領域地圖
你必須要有地圖,不管多麼粗略。否則你會到處亂竄。在《魔戒》中,我從不讓任何人走超過他一天能走的路程。
J. R. R. 托爾金
我們不想到處亂竄,所以在出發之前,讓我們先掃描一下先前語言實作者所繪製的領域地圖。這將有助於我們了解我們要去哪裡以及其他人走過的替代路線。
首先,讓我建立一個簡寫。本書的大部分內容是關於語言的實作,這與某種柏拉圖式的理想形式的語言本身不同。諸如「堆疊」、「位元組碼」和「遞迴下降」之類的東西,是一個特定實作可能會使用的基本要素。從使用者的角度來看,只要最終的裝置忠實地遵循語言的規範,這一切都是實作細節。
我們將花費大量時間在這些細節上,所以如果每次提到它們時我都必須寫「語言實作」,我的手指會磨損殆盡。相反地,除非區別很重要,否則我將使用「語言」來指代語言或其一個實作,或兩者皆是。
2 . 1語言的組成部分
自電腦的黑暗時代以來,工程師們一直在建構程式語言。一旦我們可以和電腦交談,我們就發現這樣做太難了,所以我們請求它們的幫助。我發現即使今天的機器速度快了數百萬倍,並且擁有更大數量級的儲存空間,我們建構程式語言的方式實際上並沒有改變,這令人著迷。
儘管語言設計師探索的領域非常廣闊,但他們開闢的道路卻很少。並非每種語言都採用完全相同的路徑—有些語言會走一兩個捷徑—但除此之外,它們都非常相似,從葛麗絲·霍珀海軍少將的第一個 COBOL 編譯器一直到某個熱門的、新的、編譯為 JavaScript 的語言,而它的「文件」完全由某個 Git 儲存庫中一個未經編輯的 README 組成。
我將實作可能選擇的路徑網路想像成攀登一座山。你從底部開始,程式是原始的原始碼文字,實際上只是一串字元。每個階段都會分析程式並將其轉換為更高階的表示形式,在其中語義—作者希望電腦執行的動作—變得更加明顯。
最終我們到達頂峰。我們對使用者的程式一覽無遺,並且可以看到他們的程式碼意思。我們開始從山的另一側下降。我們將這個最高層次的表示形式轉換為越來越低層次的形式,以越來越接近我們知道如何讓 CPU 實際執行的東西。
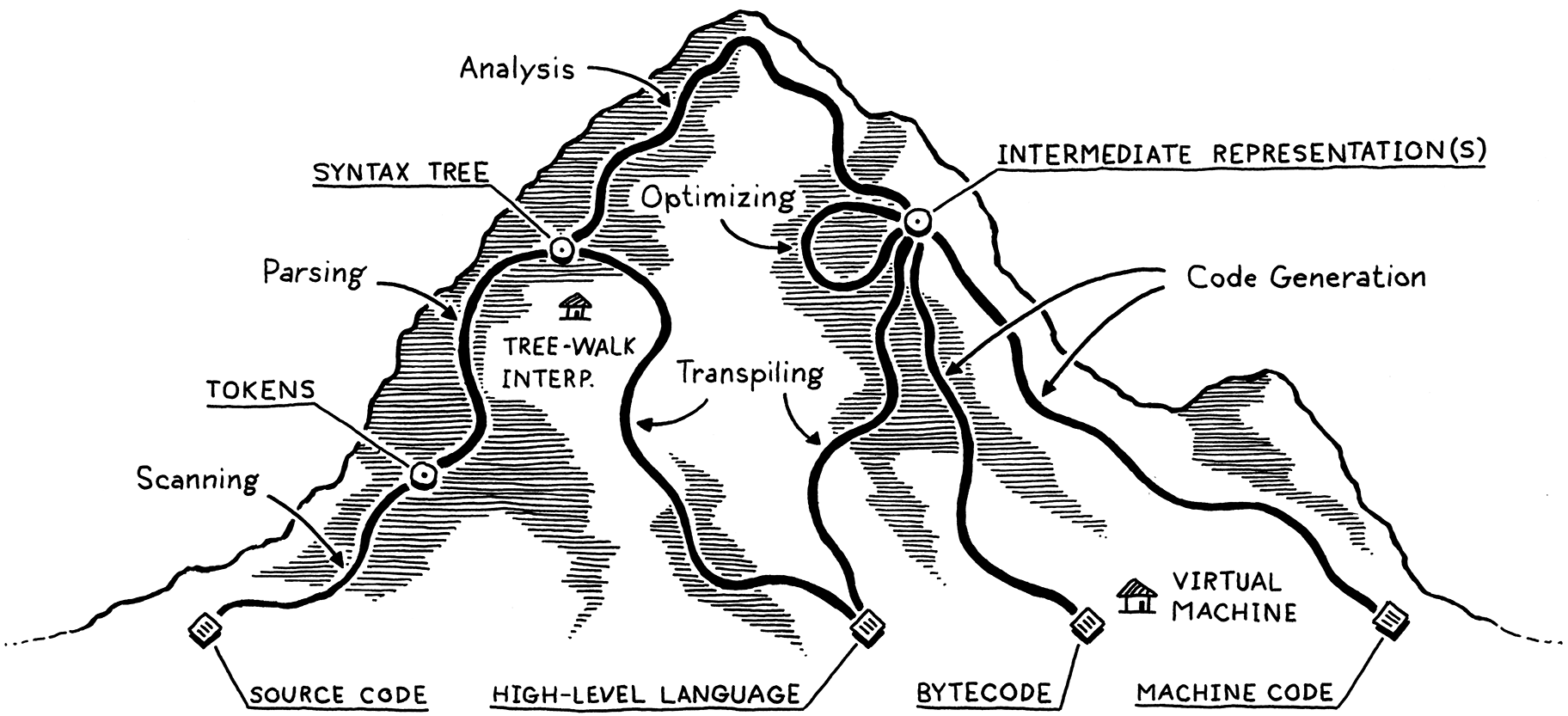
讓我們追溯一下這些路徑和興趣點。我們的旅程從左邊開始,從使用者原始碼的裸文字開始

2 . 1 . 1掃描
