這些位元,並讓指標位元保留。
最後一個巨集
#define IS_NUMBER(value) (((value) & QNAN) != QNAN)
#define IS_OBJ(value) \ (((value) & (QNAN | SIGN_BIT)) == (QNAN | SIGN_BIT))
#define AS_BOOL(value) ((value) == TRUE_VAL)
儲存 Obj 指標的 Value 會設定其符號位元,但任何負數也會設定。要判斷 Value 是否為 Obj 指標,我們需要檢查符號位元和所有靜默 NaN 位元是否都已設定。這與我們偵測單例值的類型的方式類似,但這次我們使用符號位元作為標籤。
30 . 3 . 6Value 函式
VM 的其餘部分在處理 Value 時通常會透過巨集,因此我們幾乎完成了。但是,「value」模組中有幾個函式會窺探 Value 這個黑盒子,並直接處理其編碼。我們也需要修正這些函式。
第一個是 printValue()。它針對每個數值類型都有單獨的程式碼。我們不再有可以切換的明確類型列舉,因此我們改為使用一系列類型測試來處理每種類型的值。
void printValue(Value value) {
在 printValue() 中
#ifdef NAN_BOXING if (IS_BOOL(value)) { printf(AS_BOOL(value) ? "true" : "false"); } else if (IS_NIL(value)) { printf("nil"); } else if (IS_NUMBER(value)) { printf("%g", AS_NUMBER(value)); } else if (IS_OBJ(value)) { printObject(value); } #else
switch (value.type) {
這在技術上比 switch 稍微慢一點,但與實際寫入資料流的開銷相比,這是可以忽略不計的。
我們仍然支援原始的標籤聯合表示法,因此我們保留舊程式碼並將其括在 #else 條件區段中。
}
在 printValue() 中
#endif
}
另一個操作是測試兩個值是否相等。
bool valuesEqual(Value a, Value b) {
在 valuesEqual() 中
#ifdef NAN_BOXING return a == b; #else
if (a.type != b.type) return false;
沒有比這更簡單的了!如果兩個位元表示相同,則值相等。這對於單例值來說是正確的,因為每個單例值都有唯一的位元表示,並且它們只與自身相等。這對於 Obj 指標來說也是正確的,因為物件使用身分進行相等性判斷—兩個 Obj 參考只有在指向完全相同的物件時才相等。
對於數字來說,它也大致正確。大多數具有不同位元表示的浮點數都是不同的數值。唉,IEEE 754 包含一個讓我們跌倒的坑洞。由於我不太清楚的原因,規格說明規定 NaN 值不等於自身。這對於我們用於自身用途的特殊靜默 NaN 來說不是問題。但有可能在 Lox 中產生「真實」的算術 NaN,而且如果我們想要正確地實作 IEEE 754 數字,那麼產生的值不應該等於自身。更具體地說
var nan = 0/0; print nan == nan;
IEEE 754 說這個程式應該印出「false」。它使用我們舊的標籤聯合表示法來做正確的事情,因為 VAL_NUMBER 的情況將 == 應用於兩個 C 編譯器知道是雙精度的值。因此,編譯器會產生正確的 CPU 指令來執行 IEEE 浮點相等性。
我們的新表示法透過將 Value 定義為 uint64_t 來打破這一點。如果我們想要完全符合 IEEE 754,我們需要處理這種情況。
#ifdef NAN_BOXING
在 valuesEqual() 中
if (IS_NUMBER(a) && IS_NUMBER(b)) { return AS_NUMBER(a) == AS_NUMBER(b); }
return a == b;
我知道,這很奇怪。而且,每次我們檢查兩個 Lox 值是否相等時,執行此類型測試都會產生效能成本。如果我們願意犧牲一點相容性—誰真的在乎 NaN 是否不等於自身?—我們可以省略這一點。我會將決定權交給你,讓你決定你想要多麼咬文嚼字。
最後,我們關閉舊實作周圍的條件編譯區段。
}
在 valuesEqual() 中
#endif
}
就是這樣。此最佳化已完成,我們的 clox 虛擬機器也已完成。這是本書中最後一行新程式碼。
30 . 3 . 7評估效能
程式碼已完成,但我們仍然需要確認這些變更是否真的帶來任何改進。評估像這樣的優化與之前的優化非常不同。之前,我們在效能分析器中看到了明顯的熱點。我們修復了程式碼的那部分,並可以立即看到熱點的執行速度加快。
變更數值表示法的影響更為分散。巨集會在使用的位置展開,因此效能變化會以許多效能分析器難以追蹤的方式散佈在整個程式碼庫中,尤其是在最佳化建置版本中。
我們也無法輕易地推論變更的效果。我們縮小了數值的大小,這減少了整個 VM 中的快取未命中。但這種變更在實際效能上的影響高度取決於正在執行的 Lox 程式的記憶體使用量。一個小的 Lox 微基準測試可能沒有足夠的數值散佈在記憶體中,導致效果不夠明顯,甚至像是 C 記憶體分配器提供給我們的位址也會影響結果。
如果我們的工作做得正確,基本上所有東西都會稍微快一點,尤其是在較大、更複雜的 Lox 程式上。但有可能我們在 NaN-boxing 數值時所做的額外位元運算會抵消更好的記憶體使用所帶來的收益。像這樣進行效能工作令人感到不安,因為您無法輕易地證明您已讓 VM 變得更好。您無法指出單一精準鎖定的微基準測試並說:「看,就是那裡?」
相反地,我們真正需要的是一套較大的基準測試套件。理想情況下,它們會從真實世界的應用程式中提煉出來—儘管對於像 Lox 這樣的玩具語言來說,這種東西並不存在。然後,我們可以測量所有這些的總體效能變化。我盡力拼湊了一些較大的 Lox 程式。在我的機器上,新的數值表示法似乎使所有東西的執行速度大致提高了 10%。
與使雜湊表查找速度加快的顯著效果相比,這並不是一個巨大的改進。我主要加入這個最佳化,因為它是您可能會遇到的一種特定類型效能工作的很好範例,而且老實說,因為我認為它在技術上非常酷。如果我真的想讓 clox 更快,這可能不是我首先會選擇的。可能還有其他更容易實現的目標。
但是,如果您發現自己正在處理一個所有簡單的優勢都已取得的程式,那麼在某些時候您可能會想調整您的數值表示法。我希望本章能讓您了解您在這方面的一些選擇。
30 . 4下一步
我們將在這裡停止對 Lox 語言和我們的兩個直譯器的研究。我們可以永遠地修補它,新增新的語言功能和巧妙的速度改進。但是,對於本書來說,我認為我們已經達到了一個可以稱之為完成工作的自然位置。我不會重新回顧我們在過去許多頁中所學的一切。您和我一起參與其中,並且您還記得。相反,我想花一點時間談談您接下來可以從哪裡開始。您在程式語言旅程中的下一步是什麼?