第一步是掃描,也稱為詞法分析,或者(如果你想給人留下深刻印象)詞彙分析。它們的意思幾乎相同。我喜歡「詞法分析」,因為它聽起來像是邪惡超級反派會做的事情,但我會使用「掃描」,因為它似乎稍微更常見。
掃描器(或詞法分析器)會接收線性的字元串流,並將它們分組為一系列更像是「單字」的東西。在程式語言中,每個單字都稱為符號。有些符號是單個字元,例如 ( 和 ,。另一些符號可能長達數個字元,例如數字 (123)、字串字面值 ("hi!") 和識別符 (min)。
原始檔中的某些字元實際上沒有任何意義。空白通常是無關緊要的,而註解,根據定義,會被語言忽略。掃描器通常會捨棄這些,留下有意義符號的清晰序列。
![[var] [average] [=] [(] [min] [+] [max] [)] [/] [2] [;]](image/a-map-of-the-territory/tokens.png)
2 . 1 . 2剖析
下一步是剖析。這是我們的語法獲得文法的地方—能夠從較小的部分組成較大的運算式和陳述式。你曾在英文課上繪製句子結構圖嗎?如果是這樣,那你做的事情和剖析器所做的事情相同,只不過英文有成千上萬的「關鍵字」和數不清的歧義。程式語言則簡單得多。
剖析器會採用扁平的符號序列,並建立一個反映文法巢狀性質的樹狀結構。這些樹有幾個不同的名稱—剖析樹或抽象語法樹—取決於它們與原始語言的裸語法結構有多接近。在實務中,語言駭客通常稱它們為語法樹、AST 或通常簡稱為樹。
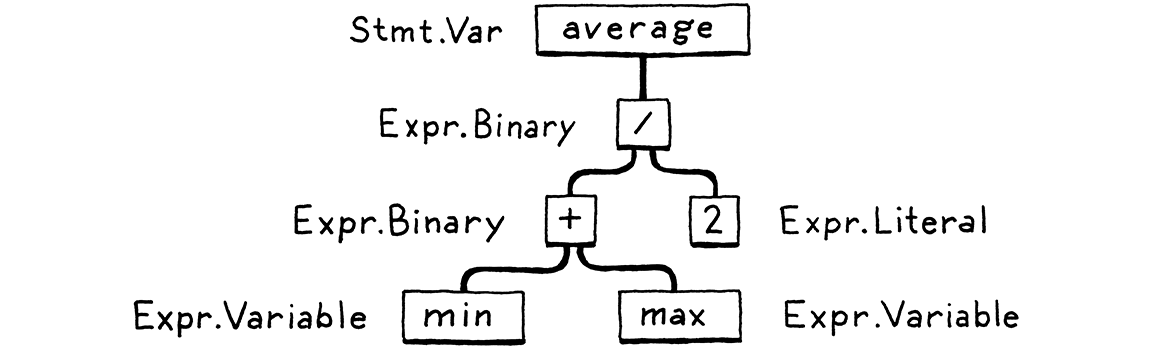
剖析在電腦科學中具有悠久而豐富的歷史,它與人工智慧社群密切相關。如今用於剖析程式語言的許多技術最初是由嘗試讓電腦與我們交談的人工智慧研究人員構思出來的,目的是為了剖析人類語言。
事實證明,人類語言對於那些剖析器可以處理的嚴格文法來說太過混亂,但它們非常適合程式語言中更簡單的人工文法。唉,我們有缺陷的人類仍然設法不正確地使用那些簡單的文法,因此剖析器的工作還包括在我們這樣做時,透過報告語法錯誤來告知我們。
2 . 1 . 3靜態分析
前兩個階段在所有實作中都非常相似。現在,每種語言的個別特性開始發揮作用。此時,我們知道程式碼的語法結構—諸如哪些運算式巢狀於哪些運算式中—但我們對此了解不多。
在像 a + b 這樣的運算式中,我們知道我們正在加 a 和 b,但我們不知道這些名稱指的是什麼。它們是局部變數嗎?全域變數?它們在哪裡定義?
大多數語言執行的第一個分析位元稱為繫結或解析。對於每個識別符,我們找出該名稱在哪裡定義,並將兩者連結在一起。這就是作用域發揮作用的地方—原始碼中可以使用特定名稱來指代特定宣告的區域。
如果語言是靜態類型的,這就是我們進行型別檢查的時候。一旦我們知道 a 和 b 在哪裡宣告,我們也可以找出它們的型別。然後,如果那些型別不支援彼此相加,我們會報告一個型別錯誤。
深呼吸。我們已經到達山頂,並且可以一覽使用者的程式。我們從分析中看到的所有這些語義見解都需要儲存在某個地方。我們可以把它們偷偷藏在幾個地方
-
通常,它會被直接儲存在語法樹上的屬性中—節點中的額外欄位,這些欄位在剖析期間不會初始化,而是在稍後填寫。
-
有時,我們可能會將資料儲存在一旁的查閱表中。通常,此表的鍵是識別符—變數和宣告的名稱。在這種情況下,我們稱它為符號表,它與每個鍵關聯的值會告訴我們該識別符指的是什麼。
-
最強大的簿記工具是將樹轉換為完全新的資料結構,以更直接地表達程式碼的語義。那是下一節的內容。
到目前為止的所有內容都被認為是實作的前端。你可能會猜到此之後的一切都是後端,但不是。在過去「前端」和「後端」被創造出來的日子裡,編譯器簡單得多。後來的研究人員發明了新的階段來填充這兩個部分之間。威廉·伍爾夫及其同伴沒有捨棄舊術語,而是將這些新階段歸類為迷人但空間上自相矛盾的名稱中端。
2 . 1 . 4中間表示
你可以將編譯器視為一個管線,其中每個階段的工作都是以一種使下一個階段更容易實作的方式來組織表示使用者程式碼的資料。管線的前端特定於編寫程式的原始語言。後端關心程式將在其上執行的最終架構。
在中間,程式碼可以儲存在某種中間表示 (IR) 中,該中間表示與原始形式或目標形式都沒有緊密關聯(因此稱為「中間」)。相反,IR 充當這兩種語言之間的介面。
這可以讓你更輕鬆地支援多種原始語言和目標平台。假設你想實作 Pascal、C 和 Fortran 編譯器,並且你想以 x86、ARM 和我不知道 SPARC 為目標。正常情況下,這意味著你要簽約編寫九個完整的編譯器:Pascal→x86、C→ARM 以及其他所有組合。
一個共享的中間表示可以大幅減少這種情況。你為每個產生 IR 的原始語言編寫一個前端。然後為每個目標架構編寫一個後端。現在你可以混合和匹配它們以獲得每個組合。
我們可能想要將程式碼轉換為使語義更明顯的形式還有另一個主要原因 . . .