你們大多數人可能不會在您的職業生涯中花費大量時間在編譯器或直譯器上。這只是電腦科學學術界的一小部分,甚至在業界的軟體工程中更小。沒關係。即使您在生活中再也不會處理編譯器,您肯定會使用編譯器,並且我希望本書能讓您更了解您使用的程式語言是如何設計和實作的。
您還學習了一些重要的基本資料結構,並練習了一些低階效能分析和最佳化工作。無論您在哪個領域進行程式設計,這種專業知識都很有幫助。
我也希望我能給您一種看待和解決問題的新方法。即使您再也不會處理語言,您可能會驚訝地發現有多少程式設計問題可以被視為類似語言的形式。也許您需要編寫的報表產生器可以被建模為一系列基於堆疊的「指令」,由產生器「執行」。您需要呈現的使用者介面看起來非常像是在遍歷 AST。
如果您真的想進一步深入研究程式語言的兔子洞,這裡有一些建議,說明要探索隧道中的哪些分支
-
我們簡單的單遍位元組碼編譯器將我們推向了大部分的執行階段最佳化。在成熟的語言實作中,編譯時間最佳化通常更重要,而編譯器最佳化領域非常豐富。抓起一本經典的編譯器書籍,並重建 clox 或 jlox 的前端,使其成為具有一些有趣的中間表示形式和最佳化傳遞的複雜編譯管線。
動態類型將對您可以走多遠設置一些限制,但是您仍然可以做很多事情。或者,您可能想要邁出一大步,並將靜態類型和類型檢查器新增至 Lox。這肯定會讓您的前端有更多事情要做。
-
在本書中,我的目標是正確,但不是特別嚴格。我的目標主要是讓您對進行語言工作有直覺和感覺。如果您喜歡更精確的內容,那麼整個程式語言學術界都在等著您。自我們甚至沒有電腦之前,語言和編譯器就已經被正式研究過,因此關於剖析器理論、類型系統、語意和形式邏輯的書籍和論文不勝枚舉。走這條路也會教您如何閱讀 CS 論文,這本身就是一項寶貴的技能。
-
或者,如果您只是真的很喜歡駭客和創造語言,您可以採用 Lox 並將其變成您自己的玩物。將語法變更為讓您賞心悅目的東西。新增遺失的功能或移除您不喜歡的功能。在那裡加入新的最佳化。
最終,您可能會達到一個程度,認為您擁有的東西其他人也可以使用。這會讓您進入程式語言受歡迎程度這個非常獨特的世界。預計會花費大量時間編寫文件、範例程式、工具和有用的程式庫。該領域充斥著爭奪使用者的語言。要在這個領域蓬勃發展,您必須戴上行銷帽子並進行銷售。並非每個人都喜歡這種面向公眾的工作,但是如果您喜歡,看到人們使用您的語言來表達自己會感到非常欣慰。
或者,本書可能已經滿足了您的渴望,您將在這裡停止。無論您走哪條路,或不走哪條路,我希望在您心中銘記一個教訓。就像我一樣,您最初可能會對程式語言感到畏懼。但是在這些章節中,您已經看到,如果我們親身實作並一步一步來,即使是非常具有挑戰性的材料也可以由我們凡人來解決。如果您可以處理編譯器和直譯器,則您可以做任何您想做的事情。
挑戰
在開學最後一天布置家庭作業似乎很殘忍,但是如果您真的想在暑假期間做點事情
-
啟動您的效能分析器,執行幾個基準測試,並尋找 VM 中的其他熱點。您是否在執行階段中看到任何可以改進的東西?
-
真實世界使用者程式中的許多字串都很小,通常只有一兩個字元。在 clox 中,由於我們對字串進行了內部化處理,因此這不是什麼大問題,但是大多數 VM 則沒有。對於那些沒有這樣做的程式來說,為每個小型字串堆疊分配一個小型字元陣列,然後將該值表示為指向該陣列的指標是很浪費的。通常,指標比字串的字元還大。一個經典的技巧是為小型字串使用單獨的數值表示法,該表示法將字元內嵌儲存在數值中。
從 clox 原始的標記聯集表示法開始,實作該最佳化。編寫幾個相關的基準測試,看看是否有幫助。
-
回顧您使用本書的經驗。哪些部分對您來說效果很好?哪些部分沒有?對您來說,由下往上還是由上往下學習更容易?插圖是否有幫助或分散注意力?類比是否有助於釐清或混淆?
您越了解自己的個人學習風格,就能越有效地將知識上傳到您的腦海中。您可以專門針對以您學習的最佳方式來教導您的材料。