2 . 1 . 5最佳化
一旦我們了解使用者的程式碼意思,我們就可以自由地將其換成具有相同語義但執行效率更高的不同程式碼—我們可以對其進行最佳化。
一個簡單的例子是常數摺疊:如果某些表達式總是計算出完全相同的值,我們可以在編譯時進行計算,並用其結果替換表達式的程式碼。如果使用者輸入了這個
pennyArea = 3.14159 * (0.75 / 2) * (0.75 / 2);
我們可以在編譯器中完成所有算術運算,並將程式碼更改為
pennyArea = 0.4417860938;
最佳化是程式語言業務中非常重要的一部分。許多語言駭客將他們整個職業生涯都投入在這裡,從他們的編譯器中榨取每一滴效能,以使他們的基準測試速度提高百分之幾。它可能會變成一種癡迷。
在這本書中,我們主要會跳過那個無底洞。許多成功的語言只有非常少的編譯時最佳化。例如,Lua 和 CPython 生成相對未最佳化的程式碼,並將大部分效能精力集中在執行期。
2 . 1 . 6程式碼產生
我們已經對使用者程式應用了我們能想到的所有最佳化。最後一步是將其轉換為機器可以實際執行的形式。換句話說,就是產生程式碼(或程式碼產生),這裡的「程式碼」通常指的是 CPU 執行的原始組合語言指令,而不是人類可能想讀的那種「原始碼」。
最後,我們來到了後端,正從山脈的另一側向下走。從這裡開始,我們對程式碼的表示會越來越原始,就像逆向運行的演化一樣,因為我們越來越接近我們頭腦簡單的機器可以理解的東西。
我們需要做出決定。我們要為真正的 CPU 還是虛擬 CPU 生成指令?如果我們生成真正的機器碼,我們會得到一個作業系統可以直接載入到晶片的執行檔。原生碼速度快如閃電,但生成它需要大量的工作。今天的架構擁有大量的指令、複雜的管線,以及足夠多的歷史包袱來填滿一架 747 的行李艙。
說晶片的語言也意味著你的編譯器與特定的架構綁定。如果你的編譯器以 x86 機器碼為目標,它將無法在 ARM 裝置上執行。早在 60 年代,在電腦架構的寒武紀大爆發期間,這種缺乏可攜性的問題是一個真正的障礙。
為了繞過這個問題,像 Martin Richards 和 Niklaus Wirth(分別來自 BCPL 和 Pascal)這樣的駭客讓他們的編譯器產生虛擬機器碼。他們不是針對某些真正的晶片生成指令,而是針對假設的理想化機器生成程式碼。Wirth 將其稱為 p-code,表示 可攜式,但今天,我們通常稱之為 位元組碼,因為每個指令通常只有一個位元組長。
這些合成指令旨在更貼近語言的語意,而不受任何一個電腦架構及其累積的歷史缺陷所束縛。你可以將其視為語言底層運算的密集二進位編碼。
2 . 1 . 7虛擬機器
如果你的編譯器產生位元組碼,那麼一旦完成,你的工作還沒有結束。由於沒有晶片可以說這種位元組碼,因此翻譯是你的工作。同樣,你有兩個選擇。你可以為每個目標架構編寫一個小型編譯器,將位元組碼轉換為該機器的原生碼。你仍然需要為你支援的每個晶片工作,但最後階段非常簡單,而且你可以重複使用你支援的所有機器上的其餘編譯器管線。你基本上將你的位元組碼用作中間表示法。
或者,你可以編寫一個虛擬機器(VM),這是一個程式,可以在執行期模擬支援你的虛擬架構的假設晶片。在 VM 中執行位元組碼比提前將其轉換為原生碼要慢,因為每次執行時都必須在執行期模擬每個指令。作為回報,你可以獲得簡單性和可攜性。以 C 語言實作你的 VM,你就可以在任何有 C 編譯器的平台上執行你的語言。這就是我們在這本書中建構的第二個解譯器的工作方式。
2 . 1 . 8執行期
我們終於將使用者的程式碼轉換為我們可以執行的形式。最後一步是執行它。如果我們將其編譯為機器碼,我們只需告訴作業系統載入執行檔並開始執行。如果我們將其編譯為位元組碼,我們需要啟動 VM 並將程式載入其中。
在這兩種情況下,對於所有但最基礎的底層語言,我們通常需要我們的語言在程式執行時提供的一些服務。例如,如果語言自動管理記憶體,我們需要一個垃圾收集器來回收未使用的位元。如果我們的語言支援「instance of」測試,以便你可以查看你擁有哪種物件,那麼我們需要一些表示法來追蹤執行期間每個物件的類型。
所有這些東西都在執行期進行,所以它被稱為執行期。在完全編譯的語言中,實作執行期的程式碼會直接插入到結果的執行檔中。例如,在 Go 中,每個編譯的應用程式都有其自己的 Go 執行期副本直接嵌入其中。如果語言在解譯器或 VM 內部執行,那麼執行期就在那裡。這就是大多數 Java、Python 和 JavaScript 等語言的實作方式。
2 . 2捷徑和替代路線
這條漫長的道路涵蓋了你可能實作的每個可能階段。許多語言確實走完整個路線,但也有一些捷徑和替代路徑。
2 . 2 . 1單遍編譯器
一些簡單的編譯器會交錯解析、分析和程式碼產生,以便它們直接在解析器中產生輸出程式碼,而無需配置任何語法樹或其他 IR。這些單遍編譯器限制了語言的設計。你沒有中間資料結構來儲存有關程式的全域資訊,而且你不會重新訪問任何先前解析的程式碼部分。這意味著一旦你看到某些表達式,你就需要知道足夠的資訊才能正確編譯它。
Pascal 和 C 就是圍繞這個限制而設計的。當時,記憶體非常寶貴,以至於編譯器可能甚至無法將整個原始檔保存在記憶體中,更不用說整個程式了。這就是為什麼 Pascal 的語法要求型別宣告必須首先出現在區塊中的原因。這就是為什麼在 C 中,除非你有明確的前向宣告告訴編譯器它需要知道什麼才能為對後續函式的呼叫產生程式碼,否則你不能在定義它的程式碼上方呼叫函式。
2 . 2 . 2樹狀走訪解譯器
某些程式語言在將程式碼解析為 AST(可能應用了一些靜態分析)後立即開始執行程式碼。為了執行程式,解譯器會一次走訪語法樹的一個分支和一個葉子,並在執行過程中評估每個節點。
這種實作樣式在學生專案和小語言中很常見,但不廣泛用於通用語言,因為它往往很慢。有些人使用「解譯器」僅表示這些類型的實作,但其他人對這個詞的定義更廣泛,因此我將使用無可爭辯的明確的樹狀走訪解譯器來指代這些。我們的第一個解譯器就是這樣運作的。
2 . 2 . 3轉譯器
為語言編寫完整的後端可能需要大量的工作。如果你有一些現有的通用 IR 可供目標,你可以將你的前端連接到該 IR。否則,你似乎陷入困境。但是,如果你將其他原始語言視為中間表示法,會怎麼樣?
你為你的程式語言撰寫一個前端。然後,在後端,你不是費盡心思地將語義「降級」到某個原始的目標語言,而是為另一個與你的語言層次相當的高階語言產生有效的原始碼字串。接著,你使用該語言現有的編譯工具,作為你從山上逃脫並到達可以執行的東西的途徑。
他們過去稱之為源碼到源碼編譯器或轉譯編譯器。在為了在瀏覽器中執行而編譯成 JavaScript 的語言興起後,它們受到了時髦的稱號轉譯器。
雖然第一個轉譯器將一種組合語言翻譯成另一種,但今天,大多數轉譯器處理的是更高階的語言。在 UNIX 病毒式傳播到各種機器之後,開始了一種長期的傳統,即編譯器產生 C 作為其輸出語言。C 編譯器在 UNIX 隨處可見,並產生高效的程式碼,因此以 C 為目標是在許多架構上運行您的語言的好方法。
網路瀏覽器是今天的「機器」,而它們的「機器碼」是 JavaScript,所以現在看起來幾乎每一種語言都有一個以 JS 為目標的編譯器,因為這是讓你的程式碼在瀏覽器中執行的主要方式。
轉譯器的前端—掃描器和剖析器—看起來像其他編譯器。然後,如果來源語言只是目標語言的簡單語法外觀,它可以完全跳過分析,直接輸出目標語言中類似的語法。
如果兩種語言在語義上更為不同,你會看到完整編譯器更典型的階段,包括分析,甚至可能包括最佳化。然後,當涉及到程式碼產生時,不是輸出像機器碼這樣的二進制語言,而是產生目標語言中語法正確的來源(嗯,目的地)程式碼字串。
無論哪種方式,你接下來都會透過輸出語言現有的編譯管道運行產生的程式碼,這樣就完成了。
2 . 2 . 4即時編譯
最後這個方法比較不是捷徑,而是一種最好留給專家的危險高山攀登。執行程式碼最快的方法是將其編譯成機器碼,但你可能不知道你的終端使用者機器支援哪種架構。該怎麼辦?
你可以做 HotSpot Java 虛擬機器(JVM)、Microsoft 的通用語言執行平台(CLR)和大多數 JavaScript 解譯器所做的事情。在終端使用者的機器上,當程式載入時—對於 JS 而言是來源程式碼,對於 JVM 和 CLR 而言是與平台無關的位元組碼—你會將其編譯為其電腦支援的架構的原生程式碼。當然,這就叫做即時編譯。大多數駭客簡稱為「JIT」,發音類似「fit」。
最複雜的 JIT 會將效能分析掛勾插入產生的程式碼中,以查看哪些區域的效能最關鍵以及哪些類型的資料在其中流動。然後,隨著時間的推移,它們會自動重新編譯這些熱點,進行更進階的最佳化。
2 . 3編譯器與解譯器
既然我已經用相當於一本字典的程式語言術語塞滿了你的腦袋,我們終於可以解決一個自古以來困擾著程式設計師的問題:編譯器和解譯器之間有什麼區別?
結果發現這就像問水果和蔬菜之間的區別。這似乎是一個非此即彼的二元選擇,但實際上「水果」是一個植物學術語,而「蔬菜」是一個烹飪術語。一個並不嚴格地意味著另一個的否定。有些水果不是蔬菜(蘋果),有些蔬菜不是水果(胡蘿蔔),但也有既是水果又是蔬菜的可食用植物,例如番茄。
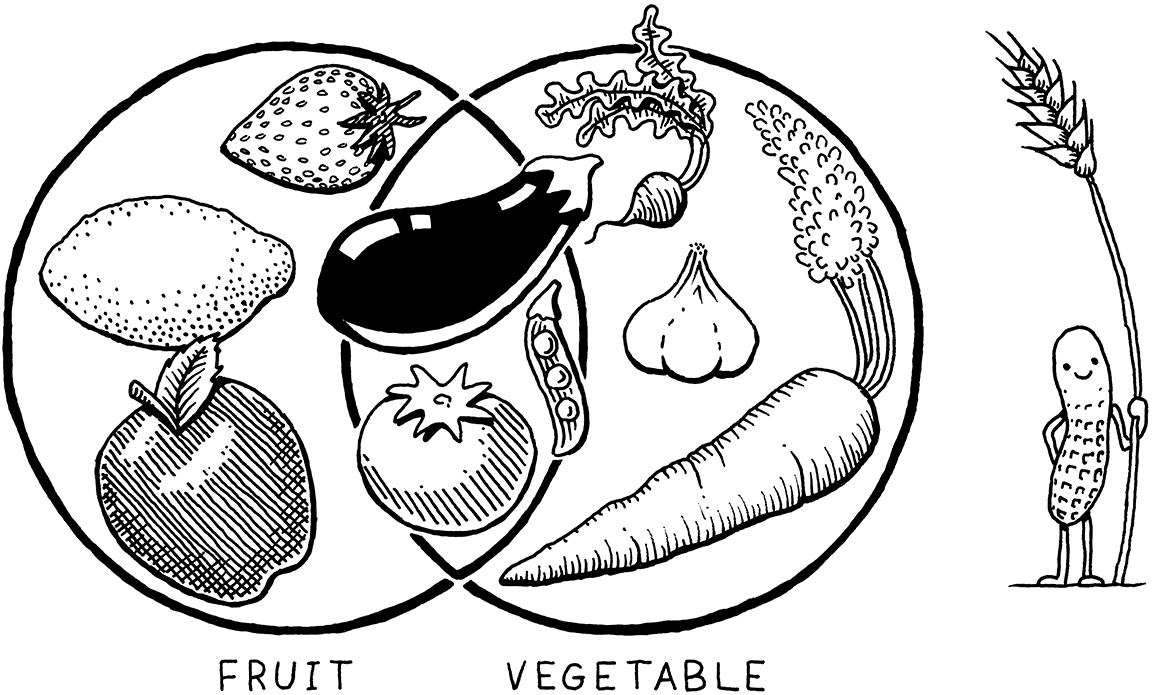
所以,回到程式語言
-
編譯是一種實作技術,涉及將來源語言翻譯成另一種形式—通常是較低階的形式—。當你產生位元組碼或機器碼時,你正在編譯。當你轉譯到另一種高階語言時,你也正在編譯。
-
當我們說一個語言實作「是編譯器」時,我們的意思是它將原始碼翻譯成某種其他形式,但不執行它。使用者必須取得產生的輸出並自行執行。
-
相反地,當我們說一個實作「是解譯器」時,我們的意思是它會接收原始碼並立即執行它。它「從原始碼」執行程式。
就像蘋果和橘子一樣,有些實作顯然是編譯器,而不是解譯器。GCC 和 Clang 會取得你的 C 程式碼並將其編譯為機器碼。終端使用者直接執行該可執行檔,甚至可能不知道是使用哪個工具進行編譯的。因此,這些都是 C 的編譯器。
在 Matz 的 Ruby 典型實作的舊版本中,使用者從原始碼執行 Ruby。該實作會剖析它,並透過遍歷語法樹直接執行它。沒有發生其他翻譯,無論是在內部還是在任何使用者可見的形式中。所以這絕對是 Ruby 的解譯器。
但是 CPython 呢?當你使用它執行你的 Python 程式時,程式碼會被剖析並轉換為內部位元組碼格式,然後在 VM 內執行。從使用者的角度來看,這顯然是一個解譯器—他們從原始碼執行他們的程式。但是,如果你看看 CPython 的外殼下,你會發現肯定有一些編譯正在進行。
答案是它兩者都是。CPython 是一個解譯器,並且它有一個編譯器。實際上,大多數指令碼語言都是這樣運作的,你可以看到
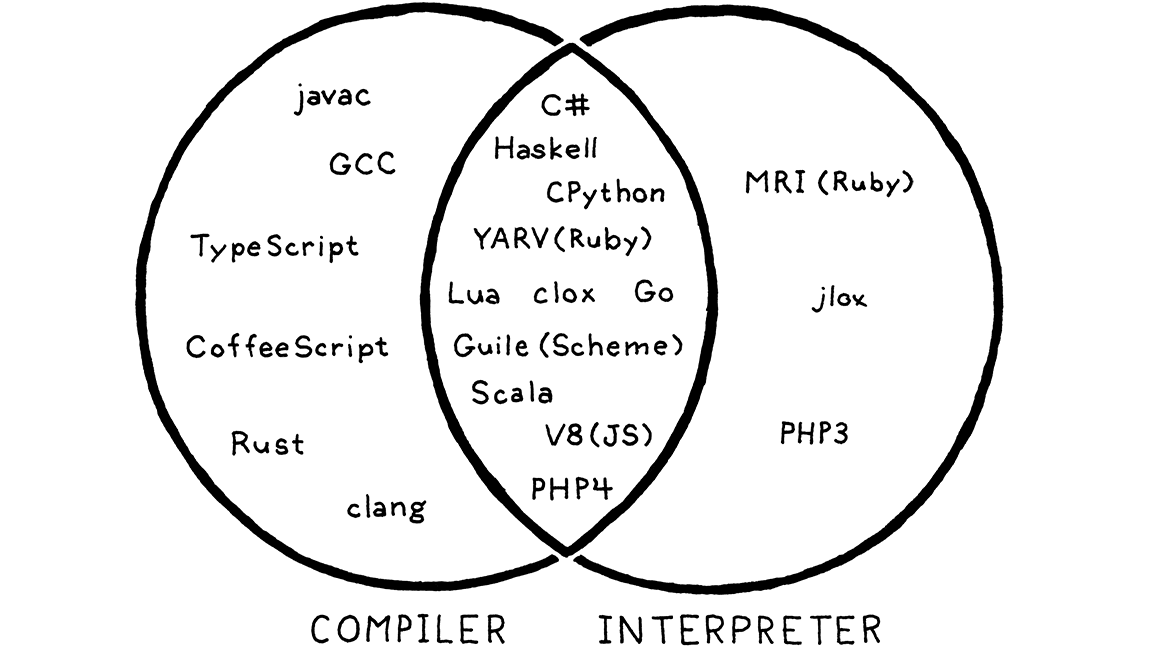
中心重疊的區域也是我們第二個解譯器所在的位置,因為它在內部編譯為位元組碼。因此,雖然本書名義上是關於解譯器的,但我們也會介紹一些編譯。
2 . 4我們的旅程
一下子要吸收這麼多資訊。別擔心。這不是期望你理解所有這些部分和組件的章節。我只是想讓你知道它們存在,以及它們大致是如何組合在一起的。
當你探索本書中引導路徑之外的領域時,這張地圖應該對你很有幫助。我希望讓你渴望獨自出發,在山上四處遊蕩。
但是,現在,是時候開始我們自己的旅程了。繫緊你的鞋帶,束緊你的背包,一起來吧。從這裡開始,你只需要專注於你面前的路。
挑戰
-
選擇一個你喜歡的語言的開源實作。下載原始碼並在其中探索。嘗試找到實作掃描器和剖析器的程式碼。它們是手寫的,還是使用 Lex 和 Yacc 等工具產生的?(
.l或.y檔案通常表示後者。) -
即時編譯往往是實作動態類型語言的最快方法,但並非所有語言都使用它。有什麼理由不使用 JIT 呢?
-
大多數編譯成 C 的 Lisp 實作也包含一個解譯器,使其也可以即時執行 Lisp 程式碼。為什麼?